上一篇
分布式数据采集系统可以做什么
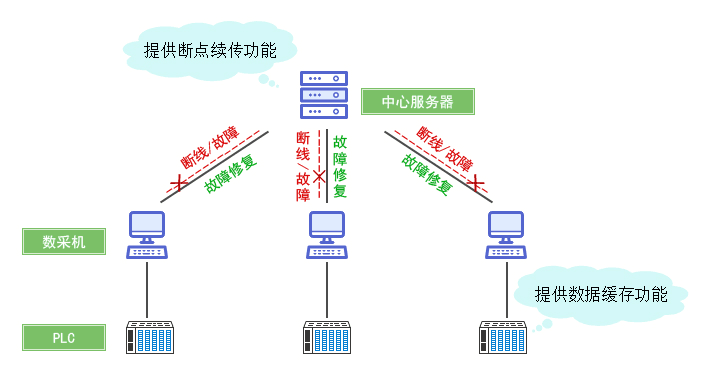
分布式数据采集系统可实现多源异构数据的实时并行采集,通过分布式节点协同工作提升采集效率,支持海量数据处理与传输,具备高可靠性、可扩展性,适用于工业监控、
分布式数据采集系统的核心功能与应用场景
分布式数据采集系统是一种通过多节点协同工作实现大规模、高效率数据收集的技术架构,其核心目标是解决传统单机采集系统在数据量、实时性、可靠性等方面的瓶颈,适用于需要处理海量数据或复杂数据源的场景,以下是其核心功能与典型应用场景的详细分析:
核心功能模块
| 功能模块 | 具体能力 | 技术支撑 |
|---|---|---|
| 分布式数据采集 | 支持多节点并行采集,覆盖广域数据源(如传感器、日志、API等)。 | Kafka、Flume、Logstash等分布式框架 |
| 实时数据处理 | 毫秒级延迟的数据清洗、过滤、聚合,支持流式计算。 | Flink、Spark Streaming、Storm |
| 动态扩展能力 | 根据数据流量自动扩容或缩容,避免资源浪费。 | Kubernetes容器化部署、弹性负载均衡 |
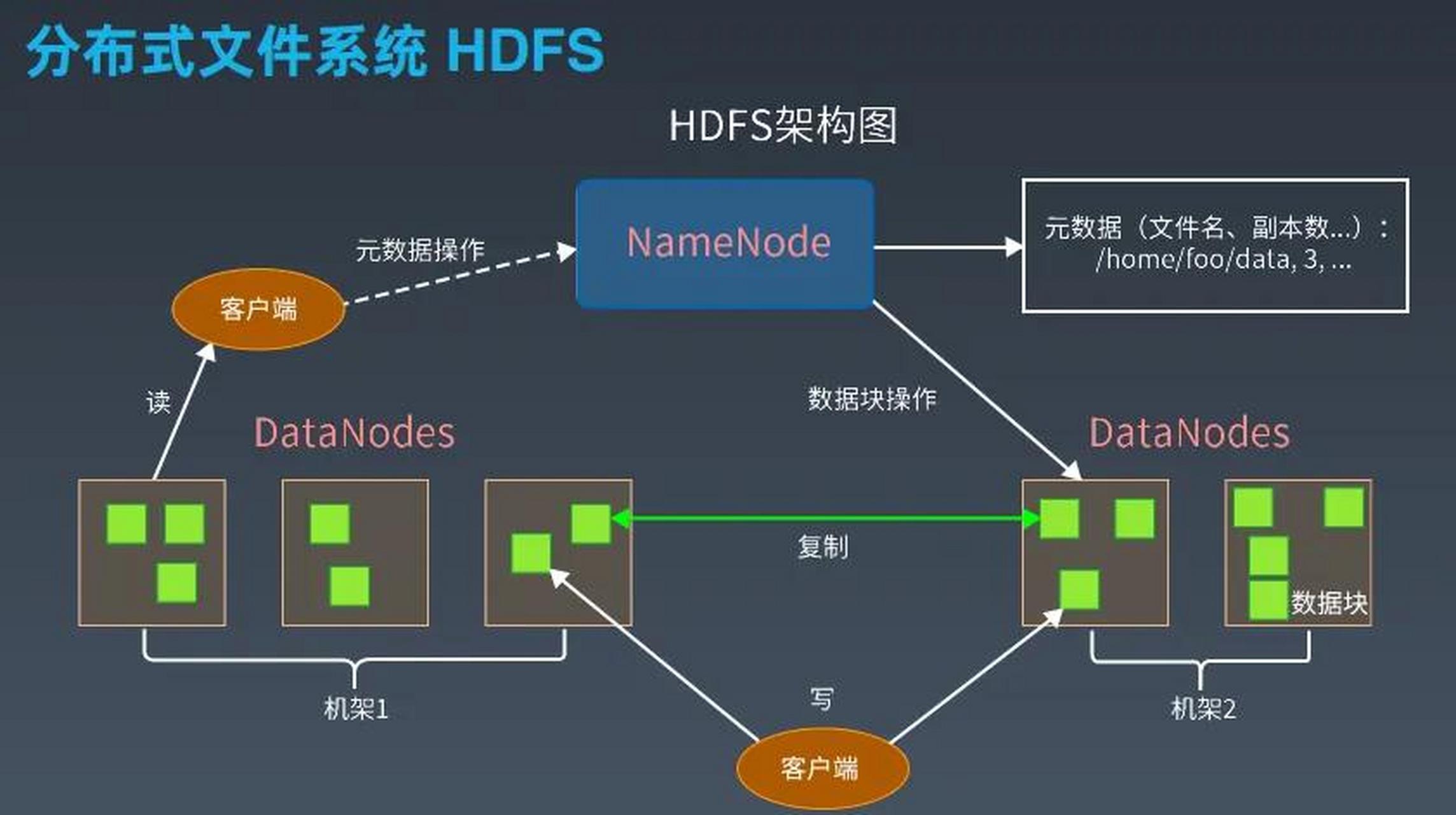
| 高容错性 | 节点故障时自动切换,数据不丢失,保证7×24小时稳定运行。 | HDFS冗余存储、ZooKeeper协调服务 |
| 多协议支持 | 兼容HTTP、MQTT、TCP/UDP等协议,适应不同设备的数据上传需求。 | Protocol Buffers、RESTful API |
| 数据路由与分发 | 按规则将数据推送至不同存储或计算节点(如数据库、数据仓库、消息队列)。 | Apache NiFi、Kafka分区机制 |
典型应用场景
物联网(IoT)领域
- 场景:智慧城市中的数十万个传感器(如空气质量监测、交通摄像头)实时上报数据。
- 价值:分布式系统可并行处理百万级设备的数据流,通过边缘计算筛选有效信息,降低云端压力。
- 案例:某智能电网项目通过分布式采集系统每秒处理50万条电力设备状态数据,故障响应时间缩短至100ms内。
金融交易监控
- 场景:证券交易平台需实时采集全国多个营业部的交易日志、市场行情、用户行为数据。
- 价值:分布式架构可横向扩展,支持高并发写入(如Kafka峰值吞吐量达百万消息/秒),避免单点故障导致数据丢失。
- 案例:某银行利用Flink+Kafka构建实时风控系统,异常交易识别延迟低于200ms。
电商用户行为分析

- 场景:电商平台每日需采集亿级用户点击、浏览、下单事件,用于精准推荐和库存预测。
- 价值:分布式采集系统可自动分片处理数据,结合Hadoop/Spark进行离线分析,挖掘用户偏好。
- 案例:某头部电商通过Logstash+Elasticsearch实现用户行为日志的实时可视化,分析效率提升3倍。
工业设备远程监控
- 场景:工厂内数千台机械设备的运行参数(温度、振动、能耗)需持续上传至云端。
- 价值:分布式系统支持MQTT协议,适应低功耗设备传输需求,并通过规则引擎触发预警(如设备超温)。
