上一篇
分布式数据采集系统可以干啥
分布式数据采集系统可实现多源数据并行采集、实时传输与预处理,支持横向扩展以应对海量数据场景,适用于物联网监测、工业设备运维、大数据分析等场景,有效提升
分布式数据采集系统是一种通过多节点协同工作实现大规模、高并发数据收集的技术架构,广泛应用于物联网、工业监控、金融交易、环境监测等领域,其核心价值在于突破传统单机系统的性能瓶颈,通过分布式设计提升数据采集的效率、可靠性和可扩展性,以下是其核心功能与应用场景的详细分析:

核心功能与技术架构
分布式数据采集系统通常由以下层级构成:
| 层级 | 功能描述 | 关键技术 |
|---|---|---|
| 采集层 | 负责从终端设备(传感器、日志、用户行为等)获取原始数据。 | MQTT、CoAP、HTTP/HTTPS、SDK集成 |
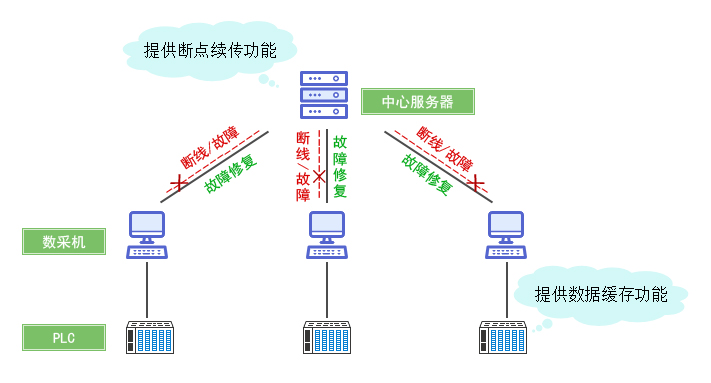
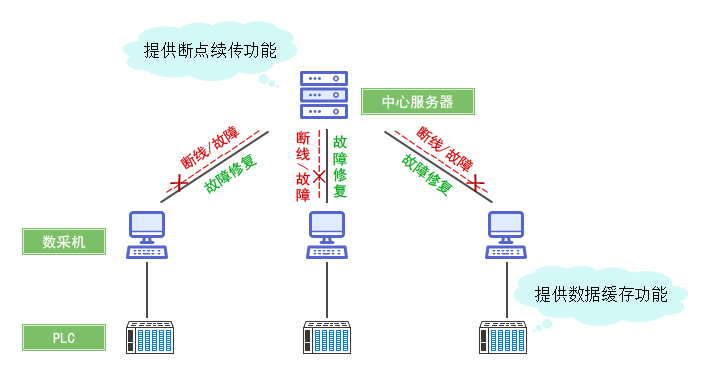
| 传输层 | 将数据高效传输至中心节点,支持负载均衡与断点续传。 | Kafka、RabbitMQ、gRPC、边缘计算节点 |
| 存储层 | 对海量数据进行持久化存储,支持结构化与非结构化数据。 | HDFS、时序数据库(InfluxDB)、NoSQL |
| 处理层 | 实时或离线清洗、转换、聚合数据,为下游业务提供可用数据。 | Spark、Flink、Storm、ETL工具链 |
典型应用场景
物联网(IoT)领域
- 场景:智慧城市中的交通流量监控、空气质量监测、智能水表/电表数据采集。
- 作用:通过分布在城市各处的传感器网络,实时采集环境参数、设备状态,并传输至云端进行分析,北京某智慧城市项目通过5000+传感器节点,每分钟采集超百万条数据,支撑交通拥堵预测和被墙源定位。
工业制造
- 场景:工厂设备状态监控、生产线质量检测、能耗管理。
- 作用:在大型制造企业中,通过PLC、振动传感器等设备实时采集设备运行数据,结合AI模型预测故障,某汽车工厂利用分布式系统采集10万台设备数据,将故障响应时间从小时级缩短至分钟级。
金融交易
- 场景:股票交易日志记录、支付流水监控、反欺诈行为分析。
- 作用:高频交易场景下,分布式系统可并行处理千万级交易订单,确保数据不丢失,某券商采用Kafka集群采集交易数据,峰值吞吐量达每秒百万条。
医疗健康
- 场景:可穿戴设备数据(如心率、血压)、医院设备日志(如CT机、呼吸机)。
- 作用:通过分布式架构整合多源医疗数据,辅助远程诊断,某省级医疗平台接入200家医院数据,实现患者历史病历的秒级查询。
电商与互联网
- 场景:用户行为日志(点击、浏览)、订单流水、广告曝光数据。
- 作用:支撑实时用户画像更新与精准推荐,某电商平台通过分布式日志系统每天处理PB级数据,将推荐算法响应时间优化至50ms内。
对比传统系统的显著优势
| 特性 | 传统单机系统 | 分布式数据采集系统 |
