
上一篇
hive是一种数据库
Hive是基于Hadoop的数据仓库工具,通过类SQL语言HiveQL处理大规模 数据,适用于离线分析与数据挖掘,支持ETL和复杂查询,但实时性较低
Hive是一种基于Hadoop的数据仓库解决方案,专为大规模数据处理设计,它通过类SQL的查询语言(HiveQL)实现对分布式存储数据的分析,结合Hadoop的HDFS实现高效存储与计算分离,以下从技术架构、核心特性、应用场景等维度展开详细分析。
Hive的核心定位与技术架构
基础架构组成
| 组件 | 功能描述 |
|---|---|
| Metastore | 元数据管理,存储表结构、分区信息 |
| Driver | 编译HiveQL为MapReduce/Tez/Spark任务 |
| Executor | 执行引擎(支持MR/Tez/Spark多种模式) |
| HDFS | 底层存储系统,存储实际数据 |
| SerDe | 序列化/反序列化框架(处理数据格式) |
| UDF | 用户自定义函数(扩展计算能力) |
数据存储机制
- 基于HDFS的存储:数据以文本文件形式分块存储,默认采用
.txt或.seq格式。 - 分区与桶:通过分区(Partition)实现粗粒度数据划分(如按日期),通过桶(Bucket)实现细粒度哈希分布。
- 表类型:
- 内部表:数据存储在Hive指定路径
- 外部表:数据路径由用户管理,元数据由Hive维护
查询执行流程
- 语法解析:将HiveQL转换为抽象语法树(AST)
- 语义分析:检查表/列是否存在,数据类型验证
- 逻辑计划生成:生成可执行的逻辑执行计划
- 优化器:进行列裁剪、谓词下推等优化
- 物理计划生成:转换为MapReduce/Tez任务
- 任务提交:通过YARN调度资源执行
Hive的核心特性解析
SQL兼容性
- 支持大部分标准SQL语法(DDL/DML/DQL)
- 特有语法扩展:
CREATE TABLE ... STORED AS指定存储格式(ORC/Parquet/Text)PARTITIONED BY定义分区字段CLUSTERED BY定义桶排序字段
扩展性设计
| 扩展维度 | 实现方式 |
|---|---|
| 存储格式 | ORC/Parquet/AVRO/RCFile/Text |
| 计算引擎 | MR/Tez/Spark |
| 数据源适配 | 通过SerDe支持自定义数据格式 |
| 函数扩展 | UDF/UDAF/TRANSFOMER |
数据治理能力
- 元数据管理:通过Metastore(关系型数据库)维护表结构、分区信息
- 权限控制:集成Hadoop ACLs实现文件级权限管理
- 事务支持:基于ACID的事务表(需开启事务支持)
Hive与传统数据库对比
| 特性 | Hive | 传统数据库(MySQL/Oracle) |
|---|---|---|
| 数据规模 | PB级 | GB级 |
| 计算模型 | 批量处理(MapReduce) | 实时OLTP |
| 扩展性 | 横向扩展(依赖Hadoop集群) | 纵向扩展(硬件升级) |
| 存储成本 | 廉价HDFS存储 | 高端SAN/NAS存储 |
| 延迟 | 分钟级(复杂查询) | 毫秒级 |
| 事务支持 | 最终一致性(事务表) | ACID强一致性 |
典型应用场景
离线数据分析
- 日志处理:网站访问日志、应用日志的清洗与分析
- 用户画像:整合多数据源构建标签体系
- 报表生成:每日/每周运营数据统计
数据仓库建设
- 分层建模:ODS→DWD→DWS→ADS分层处理
- ETL管道:通过HiveQL实现数据抽取、转换、加载
- 历史数据归档:长期存储冷数据
机器学习特征工程
- 原始数据预处理(过滤/聚合/特征提取)
- 样本数据生成(通过分区采样)
性能优化策略
存储优化
- 列式存储:采用ORC/Parquet减少IO开销
- 压缩编码:启用Snappy/Zlib压缩,配合列式存储提升效率
- 文件大小控制:单个文件建议128MB-1GB
查询优化
- 分区剪裁:WHERE条件包含分区字段时跳过无关分区
- 动态分区调整:根据数据量自动创建分区
- 并行度调优:设置
mapreduce.job.reduces参数控制并发数
资源优化
- 内存配置:调整Map/Reduce任务内存占比(mapreduce.map.memory.mb)
- 缓存中间结果:启用中间表缓存常用计算结果
常见使用问题与解决方案
问题1:小文件过多导致Map任务效率低
解决方案:

