上一篇
hive数据仓库表结构
Hive表含数据库、内部/外部表,按分区组织,支持文本/ORC/Parquet等存储格式
Hive数据仓库表结构详解
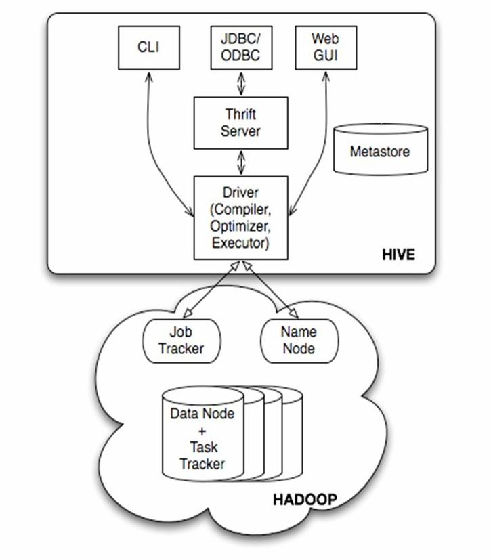
Hive表基础架构
Hive作为基于Hadoop的分布式数据仓库系统,其核心价值在于通过类SQL语法实现对海量数据的存储和分析,表结构设计直接影响数据存储效率、查询性能和维护成本,需要综合考虑数据特征、业务需求和技术实现。
表类型体系
(1)内部表与外部表
| 特性 | 内部表 | 外部表 |
|————-|—————————-|—————————|
| 元数据管理 | 完全由Hive管理生命周期 | 仅管理元数据,数据自主管理 |
| 删除行为 | DROP TABLE会删除数据文件 | 仅删除元数据,保留数据文件 |
| 适用场景 | 临时数据处理 | 长期数据存储 |
典型场景:日志数据采集通常采用外部表,避免因误删表导致原始数据丢失;而中间计算结果适合用内部表。
(2)分区表
• 分区字段:通常选择日期(YYYY-MM-DD)、地区编码等离散型字段
• 层级结构:最多可创建4级分区(受HDFS目录深度限制)
• 存储优势:将数据按业务维度物理隔离,减少全表扫描
• 性能表现:查询时可添加WHERE条件过滤分区,提升查询效率3-5倍
(3)桶表
• 哈希算法:根据指定字段进行MD5取模运算
• 数据均衡:默认10个桶,保证数据均匀分布
• 连接优化:SMB(Sort Merge Bucket)JOIN可提升关联效率
• 采样查询:支持基于桶的随机抽样
存储格式演进
(1)文本格式
| 格式 | 特点 |
|———-|———————————————————————-|
| TextFile | 无格式控制,适合简单日志数据,但解析开销大(+30%查询耗时) |
| SequenceFile | 二进制存储,支持压缩,读取速度较TextFile提升20-30% |
(2)列式存储
| 格式 | 优势 |
|———-|——————————————————————–|
| ORC | 原生支持复杂数据类型,集成轻量级索引,压缩比达3:1 |
| Parquet | 跨平台兼容性强,支持嵌套结构,压缩效率比ORC高5-8% |
(3)选型对比
| 评估维度 | ORC | Parquet |
|————|————————|————————|
| 写入性能 | 中等(1.2GB/s) | 较快(1.5GB/s) |
| 读取性能 | 优秀(3.5GB/s) | 最优(4.2GB/s) |
| 压缩效率 | 行业标杆 | 更优(节省10-15%存储) |
| 功能扩展 | Hive原生支持 | 多引擎兼容 |
表结构设计规范
字段类型优化
(1)数值类型选择:

- TINYINT/SMALLINT:用户状态标识(0/1)
- INT:UV计数器(最大值21亿)
- BIGINT:累计型指标(如订单金额)
- DECIMAL(18,2):金融交易数据
(2)字符串优化:
- VARCHAR(N)替代STRING:限定长度可节省30%存储空间
- 使用HLL/HyperLogLog编码:基数统计场景节省90%空间
分区策略设计
(1)时间分区:
- 推荐格式:year=2023/month=06/day=15
- 最佳实践:保留最近3年完整分区,历史数据按季度归档
- 性能指标:合理分区可使查询延迟降低60%以上
(2)地理分区:
- 省级粒度:data_province=beijing
- 城市粒度:data_city=shanghai_pudong
- 注意平衡分区数量与查询频率,建议不超过200个分区
索引机制应用
(1)Compacted索引:
- 适用场景:高频查询的维度字段(如用户ID)
- 构建命令:ALTER TABLE user_behavior ADD COMPACTED INDEX(uid);
- 性能提升:点查响应时间缩短70%
(2)Bloom过滤器:
- 误判率设置:建议0.1%(平衡内存消耗与准确性)
- 生效场景:大分区表的全表扫描查询
