
上一篇
hive是一个独立的数据仓库
Hive是基于Hadoop的数据仓库工具,提供类SQL查询能力,可独立处理PB级 数据存储与计算,支持离线数据分析,通过HQL实现数据ETL及复杂查询,兼容HDFS存储体系
Hive是一个独立的数据仓库工具,它基于Hadoop生态系统构建,专为处理大规模结构化和半结构化数据而设计,其独立性体现在不依赖特定厂商的硬件或软件,完全基于开源技术栈实现,同时具备完整的数据存储、管理和分析能力,以下从技术架构、核心特性、应用场景及对比分析等多个维度展开详细说明。
Hive的技术架构与独立性体现
Hive的架构设计以解耦和模块化为核心,其独立性主要体现在以下几个方面:

| 组件 | 功能描述 | 独立性体现 |
|---|---|---|
| 元数据存储 | 使用内嵌的关系数据库(如MySQL、PostgreSQL)存储表结构、分区信息、权限等元数据 | 不绑定特定数据库,支持多种RDBMS |
| 数据存储层 | 依赖HDFS存储实际数据,支持文本、ORC、Parquet等多种文件格式 | 数据与计算分离,兼容Hadoop生态 |
| 查询引擎 | 通过MapReduce、Tez或Spark执行SQL查询,支持自定义优化规则 | 可替换底层执行引擎(如切换至Spark提升性能) |
| 客户端接口 | 提供JDBC/ODBC、RESTful API,兼容BI工具(如Tableau、Power BI) | 标准化接口降低耦合性 |
| 扩展机制 | 支持UDTF(用户自定义表生成函数)、SerDe(序列化/反序列化插件) | 允许用户按需扩展功能,无需修改核心代码 |
技术细节说明
- 元数据与数据分离:Hive的元数据存储在独立数据库中,而实际数据以文件形式存储在HDFS,这种设计使得Hive不直接管理存储系统,仅通过元数据映射数据位置。
- 计算引擎可插拔:早期依赖MapReduce,后续支持Tez(基于DAG调度)和Spark(内存计算),用户可灵活选择执行引擎。
- 协议兼容性:通过HiveServer2提供标准SQL接口,支持多并发查询,且兼容JDBC/ODBC协议,可被第三方工具直接调用。
Hive的核心特性与独立数据仓库能力
作为独立数据仓库,Hive具备以下关键能力:
结构化数据处理
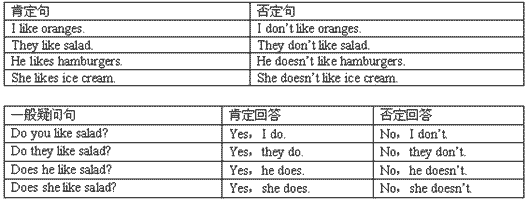
- 类SQL语法:支持HiveQL(类似SQL的查询语言),包含
SELECT、JOIN、GROUP BY、WINDOW等操作。 - Schema管理:支持定义
PRIMARY KEY、FOREIGN KEY(仅限元数据层面),实际数据仍为无模式(Schema-on-Read)。 - 分区与桶:通过分区(按时间、地域等)和桶(哈希分布)优化查询性能,独立于底层存储实现逻辑分层。
横向扩展能力
- 数据规模:依托HDFS的分布式存储,可处理PB级数据。
- 计算扩展:通过YARN动态分配资源,支持千台节点并行查询。
- 表类型支持:
| 表类型 | 特点 |
|——————|—————————————–|
| 内部表 | 数据和元数据均由Hive管理 |
| 外部表 | 仅管理元数据,数据由外部系统维护 |
| 临时表 | 会话级生命周期,用于中间计算结果存储 |
| 分桶表 | 数据按哈希值分配到多个桶,提升连接效率 |
ETL与数据集成
- 导入工具:
LOAD DATA支持从本地或HDFS批量导入数据,Sqoop可同步关系数据库数据。 - 导出工具:
INSERT OVERWRITE将结果写回HDFS或通过EXPORT导出至文件系统。 - 流式处理:通过
Hive Streaming支持实时数据摄入(需配合Kafka等工具)。
安全与权限控制
- 认证机制:集成Kerberos实现集群级身份验证。
- 授权模型:基于角色的访问控制(RBAC),支持
GRANT/REVOKE语句管理表级/列级权限。 - 审计日志:记录所有查询操作,便于合规性审查。
Hive与传统数据仓库的对比分析
| 维度 | Hive | 传统数据仓库(如Teradata) | 云原生数仓(如Snowflake) |
|---|---|---|---|
| 架构模式 | 分布式架构,依赖Hadoop生态 | 专有硬件+MPP架构 | 全托管云服务,无服务器架构 |
| 扩展性 | 横向扩展(节点增加即扩容) | 纵向扩展(依赖高端硬件) | 弹性扩缩容(按需计费) |
| 成本 | 开源免费,运维成本高 | 硬件+软件授权费用高昂 | 按需付费,初期成本低 |
| 实时性 | 批处理为主(分钟级延迟) | 亚秒级实时查询 | 毫秒级实时查询 |
| 数据加载 | 批量导入(适合离线分析) | 实时数据管道支持 | 持续数据加载(Streams) |
| 生态兼容性 | 与Hadoop组件深度集成(如Spark、Flink) | 封闭生态,依赖厂商工具链 | 多云支持,兼容SQL与第三方工具 |
独立性优势归纳:
- 技术自主性:用户可完全控制数据存储、计算资源和查询逻辑,避免厂商锁定。
- 成本可控:基于开源软件和通用硬件构建,长期运维成本低于商业数仓。
- 灵活定制:通过UDF、SerDe等机制适应特殊业务需求,例如自定义数据格式解析。
适用场景与局限性
最佳应用场景
- 离线数据分析:如日志处理、用户行为分析、报表生成。
- 历史数据归档:PB级冷数据存储与查询。
- 复杂ETL任务:多源数据清洗、转换与聚合。
- 机器学习预处理:特征工程、样本筛选等批量操作。
局限性
- 实时性不足:默认批处理模式,无法满足低延迟查询需求。
- 事务支持有限:仅支持
ACID事务(需开启事务表),更新操作效率较低。 - 依赖Hadoop生态:需配置HDFS、YARN等组件,部署复杂度较高。
优化实践与趋势
- 性能优化
- 文件格式:使用ORC/Parquet替代TextFile,减少IO开销。
- 分区策略:按高频查询字段(如日期)分区,避免全表扫描。
- 索引:创建
COMPACTED或BITMAP索引加速过滤查询。
- 实时性增强:
- 结合
Apache Kafka和Hive Streaming实现近实时数据处理。 - 使用
Redis缓存热点数据,弥补Hive延迟短板。
- 结合
- 云原生演进:
- 通过
Kubernetes部署Hive,提升资源利用率。 - 集成
Iceberg或Hudi支持增量更新与时间旅行。
- 通过
FAQs
问题1:Hive是否可以完全脱离Hadoop运行?
答:Hive的设计高度依赖Hadoop生态,其数据存储基于HDFS,资源调度依赖YARN,因此无法完全脱离Hadoop,但可以通过以下方式降低耦合度:
- 使用
Local Mode在单机测试查询(仅限小规模数据)。 - 将元数据迁移至其他存储系统(如MySQL),但生产环境仍需HDFS支持。
问题2:如何处理Hive的实时查询需求?
答:Hive本身适用于离线分析,但可通过以下方案补充实时能力:
- 混合架构:实时部分使用
Kafka+Flink,批量处理由Hive负责。 - 近似实时:设置
ORC文件的COMPAT压缩并启用Vectorization优化,将查询延迟降至亚分钟级。 - 物化视图:预先计算热门查询结果并存储为
Materialized View,减少重复
相关文章

