上一篇
hive是一种主流的构建数据仓库
Hive是基于Hadoop的数据仓库工具,支持SQL语法实现大数据存储与分析,擅长处理PB级结构化数据,广泛应用于离线数仓建设和
Hive是一种基于Hadoop生态系统构建的数据仓库解决方案,专为处理大规模结构化和半结构化数据设计,它通过类SQL的查询语言(HiveQL)将复杂的MapReduce任务抽象为直观的语句,降低了大数据处理的技术门槛,以下从技术架构、核心特性、应用场景及优劣势等方面展开详细分析。
Hive技术架构解析
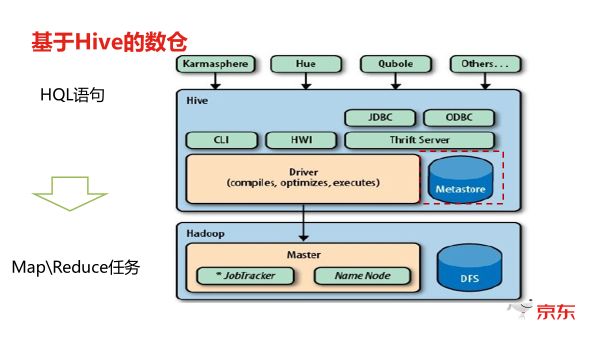
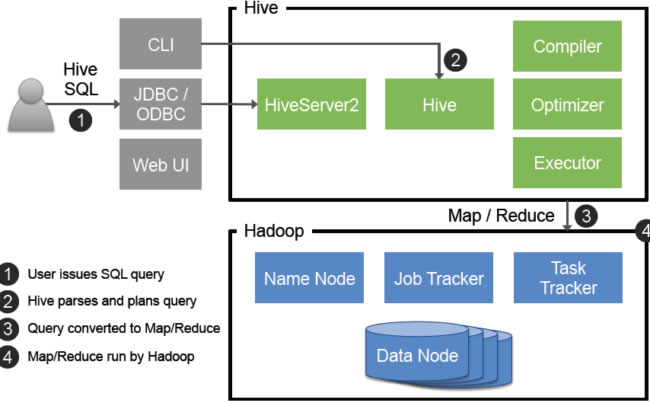
Hive采用典型的分层架构设计,核心组件包括元数据存储、查询编译器、执行引擎和客户端接口,其架构层级如下:
| 层级 | 核心组件 | 功能描述 |
|---|---|---|
| 元数据层 | Metastore(通常基于RDBMS) | 存储表结构、分区信息、权限等元数据,支持MySQL、PostgreSQL等关系型数据库。 |
| 编译层 | Parser、Semantic Analyzer、Optimizer | 解析HiveQL语句,进行语法分析、语义校验和查询优化(如谓词下推、列裁剪)。 |
| 执行层 | Thrift Server、Execution Engine | 将逻辑执行计划转化为物理任务(如MapReduce/Tez/Spark作业),协调资源分配与任务调度。 |
| 存储层 | HDFS(默认)、兼容S3/Azure Blob | 以表形式组织数据,支持文本、ORC/Parquet等存储格式,通过分区和Bucketing优化查询性能。 |
元数据管理
Metastore是Hive的核心组件,负责维护数据库、表、列、分区等元信息,其实现方式分为内嵌式(Derby)和独立部署(如MySQL),生产环境通常选用高可用的关系型数据库以保证元数据可靠性。
CREATE TABLE user_logs ( user_id STRING, action STRING, timestamp TIMESTAMP ) PARTITIONED BY (date STRING) STORED AS ORC;
上述建表语句的元数据(表结构、分区字段)会存储在Metastore中。

查询执行流程
HiveQL的执行过程可分为以下阶段:
- 语法解析:将
SELECT user_id FROM user_logs WHERE date='2023-10-01'转换为抽象语法树(AST)。 - 语义分析:校验表名、字段名是否存在,数据类型是否匹配。
- 逻辑优化:消除冗余条件(如
WHERE 1=1)、合并过滤条件。 - 物理计划生成:根据表存储格式(如ORC)和分区信息,生成MapReduce或Tez任务。
- 任务执行:启动分布式计算框架,从HDFS读取数据并输出结果。
Hive核心特性与优势
类SQL查询与扩展性
HiveQL兼容大部分SQL语法(如JOIN、GROUP BY、窗口函数),同时支持UDF(用户自定义函数)扩展。
-计算每日用户访问次数 SELECT date, COUNT(user_id) AS visits FROM user_logs GROUP BY date;
Hive通过INSERT OVERWRITE实现数据覆盖,通过ALTER TABLE ADD PARTITION动态添加分区,适合处理PB级离线数据分析。
存储优化机制
- 分区(Partitioning):按业务维度(如日期、地区)划分数据目录,减少全表扫描,例如按
date分区后,查询特定日期的数据仅需扫描对应子目录。 - 文件格式:支持ORC/Parquet列式存储,压缩比高且支持复杂数据类型;相比文本格式,ORC可减少50%以上的存储空间。
- 索引:通过
COMPACTED或BITMAP索引加速等值查询,但需权衡写入开销。
横向扩展能力
