上一篇
hive数据仓库是数据库吗
Hive是基于Hadoop的数据仓库工具,提供类SQL查询,用于大数据分析,虽具备数据库特性但非传统
Hive数据仓库与数据库的核心区别解析
基础概念定义
| 对比维度 | 传统数据库(如MySQL、PostgreSQL) | Hive数据仓库 |
|---|---|---|
| 设计目标 | 支持OLTP(在线事务处理),侧重高并发读写、低延迟 | 支持OLAP(在线分析处理),侧重大规模数据批处理与复杂分析查询 |
| 数据模型 | 结构化数据为主,严格Schema约束(二维表结构) | 半结构化/非结构化数据兼容,Schema灵活(基于文件系统,支持JSON、CSV等格式) |
| 存储层 | 行式存储(按记录存储) | 列式存储(按字段存储,压缩优化分析查询) |
| 事务支持 | ACID特性(原子性、一致性、隔离性、持久性) | 最终一致性,无事务机制(依赖HDFS的原子性操作) |
| 扩展方式 | 纵向扩展(依赖硬件升级) | 横向扩展(通过增加节点实现PB级数据存储) |
| 延迟 | 毫秒级(支持实时操作) | 分钟级(适合离线分析) |
| 典型场景 | 金融交易、电商订单、实时日志等 | 用户行为分析、日志处理、数据仓库ETL、机器学习数据集预处理 |
Hive的本质属性
架构定位
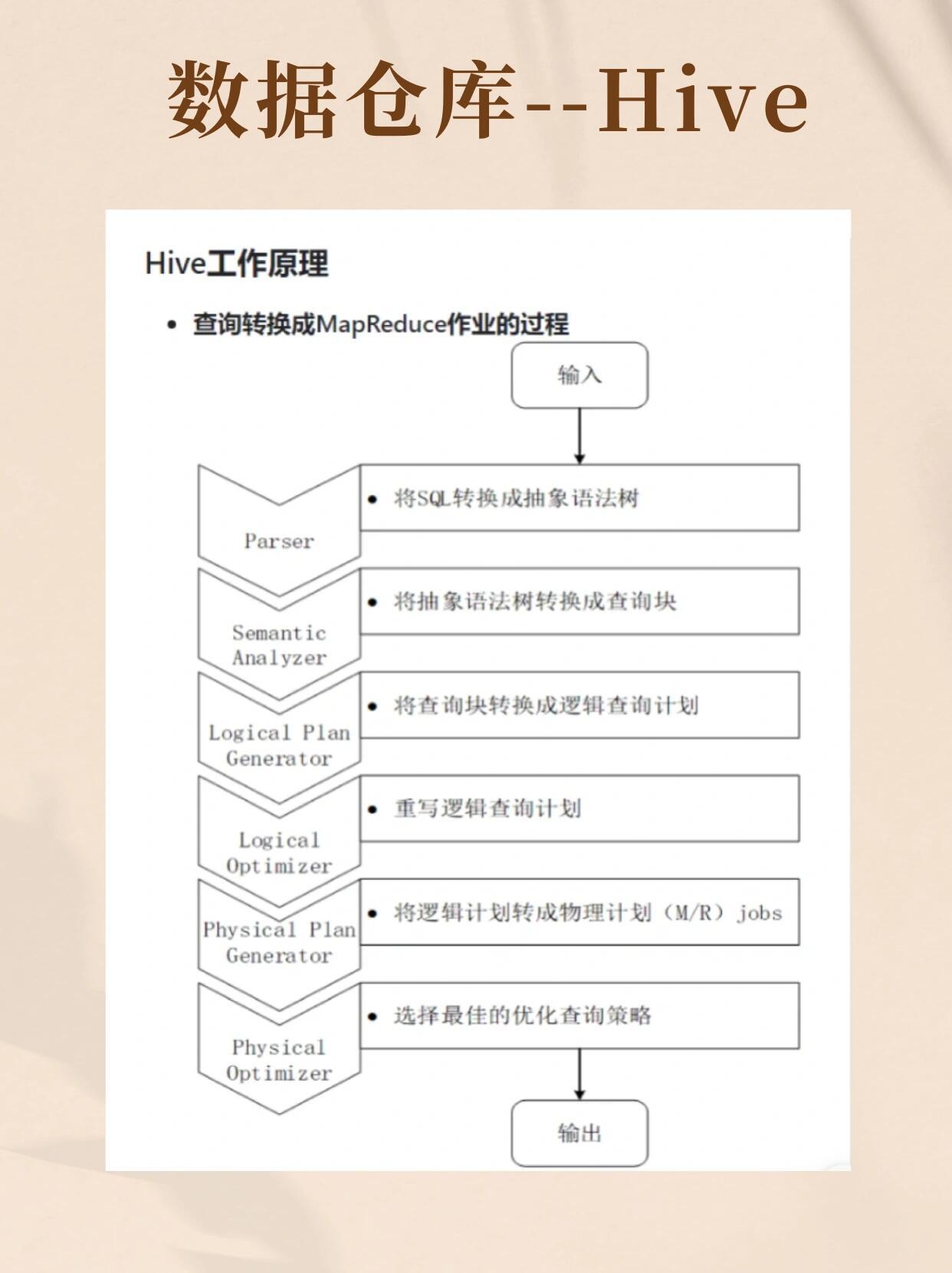
Hive是构建在Hadoop生态中的数据仓库工具,而非传统关系型数据库,其核心功能是将SQL类查询(HiveQL)转换为MapReduce任务,通过分布式计算处理海量数据。存储与计算分离
- 数据存储:依赖HDFS(Hadoop分布式文件系统),以文本、SequenceFile、ORC等格式存储原始数据。
- 元数据管理:使用关系型数据库(如MySQL)存储表结构、分区、权限等信息。
- 计算引擎:直接调用YARN资源或Tez/Spark优化执行路径,无独立计算存储模块。
SQL兼容性
HiveQL语法与标准SQL相似,但存在关键差异:
- 不支持更新/删除操作(仅支持INSERT OVERWRITE)
- 无索引机制,依赖分区和分桶优化查询
- 内置函数偏向数据分析(如窗口函数、UDF扩展)
为何Hive属于数据仓库范畴?
数据仓库的核心特征可通过以下维度验证:
| 数据仓库特征 | Hive实现方式 |
|---|---|
| 面向主题的集成数据 | 通过外部表支持多源数据加载,可集成HDFS、HBase、JDBC数据源 |
| 不可更新性(Write-Once) | 数据写入后不可修改,需通过覆盖或新增分区实现”更新” |
| 时间一致性 | 默认采用”快照”模式,支持时间旅行(查询历史数据版本) |
