上一篇
分布式数据采集系统怎么玩
分布式数据采集系统通过多节点部署、数据传输同步、集中存储整合,结合负载均衡与容错
分布式数据采集系统的核心玩法解析
基础概念与核心目标
分布式数据采集系统(Distributed Data Collection System)是一种通过多节点协同工作,实现大规模、高并发、低延迟数据采集的架构,其核心目标是解决传统单机采集系统的三大瓶颈:性能上限、单点故障风险和扩展性不足,典型应用场景包括物联网设备监控、用户行为日志收集、金融交易数据抓取等。

系统架构设计要点
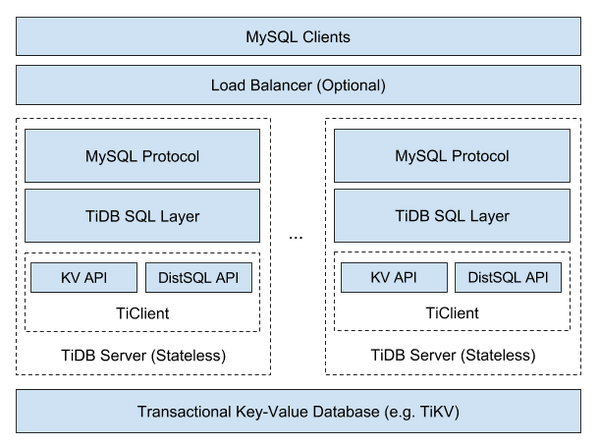
一个典型的分布式数据采集系统由以下模块构成:
| 模块层级 | 功能描述 | 关键技术选型 |
|---|---|---|
| 采集层 | 负责从数据源(设备、API、日志等)获取原始数据 | 轻量化Agent(如Filebeat、Telegraf)、SDK埋点 |
| 传输层 | 实现数据的可靠传输与缓冲 | 消息队列(Kafka、RabbitMQ)、gRPC |
| 处理层 | 数据清洗、格式转换、初步分析 | Flink、Spark Streaming、Logstash |
| 存储层 | 持久化存储与查询 | 时序数据库(InfluxDB)、Hadoop HDFS、Cassandra |
| 管理层 | 系统监控、任务调度、权限控制 | Prometheus、ZooKeeper、Kubernetes |
关键技术实现详解
数据分片策略
| 分片方式 | 适用场景 | 优缺点 |
|---|---|---|
| 哈希分片 | 均匀分布的海量数据 | 算法简单,但热点数据易导致负载不均 |
| 范围分片 | 时间序列或有序数据 | 便于范围查询,但需警惕数据倾斜 |
| 地理分片 | 物联网设备定位数据 | 降低网络延迟,但需集成GIS系统 |
传输可靠性保障
- 消息确认机制:采用至少一次(At-least-once)或精确一次(Exactly-once)语义,例如Kafka的ACK配置。
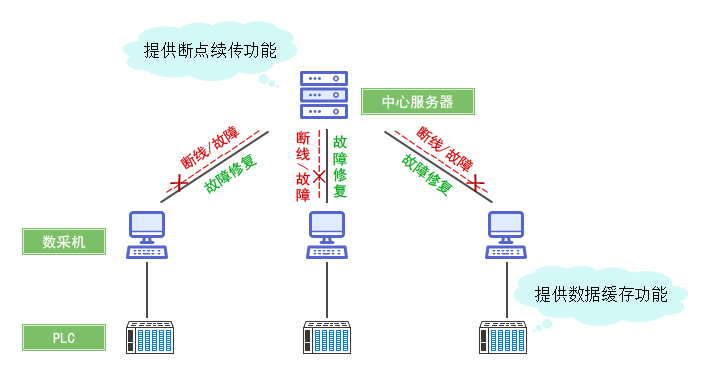
- 断点续传:通过记录偏移量(Offset)或检查点(Checkpoint),确保网络恢复后能继续传输。
- 流量控制:使用令牌桶算法或背压机制,防止突发流量冲击后端服务。
容错与高可用设计
- 节点冗余:采用Raft/Paxos协议实现元数据存储的多副本(如ZooKeeper集群)。
- 自动故障转移:结合监控系统(如Prometheus+Alertmanager),实现故障节点的自动剔除与替换。
- 数据副本策略:存储层采用3副本或EC纠删码(如Ceph),平衡存储效率与可靠性。
典型应用场景与案例
场景1:物联网设备监控
- 挑战:百万级设备并发上报,网络不稳定导致数据丢失。
- 解决方案:
- 边缘计算节点预处理数据,减少核心链路压力。
- 使用MQTT协议+Kafka集群实现分级缓冲。
- 时序数据库(如TDEngine)按设备ID分表存储。
场景2:电商用户行为分析
- 挑战:瞬秒活动期间峰值流量达百万TPS。
- 解决方案:
- 前端埋点SDK批量发送事件(冰山采样策略)。
- Kafka分区数动态扩缩容,配合ShardingSphere进行流量分发。
- 实时计算引擎(Flink)进行用户路径还原。
常见挑战与应对策略
| 问题类型 | 具体表现 | 解决方案 |
|---|---|---|
| 数据一致性 | 跨节点时钟偏差导致乱序 | 引入NTP同步+单调递增ID生成器 |
| 存储成本 | 冷数据长期占用高价存储 | 生命周期策略+冷热分层存储(如MinIO+HDFS) |
| 隐私合规 | 敏感数据泄露风险 | 端到端加密+差分隐私技术 |
实践优化建议
- 性能压测:使用JMeter或Gatling模拟千万级并发,定位系统瓶颈。
- 拓扑可视化:通过Graphviz绘制数据流向图,优化节点部署位置。
- 成本控制:混合云架构(私有云+公有云对象存储)降低边际成本。
FAQs
Q1:如何评估分布式数据采集系统的性能瓶颈?
A1:可通过以下步骤诊断:
- 链路分段测试:分别检测采集、传输、存储各环节的延迟与吞吐量。
- 资源监控:关注CPU、内存、磁盘IO和网络带宽的利用率(Prometheus+Grafana)。
- 压力测试:使用工具模拟极限场景,观察系统崩溃前的临界值。
- 慢日志分析:检查高频错误日志,定位代码级性能问题。
Q2:数据丢失零容忍场景下如何设计系统?
A2:需构建多级容灾机制:
- 采集端:本地缓存+双通道上传(如同时推送至Kafka和本地文件)。
- 传输层:开启Kafka的可靠投递(acks=all)并设置min.insync.replicas>1。
- 存储层:采用RAID10阵列+异地机房备份,启用写前日志(WAL)。
- 监控告警:对消息积压、磁盘剩余空间等指标