- 合并小文件:使用
Hive ORC格式并设置合理BlockSize - 开启CombineFileInputFormat:减少Map任务数量
- 调整输入策略:
hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
问题2:复杂查询执行时间过长
优化方向:
- 使用Tez/Spark引擎替代MapReduce
- 启用LLAP(Low Latency Analytical Processing)加速Ad-hoc查询
- 预计算常用指标(通过分区表或中间结果表)
FAQs
Q1:Hive是否支持实时查询?
A:原生Hive适用于离线批处理,实时场景需结合流计算框架,可通过以下方案实现近实时分析:
- 使用Kafka+Spark Streaming进行流处理
- 配置Hive事务表配合定时任务刷新数据
- 采用Impala/Presto等Mpp引擎加速交互式查询
Q2:如何保障Hive数据的一致性?
A:通过以下机制确保数据可靠性:
- ACID事务:开启
hive.txn.manager支持插入/更新操作原子性 - 快照隔离:基于时间戳的多版本控制(MVCC)
- Write Committed:默认模式,每个操作独立提交
- 分区事务:支持分区级别的事务回滚
相关文章

如何处理MapReduce和Hive中的故障,HiveServer与HiveHCat进程问题解析?
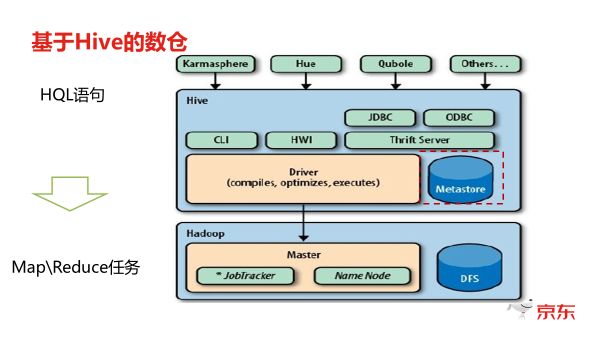
hive是一种主流的构建数据仓库

查看hive数据库_Hive数据库导入导出

在络托管服务器是一种什么样的体验?(在络托管服务器是一种什么样的体验服务)
Blod一词在英语中并不常见,它可能是一个拼写错误或者是一个特定领域的术语。由于缺乏上下文,很难确定其确切含义。然而,如果我们假设blod是一个打字错误,它可能是想表达blood(血液),我将基于这个假设来生成一个原创的疑问句标题,,Blood: The Vital River of Life – What Happens When Its Compromised?,如果blod实际上指的是其他概念或事物,请提供更多的上下文信息,以便我能够提供一个更准确的标题。

hive是一款独立的数据仓库工具
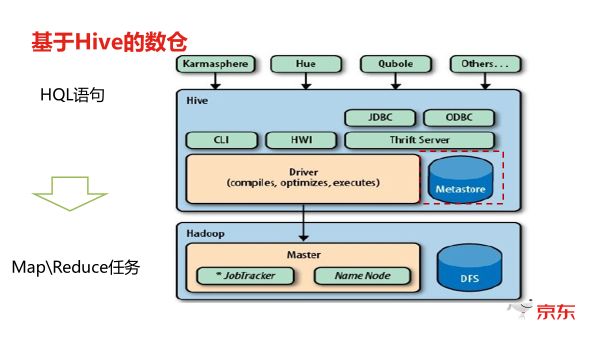
hive是一个独立的数据仓库

大数据是一种数据吗_什么是数据探索?








