上一篇
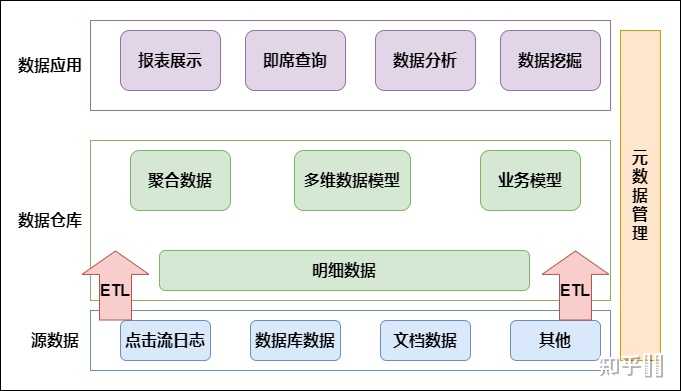
hadoop数据仓库和数据库
Hadoop数据仓库基于分布式存储(HDFS),擅长批量处理非结构化/半结构化 数据,成本低、扩展灵活;传统数据库采用集中式架构,支持ACID事务和实时查询,适用于结构化数据管理,但扩展成本较高,两者在数据类型、处理模式及应用场景上形成
Hadoop数据仓库与数据库的核心解析
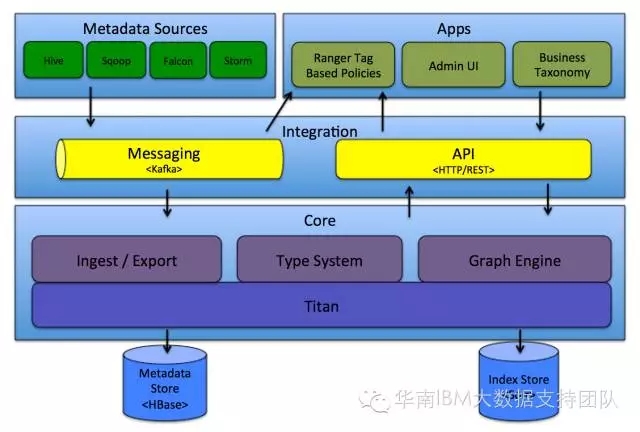
Hadoop生态系统
Hadoop作为开源分布式计算框架,其核心由HDFS(分布式文件系统)、YARN(资源调度)和MapReduce(计算模型)组成,在此生态基础上,衍生出两种重要数据管理工具:Hadoop数据仓库(如Hive、Impala)和Hadoop数据库(如HBase、Kudu),二者均针对海量数据处理需求设计,但在架构理念、数据模型和应用场景上存在显著差异。
Hadoop数据仓库特性分析
| 特性 | Hive | Impala | 传统数据仓库(如Teradata) |
|---|---|---|---|
| 数据模型 | 类SQL表(基于文件) | 同Hive | 严格关系型表 |
| 存储格式 | Text/ORC/Parquet | 同Hive | 专有存储引擎 |
| 查询延迟 | 分钟级(批处理) | 秒级(内存计算) | 亚秒级(MPP架构) |
| 扩展性 | 横向扩展(依赖HDFS) | 横向扩展(独立进程) | 纵向扩展(硬件升级) |
| 事务支持 | 无ACID事务 | 无 | 完整ACID支持 |
| 典型场景 | 离线分析、ETL | 实时交互式查询 | 企业级BI、复杂OLAP |
Hive核心优势:
- 兼容SQL语法(HiveQL),降低学习成本
- 直接操作HDFS数据,避免数据迁移
- 支持ORC/Parquet列式存储优化查询
典型应用:日志分析、用户行为建模、批量数据清洗
Hadoop数据库技术对比
| 维度 | HBase | Kudu | 传统关系数据库(如MySQL) |
|---|---|---|---|
| 数据模型 | Key-Value(宽表) | 列式存储+增量更新 | 规范化二维表 |
| 写入性能 | 毫秒级(LSM树) | 毫秒级(混合存储引擎) | 受事务日志限制 |
| 查询类型 | 单行随机读写 | 支持时间范围查询 | 复杂多表关联 |
| 存储结构 | WAL+MemStore+HFile | 列式存储+行式更新 | 行式存储+B+Tree索引 |
| 一致性保障 | 最终一致性 | 恰好一次语义 | ACID事务 |
| 最佳场景 | 实时计费、用户画像更新 | 时序数据分析 | OLTP交易处理 |
HBase关键技术:
- 基于LSM树的写优化架构
- RegionServer自动分片机制
- 支持RowKey自定义散列策略
Kudu创新点: - 混合存储引擎(列式存储+行式更新)
- 支持精确一次写入语义
- 时间范围高效查询能力
核心差异对比表
| 对比维度 | Hadoop数据仓库(Hive) | Hadoop数据库(HBase) | 传统数据库 |
|---|---|---|---|
| 数据访问模式 | 批量处理 | 随机读写 | 混合模式 |
| 数据新鲜度 | 小时级(依赖调度) | 实时 | 实时(事务隔离) |
| Schema灵活性 | 宽表支持(SerDe扩展) | 动态列(无预定义) | 严格Schema约束 |
| 硬件成本 | 廉价PC集群 | 中等(需SSD优化) | 高端专用设备 |
| 开发复杂度 | SQL兼容(较低) | API驱动(较高) | SQL标准化(低) |
典型应用场景矩阵
| 需求类型 | 推荐方案 | 不推荐方案 |
|---|---|---|
| TB级日志分析 | Hive+ORC | HBase(扫描效率低) |
| 实时用户画像更新 | HBase+Phoenix | Hive(延迟过高) |
| 复杂多维分析 | Impala+Kudu | 传统数据库(扩展性差) |
| 历史数据归档 | HDFS+Hive分区表 | HBase(存储成本高) |
| 混合负载场景 | Hive+HBase+Spark组合架构 | 单一技术栈 |
技术选型建议
数据规模:
- <10TB:传统数据库/HBase单机
- 10TB-PB级:Hive+HDFS集群
-
PB级:混合架构(Hive+HBase+Kudu)
延迟要求:
- 实时查询:HBase+Redis缓存
- 分钟级分析:Impala+Parquet
- 小时级报表:Hive+ORC
成本控制:
- 冷数据存储:HDFS+Hive压缩格式
- 热数据访问:HBase+闪存部署
- 混合存储:Ceph+Kudu列存
FAQs常见问题解答
Q1:Hive与HBase能否协同工作?如何实现?
A1:可以协同,典型场景为:
- HBase存储实时变更数据(如用户画像)
- Hive定期抽取HBase数据生成分析宽表
- Sqoop导入HBase数据到Hive分区表
- Phoenix提供SQL接口连接HBase数据
Q2:Kudu相比HBase的主要优势是什么?
A2:核心优势包括:
- 支持精确一次写入语义(HBase仅最终一致)
- 列式存储优化分析查询(HBase行式存储)
- 原生支持时间范围查询(HBase需二级索引)
- 更低的CPU消耗(向量化执行引擎)
适用场景:时序数据分析、流批一体处理、准实时