上一篇
分布式数据采集系统是啥
分布式数据采集系统通过多节点协同采集数据,经网络传输至中心处理,实现高效可靠收集,适用于物联网、大数据分析等
分布式数据采集系统详解
分布式数据采集系统是一种通过多节点协同工作,实现大规模、高可靠性数据采集的架构,它通过分散部署的采集节点,将数据从不同源头(如传感器、日志、用户行为等)汇总到中心存储或处理平台,适用于物联网、工业互联网、大数据分析等场景,以下是其核心要素与技术解析:
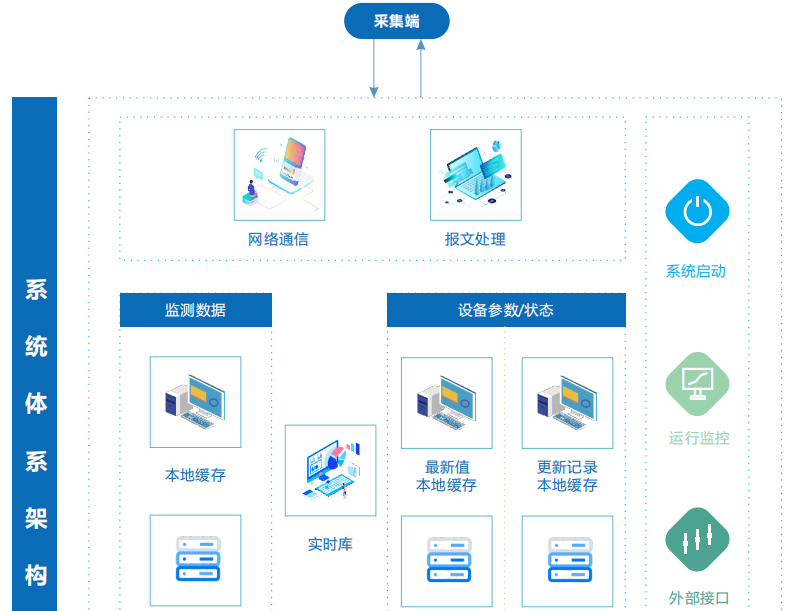
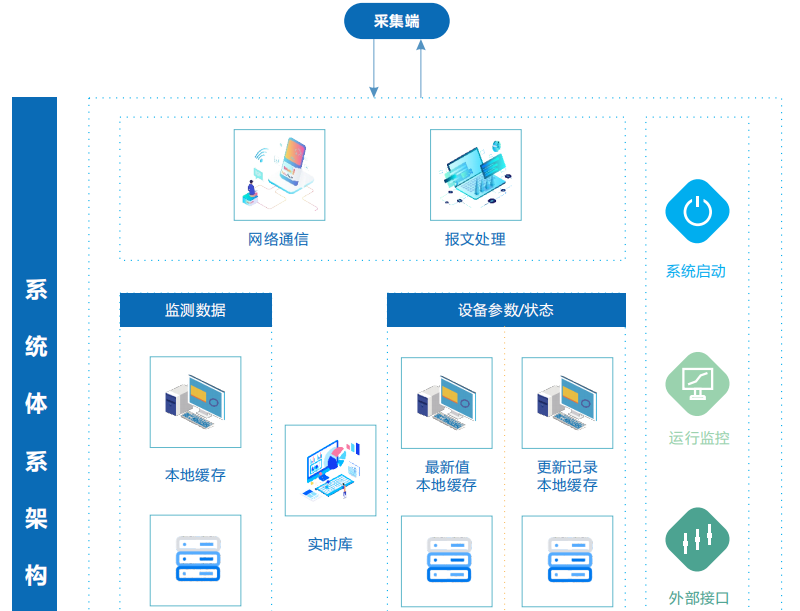
核心组件与架构
分布式数据采集系统通常由以下模块构成:
| 组件 | 功能描述 |
|——————-|—————————————————————————–|
| 采集节点 | 部署在数据源附近,负责实时采集数据(如温度传感器、日志文件、用户点击行为)。 |
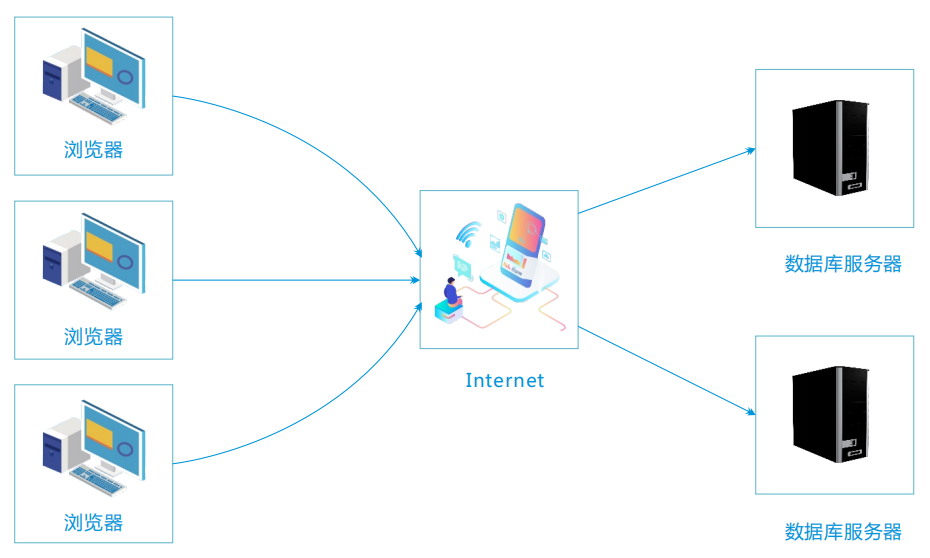
| 通信层 | 通过消息队列(如Kafka、RabbitMQ)或RPC框架(如gRPC)传输数据,支持异步处理。 |
| 存储层 | 将数据写入分布式数据库(如HBase、Cassandra)或数据湖(如HDFS、S3)。 |
| 协调层 | 管理节点任务分配、负载均衡(如ZooKeeper、Consul)。 |
| 管理监控层 | 监控系统状态、数据流量、故障告警(如Prometheus、Grafana)。 |
技术架构与流程
数据采集阶段
- 边缘计算:在靠近数据源的节点进行预处理(如过滤、压缩),减少传输带宽压力。
- 协议适配:支持多种通信协议(HTTP、MQTT、CoAP),适应不同设备类型(如IoT设备、服务器日志)。
数据传输阶段
- 消息队列:采用发布/订阅模式(如Kafka),实现数据的缓冲与异步传输。
- 负载均衡:动态分配任务到空闲节点,避免单点过载(如基于Consistent Hashing的分片策略)。
数据存储与处理

- 分布式存储:通过分片(Sharding)和副本机制(Replication)保证高可用性。
- 实时处理:结合流计算引擎(如Flink、Spark Streaming)进行实时分析。
关键技术对比
| 技术点 | 传统集中式系统 | 分布式系统 |
