上一篇
分布式数据采集系统是干嘛的
分布式数据采集系统通过多节点协同,高效收集、传输和处理海量多源数据,确保实时性与可靠性,适用于大规模物联网、大数据分析等
分布式数据采集系统的核心功能与应用场景
分布式数据采集系统是一种通过多节点协同工作实现大规模、高效率数据收集与处理的技术架构,其核心目标是解决传统集中式数据采集在扩展性、可靠性和实时性方面的瓶颈,尤其适用于海量数据源、高并发场景以及地理分布广泛的数据采集需求。
核心功能解析
| 功能模块 | 具体作用 |
|---|---|
| 数据采集 | 从传感器、设备、日志、API等多源异构渠道获取原始数据。 |
| 数据传输 | 通过消息队列(如Kafka)、RPC框架(如gRPC)或流处理引擎(如Flink)实现数据分发。 |
| 数据处理 | 实时清洗、去重、格式转换、聚合计算等预处理操作。 |
| 数据存储 | 将处理后的数据写入分布式数据库(如HBase)、数据湖(如HDFS)或云存储。 |
| 管理与监控 | 提供节点状态监控、流量调度、故障告警及权限控制等功能。 |
典型应用场景
物联网(IoT)领域
- 场景:智慧城市中的交通摄像头、环境监测传感器、工业设备状态监控等。
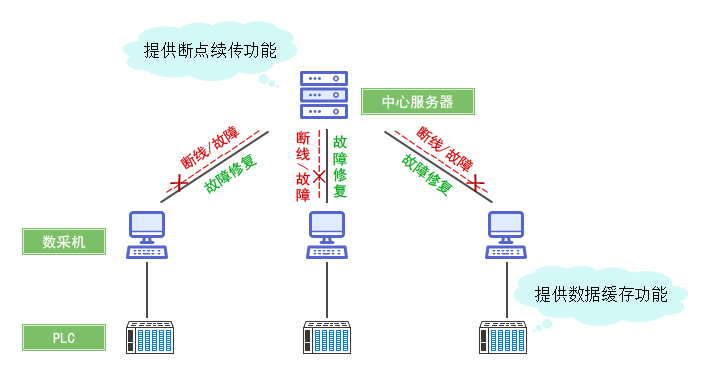
- 需求:每秒数万条设备数据实时上传,需支持断点续传和动态扩容。
- 案例:阿里云IoT平台通过分布式采集系统处理全球数百万设备数据。
金融交易监控
- 场景:股票交易订单、支付流水、风控日志的实时采集与分析。
- 需求:低延迟(<10ms)、高吞吐量(百万级TPS)、数据防改动。
- 技术:基于Flink的流式处理结合Kafka分区策略。
工业大数据分析

- 场景:工厂生产线设备日志、质量检测数据、供应链信息整合。
- 需求:多厂区数据汇聚、异构协议兼容(如OPC UA、MQTT)。
- 价值:预测设备故障率,优化生产流程。
医疗健康监测
- 场景:可穿戴设备心率数据、医院HIS系统交互、基因测序结果收集。
- 挑战:敏感数据加密传输、跨区域合规存储(如GDPR)。
技术架构设计要点
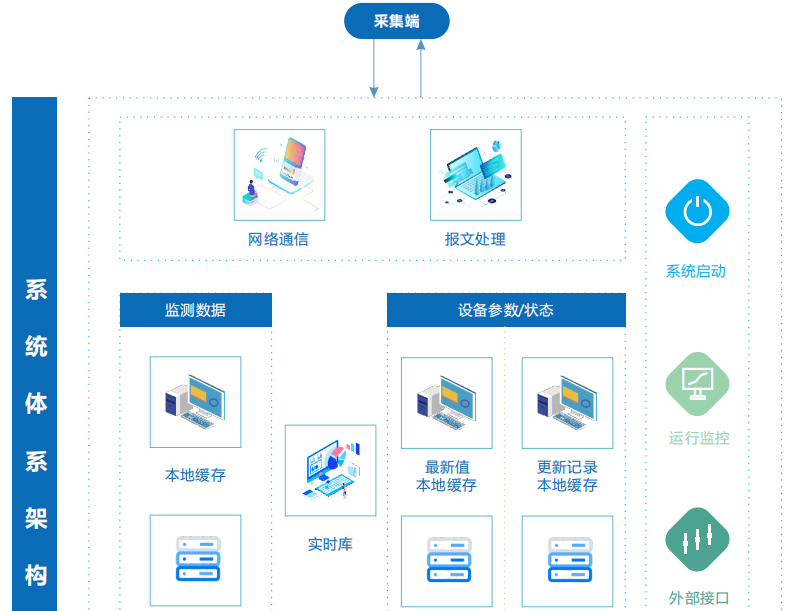
采集层
- 轻量化代理:在边缘设备部署轻量级Agent(如Filebeat、Telegraf),支持多协议适配。
- 负载均衡:采用一致性哈希算法分配采集任务,避免单点过载。
传输层
- 消息中间件:Kafka集群实现数据缓冲与分区,支持水平扩展。
- 压缩优化:使用Snappy/LZ4算法减少网络带宽占用。
处理层
- 流批一体:Flink/Spark Streaming实现实时计算,Hive/Spark SQL处理历史数据。
- 容错机制:Checkpoint与Savepoint保障计算状态恢复。
存储层
- 冷热分离:热数据存入Redis/Cassandra,冷数据归档至对象存储(如MinIO)。
- 索引优化:Elasticsearch构建倒排索引加速检索。
优势与挑战对比
| 维度 | 分布式系统优势 | 潜在挑战 |
|---|---|---|
| 扩展性 | 无缝添加节点,线性提升处理能力 | 数据分片策略设计复杂 |
| 可靠性 | 节点故障自动切换,数据多副本存储 | 网络分区导致一致性问题 |
| 实时性 | 端到端延迟可控制在百毫秒级 | 背压处理不当易引发数据积压 |
| 成本 | 按需使用云资源,避免过度配置 | 运维复杂度增加,需专业团队支持 |
关键技术选型参考
| 组件类型 | 主流技术栈 | 适用场景 |
|---|---|---|
| 消息队列 | Kafka、RabbitMQ、Pulsar | 高吞吐量日志采集 |
| 流处理引擎 | Flink、Spark Streaming、Beam | 实时数据分析与告警 |
| 存储系统 | HDFS、Ceph、Amazon S3 | 海量非结构化数据存储 |
| 协调服务 | ZooKeeper、Etcd | 分布式节点元数据管理 |
实施建议
- 分阶段部署:从单一业务线试点开始,逐步扩展到全域数据采集。
- 监控体系:集成Prometheus+Grafana实现链路可视化监控。
- 安全加固:TLS加密传输、RBAC权限模型、审计日志追踪。
FAQs
Q1:分布式数据采集系统适合哪些业务场景?
A1:适用于以下场景:
- 数据源分散且数量庞大(如全国连锁店监控数据);
- 需要实时处理并反馈(如金融风控、工业互联网);
- 存在高并发写入需求(如电商大促日志采集);
- 对系统可用性要求极高(如7×24小时基础设施监控)。
Q2:如何保障分布式采集中的数据一致性?
A2:可通过以下方案实现:
- 强一致性协议:采用Raft/Paxos算法确保元数据一致;
- 时间戳对齐:使用NTP服务同步各节点时钟;
- 事务管理:引入两阶段提交(2PC)保证跨节点操作原子性;
- 冲突检测:基于版本号或向量