- 案例:某汽车制造商使用ThingsBoard+InfluxDB搭建设备监控系统,运维成本降低40%。
社交媒体数据抓取
- 场景:爬取微博、抖音等平台的公开内容,用于舆情分析或竞品监测。
- 价值:分布式爬虫可模拟海量IP访问,绕过反爬机制,并通过消息队列(如RabbitMQ)缓冲数据流。
- 案例:某舆情公司利用Scrapy+Kafka集群,每日抓取千万级社交媒体帖子,分析速度提升5倍。
对比传统单机系统的优势
| 维度 | 分布式数据采集系统 | 传统单机系统 |
|---|---|---|
| 处理规模 | 支持PB级日均数据量(如Hadoop集群) | 受限于单服务器硬盘和内存(通常TB级) |
| 可靠性 | 节点故障自动切换,数据副本保障 | 单点故障可能导致数据丢失 |
| 扩展成本 | 横向扩展(增加节点),无需停机 | 纵向扩展(升级硬件),成本高且复杂 |
| 延迟 | 实时处理延迟可低至毫秒级(如Kafka) | 高并发下延迟显著上升 |
| 地理分布 | 支持全球多数据中心部署,数据就近处理 | 受限于单一机房网络带宽 |
技术架构与组件选型
数据采集层
- 工具:Flume(日志收集)、Telegraf(物联网设备)、Apache NiFi(数据路由)。
- 协议:MQTT(IoT)、HTTP/HTTPS(API)、WebSocket(实时推送)。
数据传输层
- 消息队列:Kafka(高吞吐)、RabbitMQ(复杂路由)、Redis Stream(低延迟)。
- 负载均衡:Nginx、HAProxy,确保流量均匀分配至各节点。
存储与计算层
- 实时计算:Flink(窗口运算)、Spark Streaming(微批处理)。
- 长期存储:HDFS(海量文件)、TimescaleDB(时序数据)、Elasticsearch(全文检索)。
管理与监控层
- 监控工具:Prometheus(指标采集)、Grafana(可视化)、Elastic APM(应用性能)。
- 配置中心:Consul、Etcd,统一管理全局配置。
实施挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 数据一致性 | 使用分布式事务协议(如Two-Phase Commit)或最终一致性架构(如Kafka exactly-once)。 |
| 网络带宽瓶颈 | 数据压缩(如Snappy、LZ4)、增量传输(仅发送变化字段)。 |
| 时钟同步问题 | 部署NTP服务或集成时间戳校准机制(如Google Spanner的逻辑时钟)。 |
| 多源数据融合 | 通过Schema Registry统一数据格式,或使用Data Lake存储原始数据。 |
FAQs
Q1:分布式数据采集系统适合哪些业务场景?
A1:适用于数据量大(如日均亿级事件)、实时性要求高(如毫秒级延迟)、数据源分散(如全球设备)的场景,例如物联网监控、金融交易、社交平台分析等。
Q2:部署分布式系统是否需要高昂的初期投入?
A2:可通过公有云服务(如AWS Kinesis、Azure Event Hub)降低硬件成本,或采用开源工具(如Kafka+Flink)自行搭建,初期投入通常低于传统大型