Hive依赖HDFS的分布式存储和YARN的资源调度,可通过增加节点实现线性扩展,100节点集群可支持数百TB数据的并行查询,而无需修改应用逻辑。
典型应用场景
日志分析
互联网公司常将Hive用于用户行为日志处理。
- 按小时分区存储访问日志,通过
INSERT INTO导入HDFS。 - 使用窗口函数分析用户留存率:
SELECT user_id, COUNT(DISTINCT action_time) AS active_days FROM user_logs WHERE action_time BETWEEN '2023-10-01' AND '2023-10-07' GROUP BY user_id HAVING active_days >= 3;
数据仓库整合
Hive可作为企业级数据仓库的底层引擎,通过Sqoop导入传统数据库数据,结合Impala实现混合查询(批处理+实时)。
- 将MySQL中的订单表导入Hive,按月份分区。
- 使用
LATERAL VIEW展开数组字段(如商品标签)进行多维分析。
ETL管道
Hive常与Oozie/Airflow结合构建自动化ETL流程。
- 每日增量导入日志数据到Hive分区表。
- 执行聚合任务生成报表数据。
- 将结果导出至BI工具(如Tableau)。
Hive的局限性与优化策略
主要缺点
| 问题 | 表现 | 解决方案 |
|---|---|---|
| 高延迟 | 单次查询耗时从分钟到小时级 | 使用Tez/Spark替代MapReduce,启用LLAP(内存计算) |
| 实时性差 | 无法处理秒级响应需求 | 结合Kafka+Impala/Druid实现实时流处理 |
| Schema刚性 | 插入数据前需定义严格Schema | 使用SERDE解析半结构化数据(如JSON) |
| 小文件问题 | 大量小文件导致MapTask效率下降 | 开启CombineTextInputFormat或预分区合并 |
性能优化实践
- 分区裁剪:确保
WHERE条件包含分区字段,避免全表扫描。 - 列式存储:使用ORC格式并开启Snappy压缩,提升IO效率。
- 倾斜优化:通过
MAPJOIN或DISTRIBUTE BY解决数据分布不均问题。 - 资源配置:调整
mapreduce.job.reduces参数控制并发度。
Hive与竞品对比
| 特性 | Hive | Impala | Presto |
|---|---|---|---|
| 计算模型 | 批处理(MapReduce/Tez/Spark) | MPP实时查询 | 无共享架构,依赖各节点资源 |
| 延迟 | 高(分钟级) | 低(秒级) | 中等(亚秒级) |
| 扩展性 | 横向扩展(依赖YARN) | 纵向扩展(依赖大内存节点) | 混合扩展(动态调度) |
| 兼容性 | SQL-like,支持复杂UDF | 接近标准SQL,UDF支持较弱 | 高度兼容SQL,支持多种数据源 |
FAQs
Q1:Hive是否支持实时查询?如何弥补延迟缺陷?
A1:Hive本质是离线数仓工具,单次查询延迟通常在分钟到小时级,若需实时分析,可结合以下方案:
- Impala/Druid:将热数据同步至Impala或Druid,Hive处理历史数据。
- 流批一体:使用Kafka+Flink处理实时流,结果写入Hive供后续分析。
- 内存计算:启用Hive的LLAP(Low-Latency Analytical Processing)特性,通过内存缓存加速查询。
Q2:如何优化Hive小文件过多的问题?
A2:小文件会导致大量MapTask,降低资源利用率,优化方法包括:
- 合并小文件:使用
Hive CONCAT命令合并同类文件,或设置hive.merge.mapfiles为true。 - 合理分区:按高频查询维度(如日期)分区,避免过度分区导致碎片。
- 动态分区调整:通过
hive.exec.dynamic.partition.mode=nonstrict允许动态补全缺失分区。 - 采样统计:执行
ANALYZE TABLE生成统计信息,帮助