| 大规模分析优化 | 列式存储(ORC/Parquet)、分区剪裁、谓词下推等技术提升查询效率 |
| Schema-On-Read | 允许延迟定义Schema(如JSON数据自动推断字段类型) |
与数据库的深度对比
事务处理能力
- 传统数据库:支持行级锁、MVCC实现多用户并发修改
- Hive:仅支持”插入”和”覆盖”操作,无事务隔离级别
数据新鲜度
- 数据库:实时读写,数据延迟<1秒
- Hive:数据导入需执行
LOAD DATA,查询结果延迟取决于任务执行时间(通常分钟级)
扩展性对比
| 指标 | 单机数据库 | Hive集群 |
|—————-|————————————-|——————————————-|
| 最大存储容量 | 受单节点磁盘限制(通常TB级) | 线性扩展至EB级(通过增加DN节点) |
| 计算扩展 | 垂直扩展(CPU/内存升级) | 水平扩展(添加YARN容器) |
| 成本模型 | 硬件成本高昂,license费用 | 廉价PC服务器集群,开源免费 |
适用场景差异
graph TD
A[实时交易] -->|需要| B(传统数据库)
A -->|不需要| C(Hive)
D[海量日志分析] -->|需要| C
D -->|不需要| B
E[即席查询] -->|复杂分析| C
E -->|简单过滤| B
F[数据挖掘] -->|大规模特征工程| C
F -->|小规模样本| BHive的局限性
- 延迟问题:无法满足实时查询需求(需配合Impala、Druid等实时引擎)
- 功能缺失:无二级索引、存储过程、触发器等数据库特性
- 数据一致性:依赖ETL流程保证数据质量,无事务回滚机制
- 权限管理:细粒度权限控制弱于专用数据库(如基于文件的ACL)
选型建议矩阵
| 需求场景 | 推荐方案 | 不推荐方案 |
|---|---|---|
| 高频小额交易处理 | MySQL/Oracle | Hive |
| 用户画像系统(TB级数据) | Hive + ClickHouse | 单一MySQL实例 |
| 实时监控告警 | Kafka + Flink | Hive |
| 历史数据归档分析 | Hive(ORC格式)+ Tez | MongoDB |
| 多维分析立方体 | Hive + Kylin | Cassandra |
FAQs
Q1:Hive能否完全替代传统数据库?
A1:不能,Hive适用于离线分析场景,而传统数据库在实时交易、ACID事务、精确查询等场景不可替代,两者常通过数据同步(如Sqoop)结合使用,形成Lambda架构。
Q2:Hive是否支持实时数据分析?
A2:原生Hive不支持,需结合Impala(低延迟查询引擎)或Trino(跨源实时查询)实现准实时分析,亦可将热数据同步至Redis