上一篇
分布式数据采集系统出现问题怎么解决
排查网络连通性,确认各节点状态正常;分析日志定位错误,检查数据一致性;重新平衡负载或修复故障节点,必要时回滚数据;优化扩展性设计,建立
分布式数据采集系统问题排查与解决方案
分布式数据采集系统因其高吞吐量、可扩展性等特点被广泛应用,但在实际运行中可能面临多种复杂问题,以下是针对常见问题的系统性分析与解决方案:
常见问题分类与解决框架
| 问题类型 | 典型表现 | 解决方向 |
|---|---|---|
| 数据丢失或重复 | 部分数据未到达下游、重复记录 | 检查传输可靠性、去重机制、存储一致性 |
| 延迟过高 | 数据采集到处理耗时过长 | 优化网络传输、压缩数据、提升计算资源 |
| 节点故障 | 部分采集节点离线或性能下降 | 节点健康检查、自动故障转移、负载均衡 |
| 数据不一致 | 不同节点采集的数据存在差异 | 时间同步、配置一致性校验、版本管理 |
| 资源瓶颈 | CPU/内存/磁盘IO占用率过高 | 资源扩容、限流策略、任务调度优化 |
| 网络分区 | 节点间通信中断、心跳超时 | 网络拓扑优化、重试机制、分布式协调 |
| 配置错误 | 任务参数不匹配、规则冲突 | 配置版本控制、动态加载、灰度发布 |
| 安全与权限问题 | 数据泄露、非规访问 | 加密传输、访问控制、审计日志 |
核心问题分析与解决方案
数据丢失或重复
原因分析:
- 网络抖动导致传输中断(如TCP连接意外关闭)
- 缓冲区溢出(如Kafka队列满未触发背压)
- 存储层写入失败(如磁盘故障、权限不足)
- 去重逻辑缺陷(如未正确生成唯一标识)
解决步骤:
检查传输链路:
- 使用
tcpdump或Wireshark抓包分析网络稳定性 - 验证ACK机制是否生效(如Kafka的确认机制)
- 启用重试策略(指数退避算法)
- 使用
优化缓冲区配置:
# 示例:调整Flume缓冲区大小 agent.sources.src.channels.ch.capacity = 100000 # 增大容量 agent.sources.src.channels.ch.transactionCapacity = 1000 # 单批处理量
实现幂等性设计:
- 使用UUID或哈希值作为数据唯一ID
- 下游存储层开启去重(如Elasticsearch的
_id字段)
延迟过高
原因分析:
- 批量处理间隔过大(如Logstash的flush周期)
- 网络带宽不足(如跨数据中心传输)
- 计算资源竞争(如共享CPU导致处理变慢)
解决步骤:
压缩与批量传输:
- 启用Snappy/LZ4压缩(如Kafka的
compression.type) - 调整批量大小(例如从1MB提升到5MB)
- 启用Snappy/LZ4压缩(如Kafka的
异步化处理:
// 示例:多线程并行处理 ExecutorService executor = Executors.newFixedThreadPool(4); for (DataBlock block : dataStream) { executor.submit(() -> process(block)); }资源隔离:

- 使用Docker容器限制CPU/内存(如
--cpus=2.0) - 部署专用采集节点(避免与渲染服务混部)
- 使用Docker容器限制CPU/内存(如
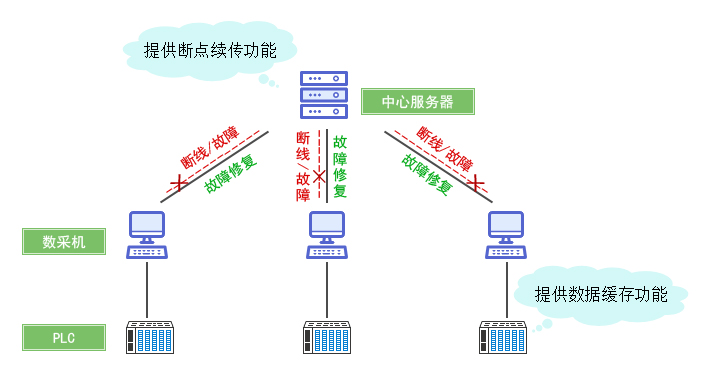
节点故障
原因分析:
- 硬件故障(如磁盘坏道、内存错误)
- 进程崩溃(如OOM Killer终止Java进程)
- 配置错误(如JVM堆内存设置过大)
解决步骤:
健康检查机制:
- 部署Consul/ZooKeeper实现心跳检测
- 设置Prometheus告警规则(如
node_exporter指标异常)
自动恢复策略:
# 示例:使用Supervisord管理进程 [program:data-collector] command=java -jar collector.jar autostart=true autorestart=true stderr_logfile=/var/log/collector.err.log
数据补偿机制:
- 记录已处理偏移量(如Kafka的
__consumer_offsets主题) - 新节点启动时从上次偏移续传
- 记录已处理偏移量(如Kafka的
数据不一致
原因分析:
- 时钟不同步(如NTP时间偏差)
- 配置版本混乱(如不同节点使用不同采集规则)
- 数据格式转换错误(如JSON解析失败)
解决步骤:
时间同步:
- 部署NTP Server并强制同步(
ntpd -q) - 添加时间戳签名(如
X-TimestampHTTP头)
- 部署NTP Server并强制同步(
配置管理:
- 使用Ansible/Puppet统一下发配置
- 版本化配置文件(如Git仓库管理)
数据校验:
# 示例:校验JSON完整性 import json def validate_data(record): try: json.loads(record) return True except ValueError: return False
网络分区
原因分析:
- 跨地域部署导致延迟过高(如中美之间的网络)
- 防火墙规则阻断端口(如Kafka的9092端口)
- DNS解析失败(如域名过期未续费)
解决步骤:
多活架构设计:
- 部署Regional Kafka集群(如华北、华东各一套)
- 使用Anycast IP实现就近接入
网络诊断工具:
ping测试基础连通性mtr分析网络路径稳定性ss -tuln检查本地监听端口
协调服务优化:
- ZooKeeper启用多机房部署(奇数节点原则)
- 调整Session超时时间(
zookeeper.session.timeout)
最佳实践与预防措施
监控体系:
- 关键指标:吞吐量(TPS)、延迟(P99)、错误率、磁盘利用率
- 工具链:Prometheus采集 + Grafana可视化 + Alertmanager告警
混沌工程:
- 定期模拟节点宕机(如Chaos Monkey)
- 进行流量压测(如JMeter生成百万级请求)
日志规范:
- 标准化日志格式(如JSON with fields: level, timestamp, component)
- 集中式日志存储(ELK Stack)
版本管理:
- 使用Helm管理K8s配置
- 建立配置变更审核流程
FAQs
Q1:如何预防分布式数据采集系统的单点故障?
A1:需从以下维度入手:
- 架构层面:部署至少3个ZooKeeper节点组成仲裁集群,Kafka分区副本数≥2且分布在不同机架。
- 服务层面:采用双活负载均衡(如Keepalived+HAProxy),关键组件启用主备模式。
- 数据层面:开启多区域复制(如跨AZ的S3存储),使用RAFT协议保证元数据一致。
Q2:如何快速定位数据丢失的具体环节?
A2:可通过以下步骤排查:
- 比对上下游偏移量:检查Kafka消费组的
consumer_lag是否持续增加。 - 分析日志时间戳:筛选出异常时间段的采集器日志(如
tail -f logs)。 - 数据抽样验证:抽取特征字段(如user_id)在各环节计数,定位缺失节点。
- 网络抓包确认:使用Wireshark过滤特定端口(如50051)查看g