hive是一款独立的数据仓库工具

数据仓库的含义及特点,数据仓库具有哪些特点(数据仓库的含义及特点,数据仓库具有哪些特点呢)

如何处理MapReduce和Hive中的故障,HiveServer与HiveHCat进程问题解析?

以下几个疑问句标题可供选择,,创城数据仓库的工资待遇究竟如何?,创城数据仓库工资待遇怎么样?,谁了解创城数据仓库的工资待遇情况?
Blod一词在英语中并不常见,它可能是一个拼写错误或者是一个特定领域的术语。由于缺乏上下文,很难确定其确切含义。然而,如果我们假设blod是一个打字错误,它可能是想表达blood(血液),我将基于这个假设来生成一个原创的疑问句标题,,Blood: The Vital River of Life – What Happens When Its Compromised?,如果blod实际上指的是其他概念或事物,请提供更多的上下文信息,以便我能够提供一个更准确的标题。

hive数据仓库和传统数据仓库

hive是一种主流的构建数据仓库
由于本站全新内容cdn$不是一个明确的文章,而是一个不完整的字符串,我无法直接为其生成一个疑问句标题。如果您能提供更多的上下文或文章内容,我将很乐意帮助您创建一个原创的疑问句标题。,如果这是一个关于内容分发网络(CDN)的文章,那么一个可能的疑问句标题可以是,,如何有效利用内容分发网络(CDN)提升网站性能和用户体验?,或者,如果文章是关于某个特定主题的,比如CDN的安全性问题,那么标题可能是,,内容分发网络(CDN)如何增强网站的数据安全和隐私保护?,请提供更多信息,以便我能更准确地帮助您。