|---|---|---|
| 扩展性 | 依赖单机性能,扩展成本高 | 横向扩展,动态增减节点 |
| 容错性 | 单点故障导致全局中断 | 节点冗余,自动切换 |
| 延迟 | 低延迟,但受限于单机处理能力 | 可能因网络传输增加延迟,可通过边缘计算优化 |
| 成本 | 初期成本低,后期扩展昂贵 | 初期部署复杂,长期运维成本更低 |
典型应用场景
物联网(IoT)
- 场景:智慧城市中数万传感器采集温湿度、空气质量数据。
- 优势:边缘节点预处理数据,中心节点汇总分析,降低带宽压力。
金融交易监控
- 场景:实时采集全球交易所的订单数据,检测异常交易。
- 优势:分布式架构保障高吞吐量,避免数据丢失。
电商平台用户行为分析
- 场景:采集用户点击、浏览、购买日志,用于推荐模型训练。
- 优势:支持每秒百万级事件处理,实时更新用户画像。
工业设备监控
- 场景:工厂内数千台设备上传运行状态,预测故障。
- 优势:分布式采集降低网络延迟,保障数据连续性。
挑战与解决方案
网络延迟与带宽限制
- 问题:海量数据并发传输可能导致网络拥塞。
- 方案:
- 使用数据压缩算法(如Snappy、LZ4)减少传输量。
- 部署边缘节点,本地缓存数据后批量传输。
数据一致性
- 问题:分布式环境下可能出现数据重复或丢失。
- 方案:
- 采用幂等性设计(如唯一消息ID)。
- 使用分布式事务协议(如两阶段提交、Paxos算法)。
故障恢复
- 问题:节点宕机导致数据采集中断。
- 方案:
- 部署多副本机制(如Kafka的ISR列表)。
- 自动故障转移(如基于ZooKeeper的节点健康检查)。
未来发展趋势
- 云原生化:依托Kubernetes实现采集节点的弹性扩缩容。
- AI驱动:通过机器学习预测数据热点,动态优化资源分配。
- 边缘协同:结合5G技术,实现更低延迟的分布式采集。
FAQs
问题1:分布式数据采集系统与集中式系统的核心区别是什么?
- 答案:集中式系统依赖单一服务器处理所有数据,扩展性和容错性差;分布式系统通过多节点协作,具备高可用性、弹性扩展能力,适合大规模数据采集场景。
问题2:如何判断业务是否需要分布式数据采集?
- 答案:若业务满足以下条件之一,建议采用分布式架构:
- 数据源分散且数量庞大(如全国IoT设备)。
- 需要高可用性(如金融、电商核心业务)。
- 数据峰值明显(如促销活动