上一篇
分布式数据采集系统问题怎么解决
采用时间同步机制,优化传输路径,冗余备份节点,负载均衡分配,数据
分布式数据采集系统问题解决方案详解
分布式数据采集系统(Distributed Data Collection System)在现代大数据、物联网(IoT)、工业监控等场景中应用广泛,但其复杂性也带来了诸多挑战,以下是针对常见问题的解决方案,涵盖架构设计、关键技术、优化策略及实际案例。
核心问题与解决方向
| 问题类型 | 具体表现 | 解决方向 |
|---|---|---|
| 数据一致性 | 节点间数据同步延迟、版本冲突 | 分布式事务、时间戳对齐、版本控制 |
| 网络延迟与带宽 | 高并发下数据传输丢包、延迟过高 | 数据压缩、负载均衡、边缘计算 |
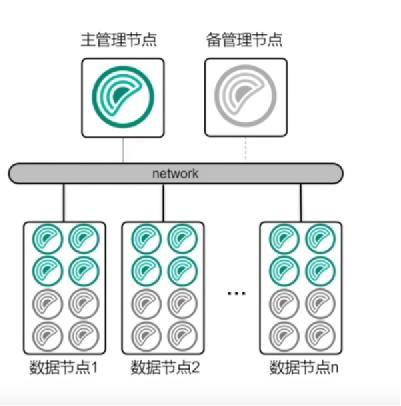
| 故障恢复 | 单点故障导致全局中断 | 冗余设计、自动切换、心跳检测机制 |
| 扩展性 | 新增节点时配置复杂、性能瓶颈 | 模块化设计、动态扩缩容、服务发现 |
| 数据冗余与存储 | 重复数据占用存储资源 | 去重算法、哈希分片、分布式数据库优化 |
| 时钟同步 | 跨节点时间戳不一致导致乱序 | NTP/PTP协议、逻辑时钟(如Lamport Clock) |
| 安全性 | 数据泄露、非规访问 | 加密传输、权限控制、审计日志 |
架构设计关键要素
分层架构设计
- 采集层:负责从多源设备(传感器、日志、API等)获取数据。
工具:Flume、Logstash、Telegraf。
- 传输层:解决高并发数据传输的可靠性和效率。
方案:Kafka(消息队列)、RabbitMQ(AMQP协议)、gRPC(RPC框架)。
- 存储层:按需选择数据库类型。
- 时序数据:InfluxDB、TimescaleDB。
- 非结构化数据:HDFS、Cassandra。
- 关系型数据:CockroachDB(分布式SQL)。
- 采集层:负责从多源设备(传感器、日志、API等)获取数据。
分布式协调机制

- 服务发现与注册:通过Consul、Etcd或ZooKeeper实现节点动态管理。
- 负载均衡:采用一致性哈希(Consistent Hashing)分配任务,避免单点过载。
- 心跳检测:定期发送心跳包(如HTTP/TCP Ping)监控节点状态,结合Raft/Paxos协议实现选举。
关键技术实现
数据分片与并行采集
- 分片策略:按设备ID、地理位置或时间窗口分片,分散负载。
示例:Kafka分区(Partition)按设备ID取模分配。
- 并行处理:使用多线程/协程(如Go的Goroutine)提升采集效率。
- 分片策略:按设备ID、地理位置或时间窗口分片,分散负载。
容错与高可用设计
- 数据副本:Kafka默认保存3个副本,支持自动故障转移。
- 断点续传:记录已采集数据的偏移量(Offset),重启时从断点恢复。
- 降级策略:网络中断时本地缓存(如RocksDB),待恢复后批量上传。
时钟同步与时间戳管理
- NTP/PTP协议:同步物理时钟,误差控制在毫秒级。
- 逻辑时钟:为事件添加Lamport Clock或Vector Clock,解决分布式乱序问题。
数据压缩与传输优化
- 压缩算法:Snappy(低延迟)、LZ4(高压缩比)、Zstd(平衡型)。
- 批处理传输:将多个小数据包合并为批次(如Kafka的Batch API),减少网络开销。
性能优化策略
| 优化目标 | 具体措施 |
|---|---|
| 降低延迟 | 边缘计算(就近处理数据)、UDP协议(非关键场景)、零拷贝技术(如Java NIO) |
| 提升吞吐量 | 异步I/O、连接池复用(如HikariCP)、流量整形(令牌桶算法) |
| 减少存储压力 | 数据采样(如降频采样)、生命周期管理(自动清理过期数据) |
实际案例分析
物联网场景(智慧城市)
- 问题:百万级传感器数据实时上传,网络带宽不足。
- 解决方案:
- 边缘节点预处理数据(如过滤噪声、聚合统计)。
- 使用MQTT协议轻量化传输,Kafka作为消息中间件。
- 按区域分片存储(如华东、华北节点独立部署)。
金融交易监控
- 问题:低延迟要求(<10ms),数据强一致性。
- 解决方案:
- 采用RocketMQ(阿里云)支持亿级消息吞吐。
- 三节点Raft协议保证数据一致性。
- 数据落盘前使用内存缓存(Redis)加速查询。
常见工具对比
| 工具/框架 | 适用场景 | 核心优势 | 缺点 |
|---|---|---|---|
| Apache Kafka | 高吞吐量日志/事件流 | 持久化、分区扩展、生态丰富 | 延迟较高(默认异步刷盘) |
| Flume | 日志收集与聚合 | 简单易用、支持多种Source/Sink | 性能受限于单机 |
| Telegraf | 时序数据采集(IoT/监控) | 插件化、支持上百种设备协议 | 需配合InfluxDB存储 |
| gRPC | 跨语言RPC调用 | 高性能、双向流通信 | 依赖Protobuf定义接口 |
FAQs
Q1:如何处理高并发下的数据丢失问题?
- A:
- 启用可靠传输协议(如TCP而非UDP)。
- 消息中间件设置持久化(Kafka的
acks=all参数)。 - 本地缓存机制(如磁盘文件或内存队列)暂存未确认数据。
- 定期校验数据完整性(如CRC校验码)。
Q2:如何保证跨时区节点的时间戳一致性?
- A:
- 所有节点同步至UTC时间(通过NTP服务器)。
- 使用逻辑时钟补充物理时钟(如记录事件顺序)。
- 存储时统一转换为UTC时间,查询时按需转换时区