|---|---|---|
| 扩展性 | 依赖硬件升级,成本高 | 横向扩展节点,线性提升处理能力 |
| 容错性 | 单点故障导致服务中断 | 节点冗余设计,自动切换保证高可用 |
| 实时性 | 数据积压风险高 | 并行处理与流式计算,延迟低于秒级 |
| 成本 | 初期投入低,后期扩展难 | 按需扩容,长期边际成本递减 |
技术实现方案
数据采集工具
- 物联网协议:MQTT(轻量级)、CoAP(受限网络优化)。
- 日志采集:Flume(海量日志)、Logstash(ETL处理)。
- 流式传输:Apache Kafka(高吞吐)、RabbitMQ(消息队列)。
边缘计算优化
- 场景:在网络不稳定或带宽受限时(如油田、远洋船舶),通过边缘节点预处理数据,仅传输关键信息。
- 技术:NVIDIA Jetson、AWS Greengrass等边缘设备,结合轻量化AI模型(如TensorFlow Lite)。
存储与计算协同
- 时序数据:InfluxDB、TimescaleDB专为传感器数据设计,支持高效压缩与查询。
- 批处理:Hadoop生态(HDFS+MapReduce)适合离线分析。
- 流处理:Flink窗口计算、Spark Streaming实现实时聚合。
挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 数据一致性 | 使用分布式事务协议(如两阶段提交)或最终一致性架构。 |
| 网络延迟 | 部署边缘节点就近处理,结合数据压缩算法(如Snappy、LZ4)。 |
| 安全与隐私 | 传输层加密(TLS)、字段级脱敏、零信任架构访问控制。 |
| 运维复杂度 | 采用容器化部署(Docker+Kubernetes)、自动化监控工具(Prometheus+Grafana)。 |
行业应用案例
案例1:智能电网数据采集
- 背景:某省级电力公司需实时监控全省10万+变压器运行状态。
- 方案:部署分布式系统,通过4G/5G模块将电压、电流数据传输至边缘网关,异常数据秒级上报。
- 效果:故障定位时间缩短90%,年均减少停电损失超亿元。
案例2:跨境电商用户行为分析
- 背景:某平台需分析全球用户浏览路径以优化推荐算法。
- 方案:使用Kafka集群采集用户点击流,Flink实时计算热门商品榜单。
- 效果:推荐转化率提升35%,服务器资源利用率提高70%。
FAQs
Q1:分布式数据采集系统与集中式系统的核心区别是什么?
A1:集中式系统依赖单一服务器,存在性能上限和单点故障风险;分布式系统通过多节点协作,具备弹性扩展、高可用和低延迟特性,适合大规模数据处理。
Q2:如何评估企业是否需要引入分布式数据采集系统?
A2:若企业面临以下情况,建议考虑:
- 数据采集点超过1000个或日均数据量超GB级;
- 对实时性要求高(如秒级延迟不可接受);
- 业务需7×24小时不间断运行且无法容忍数据丢失。
可通过压力测试模拟峰值场景,验证