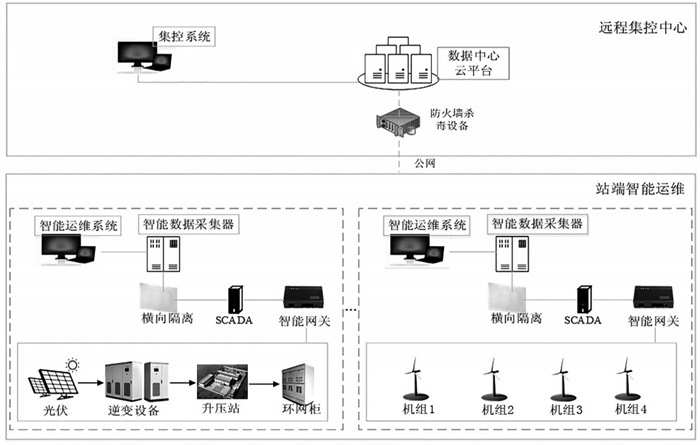
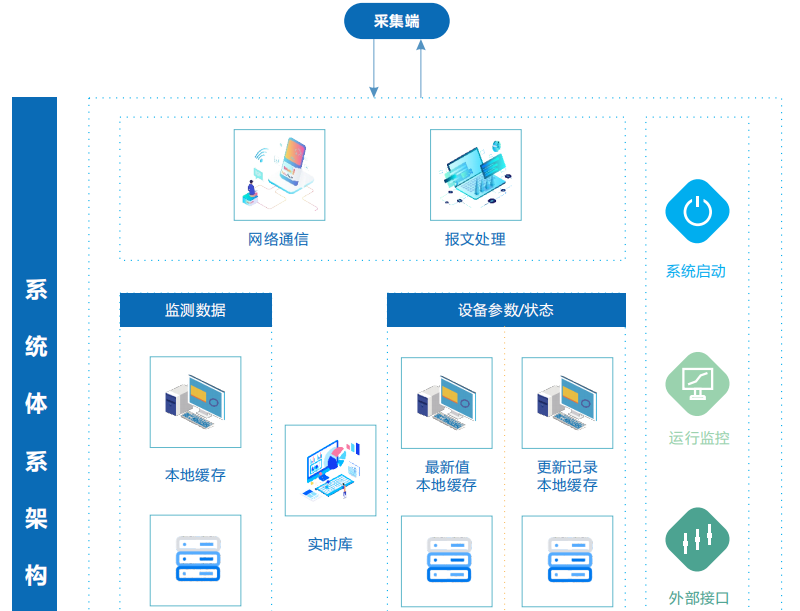
分布式数据采集系统挂掉常因网络故障、节点负载过高、数据丢失或
分布式数据采集系统挂掉的原因分析
分布式数据采集系统(Distributed Data Collection System)通常由多个节点协同工作,完成海量数据的采集、传输和存储,其架构复杂性决定了故障诱因的多样性,以下是导致系统挂掉的核心原因分类及具体分析:
硬件层故障
| 故障类型 | 具体原因 | 典型案例 |
| 服务器宕机 | 电源故障、硬件老化、散热不足导致CPU/内存/硬盘过热损坏 | 某节点因风扇故障导致CPU过热降频,数据采集任务卡死 |
| 磁盘损坏 | 机械硬盘坏道、SSD写入寿命耗尽、RAID阵列故障 | 单节点RAID5阵列中两块硬盘同时损坏,数据丢失 |
| 网络设备故障 | 交换机端口宕机、光纤中断、路由器配置错误 | 机房网络交换机重启导致节点间通信中断 |
软件层缺陷
| 故障类型 | 具体原因 | 典型案例 |
| 代码逻辑破绽 | 多线程并发处理异常、内存泄漏、未捕获的异常导致进程崩溃 | 数据采集程序未处理JSON解析异常,导致节点退出 |
| 依赖库冲突 | 第三方库版本不兼容(如Protobuf、Log4j)、操作系统更新导致API行为变化 | Java程序因Log4j 2.x版本破绽被攻击,系统瘫痪 |
| 协调服务失效 | ZooKeeper/Etcd集群脑裂、元数据不一致导致节点无法注册 | ZooKeeper集群因网络分区触发半数以上节点离线 |
配置与参数问题
| 故障类型 | 具体原因 | 典型案例 |
| 超限参数设置 | 单节点采集速率过高、连接数超过目标数据库阈值、心跳检测频率过低 | 配置每秒10万条数据采集,目标Kafka队列积压崩溃 |
| 动态调整错误 | 扩缩容时未同步配置、负载均衡策略与实际流量不匹配 | 新增节点未加入Consul服务发现,导致数据路由错误 |
| 安全策略冲突 | TLS证书过期、防火墙规则误杀合法IP、认证密钥泄露 | 零信任策略误封禁正常采集节点的IP地址 |
资源耗尽型故障
| 故障类型 | 具体原因 | 典型案例 |
| 内存溢出 | 数据结构缓存过大(如HashMap未及时清理)、内存泄漏 | JVM堆内存占满导致Full GC频繁,采集任务停滞 |
| 磁盘空间不足 | 日志文件未轮换、临时数据缓存目录未清理、压缩算法失效 | /var/lib/docker/容器日志占满磁盘,系统无法写入新数据 |
| CPU过载 | 复杂计算任务(如实时清洗)占用过多线程、垃圾回收频繁 | 单节点CPU使用率长期>95%,触发系统保护机制 |
