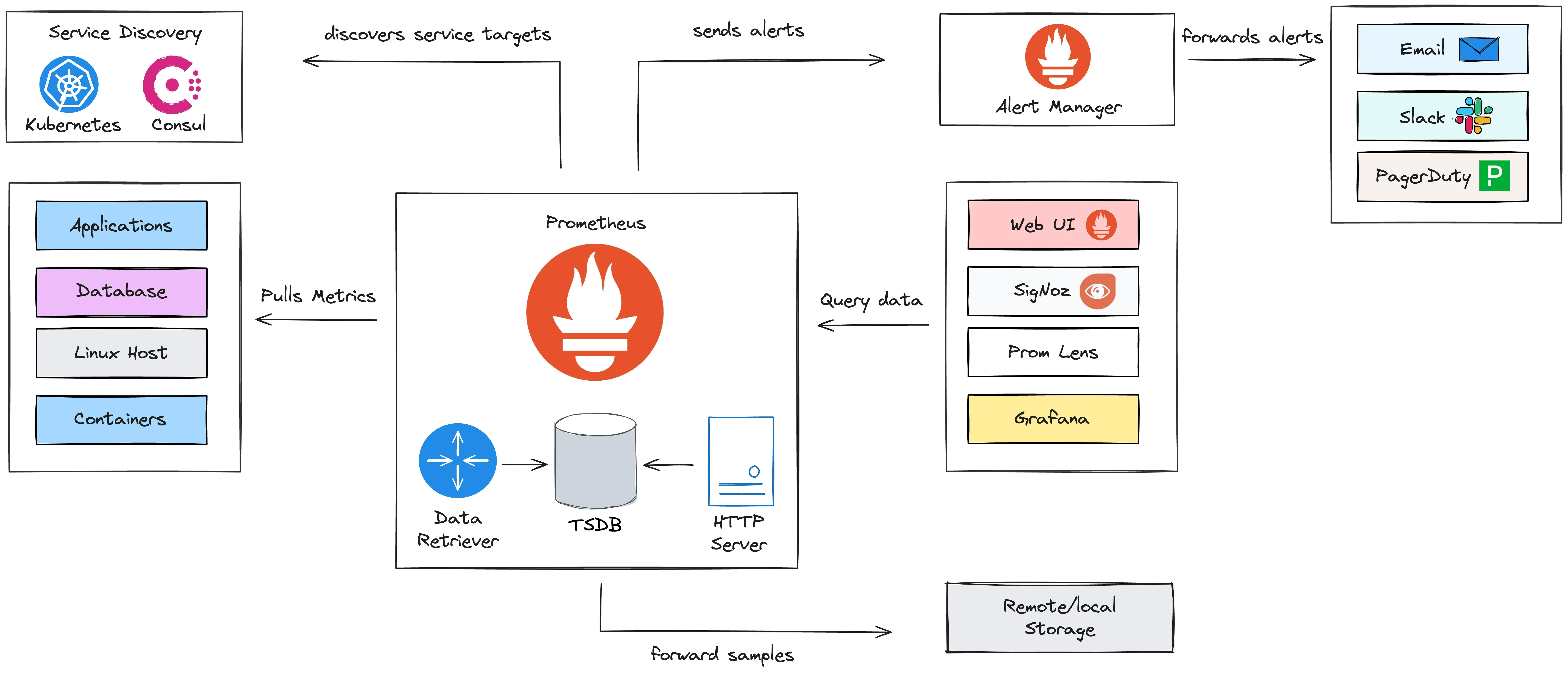
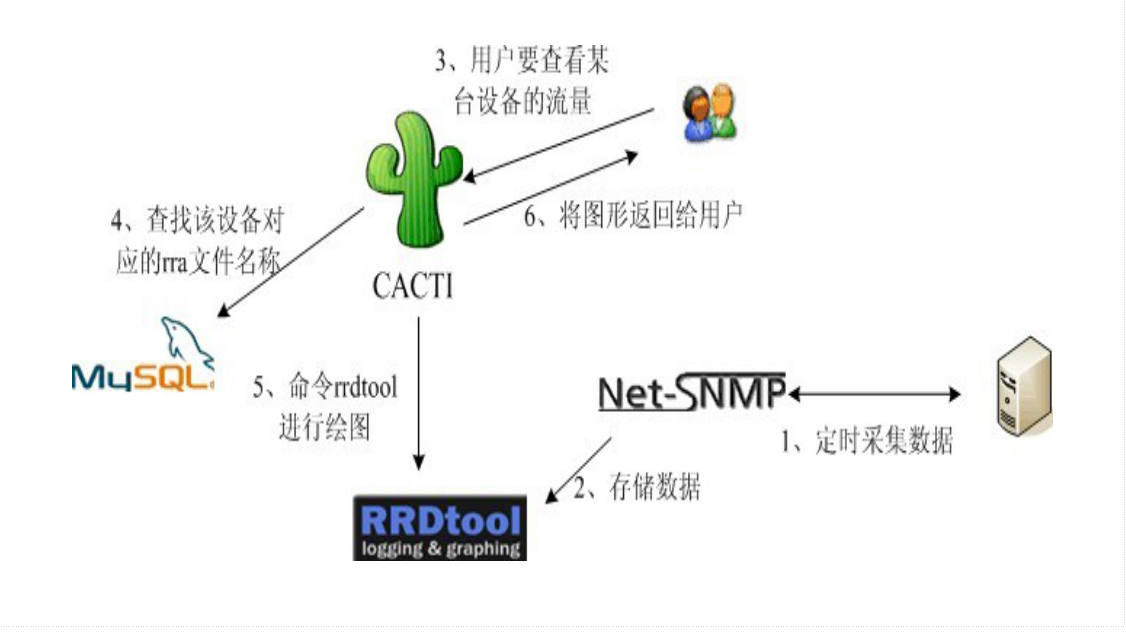
上一篇
分布式数据采集系统用来干嘛
分布式数据采集系统用于跨多节点协同采集海量数据,实现实时汇聚与预处理,支撑大数据分析、物联网监测及分布式存储
分布式数据采集系统的核心功能与应用场景解析
分布式数据采集系统的定义
分布式数据采集系统是一种通过多节点协同工作,从不同数据源(如传感器、设备、日志、网络流量等)高效收集、传输、处理和存储数据的架构,其核心目标是解决大规模、高并发、异构数据环境下的实时性、可靠性和可扩展性问题,与传统集中式采集系统相比,分布式系统通过分散计算和存储资源,避免了单点性能瓶颈,同时提升了容错能力和数据处理效率。
核心功能与技术架构
分布式数据采集系统的功能可拆解为以下模块:
| 模块 | 功能描述 | 关键技术 |
|---|---|---|
| 数据采集层 | 从多源异构设备(如传感器、数据库、API接口)实时获取数据。 | 协议适配(MQTT、HTTP、TCP/IP)、边缘计算 |
| 数据传输层 | 将采集的数据通过可靠网络传输至后端处理节点,支持断点续传和流量控制。 | MQTT、Kafka、gRPC、边缘代理 |
| 数据处理层 | 对原始数据进行清洗、过滤、聚合或预分析,降低后端存储和计算压力。 | Flink、Spark Streaming、Redis Stream |
| 数据存储层 | 将处理后的数据持久化存储,支持结构化(数据库)和非结构化(时序数据库、HDFS)数据。 | Cassandra、InfluxDB、HBase、对象存储(如S3) |
| 应用管理层 | 提供数据查询、可视化、告警和API服务,支持业务系统调用。 | Grafana、Elasticsearch、RESTful API |
为什么需要分布式数据采集?
应对海量数据
- 场景:工业物联网(IIoT)中,单个工厂可能有数万台设备,每秒产生上千条数据。
- 分布式优势:通过边缘节点就近采集和预处理,减少中心节点压力,避免网络带宽瓶颈。
高可用性与容错
- 场景:智能电网监测系统中,部分节点故障可能导致区域数据丢失。
- 分布式优势:采用冗余备份和自动故障转移机制,确保数据不中断。
