上一篇
hive是数据仓库么
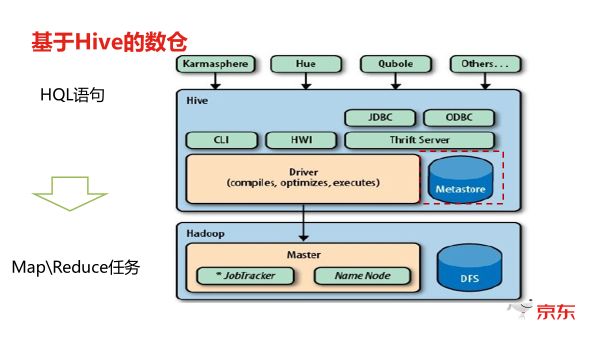
Hive是基于 Hadoop的数据仓库工具,支持类SQL的HiveQL语言,用于大规模数据存储与离线分析,属于典型的数据仓库
Hive是一种基于Hadoop生态系统构建的数据仓库解决方案,其核心功能是通过类SQL语言(HiveQL)实现对大规模结构化数据的存储、管理和分析,以下从技术架构、核心特性、与传统数据仓库的对比等多个维度展开分析:
Hive的技术定位与核心功能
| 特性分类 | 具体描述 |
|---|---|
| 架构基础 | 依托Hadoop生态(HDFS存储+YARN资源调度),采用分布式计算框架(MapReduce/Tez/Spark) |
| 数据模型 | 支持类似传统数据库的表、分区、桶(Bucket)、索引(受限) |
| 查询语言 | HiveQL(兼容大部分SQL语法,但存在差异) |
| 数据处理模式 | 批处理为主,适合高延迟容忍的大数据分析任务 |
| 扩展能力 | 水平扩展(依赖HDFS和YARN),支持PB级数据存储与计算 |
Hive是否符合数据仓库的定义?
数据仓库的核心特征包括:面向主题的集成数据、历史数据存储、支持OLAP分析,Hive在这些方面的表现如下:

数据集成与主题建模
- 支持方式:可通过外部表(External Table)集成多源数据,支持分区(Partition)按时间、地域等维度组织数据。
- 局限性:缺乏完善的ETL工具链(需配合Sqoop、Flume等工具),数据刷新依赖手动或脚本调度。
历史数据管理
- 优势:基于HDFS的不可变存储特性,天然适合长期保存历史数据。
- 挑战:时间旅行查询(Point-in-Time Query)需依赖快照或自定义标记。
OLAP分析能力
- 实现机制:通过HiveQL完成聚合、连接、窗口函数等复杂分析,底层转换为MapReduce任务。
- 性能瓶颈:复杂查询(如多表Join)可能因任务拆分过多导致效率低下。
Hive与传统数据仓库的对比
| 对比维度 | Hive | 传统数据仓库(如Teradata/Greenplum) |
|---|---|---|
| 架构模式 | 分布式松耦合架构(Master-Slave) | 紧耦合MPP(Massively Parallel Processing)集群 |
| 硬件成本 | 低成本(基于廉价PC服务器) | 高昂(专用硬件+License) |
| 扩展性 | 线性水平扩展 | 垂直扩展(存在上限) |
| 实时性 | 分钟级延迟(批处理) | 亚秒级实时查询(OLAP优化) |
| 数据加载方式 | 批量导入(如LOAD DATA) | 支持实时/批量混合加载 |
| 事务支持 | ACID部分支持(需开启事务表) | 完整ACID支持 |
| 适用场景 | 离线分析、历史数据挖掘 | 实时报表、高并发交互式分析 |
Hive的典型应用场景
互联网用户行为分析
- 日志数据(如点击流、搜索记录)按天/小时分区存储,通过
INSERT OVERWRITE定期刷新数据。 - 示例查询:
SELECT referrer, COUNT() FROM logs WHERE date='2023-10-01' GROUP BY referrer;
- 日志数据(如点击流、搜索记录)按天/小时分区存储,通过
金融风控报表
- 交易数据按机构分区,结合ORC列式存储优化压缩比。
- 典型任务:资金流水异常检测(
WINDOW函数分析时间序列)。
物联网时序数据处理
- 设备传感器数据按设备ID+时间双重分区,通过
CLUSTER BY优化聚合计算。
- 设备传感器数据按设备ID+时间双重分区,通过
Hive的局限性与改进方向
性能瓶颈
- 问题:复杂查询依赖多次MapReduce任务,中间结果落地HDFS导致IO开销大。
- 优化方案:启用Tez/Spark引擎、使用LLAP(Low-Latency Analytical Processing)缓存热点数据。
实时性不足
- 解决路径:
- 结合Kafka+Flink实现近实时流批一体(如Apache Hudi/ICEBERG)。
- 使用Hive的增量摄取功能(如
MERGE语句)。
事务一致性
- 当前支持:仅事务表(Transactional Table)支持ACID,需开启
hive.support.concurrency。 - 适用场景:更新频繁的维表管理(如用户画像标签修正)。
FAQs
Q1:Hive能否完全替代传统数据仓库?
A:不完全,Hive适合超大规模离线分析(如PB级日志处理),但在实时性(秒级响应)、高并发查询(如百人同时跑报表)场景下,传统MPP数据仓库或云原生数仓(如Snowflake)更具优势,企业常采用“Hive+实时数仓”混合架构。
Q2:HiveQL与标准SQL的主要区别是什么?
A:
- 语法差异:HiveQL不支持
UPDATE/DELETE(事务表除外),JOIN默认使用Shuffle操作。 - 函数限制:部分窗口函数(如
ROW_NUMBER)需依赖更高版本或自定义UDF。 - 性能提示:需显式指定分区字段(
PARTITIONED BY)优化查询,否则全