网络与通信问题
| 故障类型 | 具体原因 | 典型案例 |
| 网络分区 | 跨机房专线中断、NAT映射表溢出、DNS解析失败 | 数据中心之间光纤被挖断,导致双活集群脑裂 |
| 协议不匹配 | 客户端/服务器版本升级后协议变更未同步、序列化格式错误 | Protobuf字段新增后未向后兼容,导致数据解析失败 |
| 带宽瓶颈 | 突发流量超过网络上限、DDoS攻击抢占带宽 | 10Gbps链路被数百节点共享,高峰时延>1s |
数据与负载问题
| 故障类型 | 具体原因 | 典型案例 |
| 数据倾斜 | 哈希分片算法不均衡、热点数据集中(如IP地址分布不均) | 某分片节点承担70%流量,最终因负载过高崩溃 |
| 数据突变 | 上游业务突发洪峰(如电商大促)、传感器异常集体发送数据 | 物联网设备固件bug导致每秒发送10倍数据量 |
| 数据质量差 | 脏数据(如非规字符、超长字段)导致解析失败、重复数据触发去重逻辑死循环 | JSON字段缺失引发批量处理任务无限重试 |
外部攻击与安全事件
| 故障类型 | 具体原因 | 典型案例 |
| DDoS攻击 | UDP洪水、SYN泛洪针对采集入口节点 | 攻击者伪造百万级IP向数据采集API发送请求 |
| 数据投毒 | 反面构造畸形数据包(如超大JSON)、SQL注入针对存储层 | 破解通过HTTP接口注入删除语句,清空数据库 |
| 权限泄露 | AK/SK密钥暴露、RBAC配置错误导致未授权访问 | 离职员工账号未禁用,持续写入虚假数据 |
FAQs
Q1:如何快速定位分布式数据采集系统的故障根因?
- A1:
- 查看全局状态:通过Prometheus/Grafana检查CPU、内存、磁盘、网络等资源使用率,识别过载节点。
- 分析日志链:从消息队列(如Kafka)的消费延迟、分片分配日志(如Elasticsearch Shard日志)中追踪异常。
- 验证协调服务:检查ZooKeeper/Etcd的选举状态和元数据一致性。
- 网络诊断:使用ping/traceroute/netstat排查分区或延迟问题。
- 复现场景:利用沙箱环境模拟故障前的配置和数据流,验证代码逻辑。
Q2:如何设计高可用的分布式数据采集系统?
- A2:
- 冗余设计:至少部署3个以上采集节点,采用Raft/Paxos协议实现选主。
- 自动扩容:基于Prometheus监控动态扩展Pod(如Kubernetes HPA)。
- 数据持久化:使用Kafka/RabbitMQ作为缓冲层,避免数据丢失。
- 熔断机制:对下游存储(如HDFS)超时请求启用Circuit Breaker。
- 多活部署:跨AZ(Availability Zone)部署关键组件