低延迟实时处理
- 场景:金融交易监控系统需在毫秒级内分析异常交易。
- 分布式优势:数据就近处理(边缘计算),减少传输延迟。
灵活扩展
- 场景:电商平台促销活动期间,流量激增导致数据采集需求翻倍。
- 分布式优势:通过动态添加节点实现横向扩展,无需停机改造。
典型应用场景
| 领域 | 需求特点 | 分布式系统价值 |
|---|---|---|
| 工业物联网 | 设备类型多、数据频率高、网络环境复杂 | 边缘节点预处理数据,降低云端负载 |
| 智能城市 | 覆盖范围广(交通、环保、安防等多系统) | 多协议兼容,统一数据汇聚与分析 |
| 金融风控 | 实时性要求极高,数据需秒级响应 | 分布式流处理(如Kafka+Flink)实现实时预警 |
| 医疗健康监测 | 数据敏感度高,需高可靠性和隐私保护 | 数据加密传输,多副本存储确保安全 |
技术挑战与解决方案
数据一致性问题
- 挑战:分布式环境下,不同节点的数据可能因网络延迟或故障导致同步偏差。
- 方案:采用分布式事务协议(如两阶段提交)、时间戳对齐或最终一致性模型。
网络带宽与延迟
- 挑战:大规模数据传输可能占用过多带宽,影响实时性。
- 方案:数据压缩(如Snappy、LZ4)、边缘节点数据过滤、分块传输。
故障恢复与容错
- 挑战:节点宕机或网络分区可能导致数据丢失。
- 方案:数据副本机制(如Kafka的副本因子)、心跳检测与自动切换。
未来发展趋势
- 边缘计算与AI融合:在边缘节点部署轻量化AI模型,实现实时数据分类和异常检测。
- 云原生架构:基于Kubernetes的容器化部署,提升资源利用率和弹性。
- 隐私保护增强:通过联邦学习、差分隐私等技术,在数据采集过程中保障用户隐私。
FAQs
Q1:分布式数据采集系统与集中式系统的核心区别是什么?
- A:集中式系统依赖单一中心节点处理所有数据,存在性能瓶颈和单点故障风险;分布式系统通过多节点协同,实现负载均衡、高可用和横向扩展,更适合大规模、高并发场景。
Q2:如何选择合适的分布式数据采集框架?
- A:需根据业务需求评估:
- 实时性要求:高实时场景可选Apache Kafka+Flink;
- 数据规模:EB级数据推荐Hadoop生态(HDFS+Flume);
- 边缘计算需求:选择支持边缘代理的设备适配层(如Edge