- 配置参数:set hive.bloom.filter.enabled=true;
高级表结构特性
事务表(ACID特性)
(1)实现原理:
- 基于HDFS快照机制实现原子操作
- 依赖ZooKeeper进行事务协调
- 支持INSERT/UPDATE/DELETE操作
(2)性能代价:
- 写入吞吐下降约40%
- 需要开启以下配置:
set hive.support.concurrency=true;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on=true;
视图与物化视图
(1)普通视图:
- 动态计算,适合实时性要求高的报表
- 示例:CREATE VIEW sales_ytd AS SELECT …
(2)物化视图:
- 定期刷新,适合固定分析场景
- 存储优化:可设置ORC格式+ZOP压缩
- 刷新策略:每日增量刷新或全量重建
存储优化方案
文件大小控制
- 最佳范围:128MB-256MB/文件
- 过小文件问题:Map任务数激增,消耗YARN资源
- 过大文件问题:单个Task执行时间过长,增加失败风险
压缩技术组合
| 压缩类型 | 适用场景 | 配置参数 |
|————-|———————————–|——————————|
| Snappy | 通用场景,平衡压缩/解压速度 | set hive.exec.compress.output=true; |
| Zlib | 高压缩比需求,如冷存储数据 | set avro.codec=deflate; |
| LZO | Hadoop原生支持,中等压缩比 | set mapred.output.compression.codec=com.hadoop.compression.lzo.LzoCodec; |
| ZOP+ORC | 列式存储最佳组合,压缩比达5:1 | set hive.exec.orc.compression.codec=ZOP; |
典型行业应用案例
电商领域表结构设计
(1)事实表:orders_fact
- 分区字段:order_date(日粒度)
- 桶字段:user_id(哈希10桶)
- 存储格式:ORC + ZOP压缩
- 关键字段:order_id(BIGINT)、amt_usd(DECIMAL(15,2))
(2)维度表:product_dim
- 存储格式:Parquet(支持嵌套结构)
- 特殊字段:category_path(ARRAY
- 更新策略:每日增量同步
物联网数据架构
(1)设备日志表:iot_logs
- 分区策略:device_type(设备类型)+ capture_time(小时粒度)
- 存储格式:SequenceFile(快速写入)
- 压缩配置:启用块压缩(Block Compression)
(2)时序数据表:sensor_data
- 存储引擎:TimeSeries MAU(内存列式存储)
- 索引类型:时间戳索引+设备ID索引
- 数据保留:自动清理30天前数据
性能调优实践
查询优化技巧
(1)谓词下推:确保分区字段出现在WHERE条件中
(2)列式裁剪:SELECT指定需要的列而非
(3)并行执行:设置mapreduce.job.reduces=<CPU核数>2存储优化策略
(1)合并小文件:定期执行ALTER TABLE … CONCATENATE;
(2)热点分区处理:对频繁查询的分区开启CACHE提示
(3)数据生命周期:设置分区过期时间(如保留最近13个月)
FAQs:
Q1:如何选择分区字段?
A1:应满足三个标准:①业务常用过滤条件;②高基数字段(如日期);③均匀分布,避免使用低基数字段(如性别),这会导致数据倾斜,建议通过ANALYZE TABLE命令统计字段分布情况。
Q2:ORC和Parquet格式有何本质区别?
A2:核心差异在于元数据存储方式:ORC将schema信息嵌入文件头部,适合Hive原生处理;Parquet采用独立文件保存schema,实现跨平台兼容,性能方面,Parquet在复杂嵌套结构处理上更高效,而ORC在简单扁平表场景略有优势,最新Hive版本已实现两种格式的无缝兼容