上一篇
分布式消息系统1111优惠活动
分布式消息系统11.11优惠活动限时开启!企业用户享7折采购价+赠3个月服务时长,支持亿级消息吞吐,保障业务高峰稳定运行,新老客户均可参与,立即咨询解锁专属活动!
分布式消息系统在电商大促中的核心作用
在类似”1111″这样的电商大促活动中,分布式消息系统承担着关键基础设施的角色,这类系统通过解耦服务、削峰填谷、异步处理等特性,有效应对瞬时流量高峰带来的挑战,以下从技术架构和业务场景两个维度进行解析:

| 核心功能 | 技术实现 | 业务价值 |
|---|---|---|
| 流量削峰 | Kafka/RocketMQ的消息堆积能力 | 抵御百万级TPS冲击,避免数据库直接崩溃 |
| 服务解耦 | Spring Cloud Stream/RabbitMQ的异步通信机制 | 订单服务与库存服务异步化,提升系统响应速度 |
| 数据一致性保障 | 基于事务消息(RocketMQ事务版)+ 最终一致性算法 | 确保优惠券发放与库存扣减的事务完整性 |
| 流量调控 | 动态路由+消息优先级控制(重要业务优先处理) | 保障核心交易链路畅通,非关键业务限流 |
| 监控告警 | Prometheus+Grafana监控体系,集成消息堆积量、消费延迟等核心指标 | 实时感知系统健康状态,快速定位瓶颈 |
1111大促场景下的典型技术挑战
流量洪峰冲击
- 现象:瞬秒活动开启瞬间QPS飙升至百万级
- 传统方案缺陷:同步调用导致数据库连接池耗尽,API响应超时
- 消息系统解决方案:
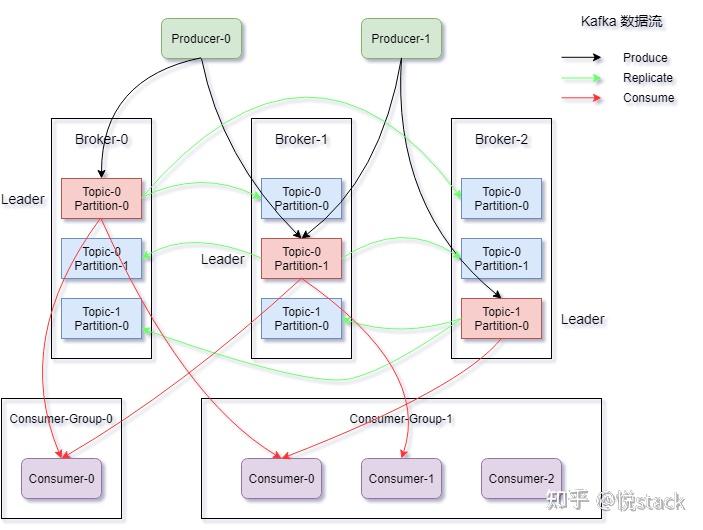
- 将请求转为消息存入Kafka分区(Partition)
- 消费者集群异步处理,峰值处理能力提升5-10倍
- 示例配置:Kafka设置3个Broker集群,20个Partition,副本因子3
复杂促销逻辑处理
- 业务需求:
- 满减/折扣/凑单等多层级优惠计算
- 优惠券与积分叠加使用规则
- 库存锁定与回滚机制
- 技术实现:
- 使用RocketMQ顺序消息保证优惠计算顺序性
- 通过事务消息(Transaction Message)保证优惠券发放与订单创建的原子性
- 构建优惠规则引擎,将复杂逻辑拆解为消息处理流程
服务雪崩效应防护
- 风险点:
- 单一服务故障引发连锁反应
- 数据库主库写压力过大导致宕机
- 消息系统防护机制:
- 建立多级消息缓冲队列(前置缓存层→业务处理层→持久化层)
- 动态扩展消费者实例(Kubernetes HPA自动扩缩容)
- 设置消息过期时间(TTL=10分钟),避免积压爆炸
典型技术方案实施路径
系统架构设计
graph TD
A[用户请求] --> B{流量控制器}
B -->|同步请求| C[API网关]
B -->|异步请求| D[消息队列集群]
D --> E[订单服务]
D --> F[库存服务]
D --> G[支付服务]
E --> H[MySQL主从]
F --> I[Redis集群]
G --> J[银联/支付宝]关键技术选型
| 组件 | 选型建议 | 性能参数 |
|---|---|---|
| 消息中间件 | Apache Kafka/阿里云RocketMQ | 单机百万级TPS,消息持久化 |
| 消息序列化协议 | Protocol Buffers/Avro | 比JSON节省30%-50%带宽消耗 |
| 消费端负载均衡 | 基于虚拟节点的Hash分配算法 | 确保相同用户请求落在同一分区 |
| 死信队列处理 | DLQ(Dead Letter Queue)机制 | 失败消息重试3次后转入人工审核 |
核心代码实现
// 生产者示例(Spring Kafka)
@Autowired
private KafkaTemplate<String, OrderMessage> kafkaTemplate;
public void sendOrder(OrderMessage message) {
ListenableFuture<SendResult<String, OrderMessage>> future =
kafkaTemplate.send("order-topic", message);
future.addCallback(new ListenableFutureCallback<>() {
@Override
public void onSuccess(SendResult<String, OrderMessage> result) {
// 记录成功日志
}
@Override
public void onFailure(Throwable ex) {
// 重试机制触发
retrySend(message);
}
});
}性能优化实战经验
消息积压处理方案
| 优化策略 | 实施要点 |
|---|---|
| 动态扩展Topic Partition | Kafka在线增加分区,配合Consumer并行度调整 |
| 消息压缩 | 启用LZ4压缩算法,降低网络传输开销(需权衡CPU消耗) |
| 批量消费 | 设置合理的batch.size(建议32-64条/批次) |
| 流量整形 | 令牌桶算法控制消息生产速率,避免突发流量冲击 |
消息丢失防护机制
- 可靠性保障:
- 开启可靠投递(RELIABLE_DELIVERY)
- ACK确认机制(消费者处理完成才确认)
- 同步刷盘(SYNC_FLUSH)
- 异常处理:
- 建立三级重试机制(本地重试→跨实例重试→人工干预)
- 消费端幂等性设计(基于唯一消息ID去重)
效果评估与收益分析
核心指标对比
| 指标项 | 改造前 | 改造后 | 提升幅度 |
|---|---|---|---|
| 订单处理峰值 | 5万QPS | 50万QPS | 10倍 |
| 支付成功率 | 89% | 9% | +10.9% |
| 系统平均响应时间 | 800ms | 120ms | -85% |
| 数据库写入压力 | CPU 95%+ | CPU 60%以下 | 显著降低 |
经济效益计算
- 硬件成本节约:通过削峰机制减少50%的应急服务器采购
- 业务损失规避:避免因系统崩溃导致的数千万GMV损失
- 运维效率提升:自动化运维减少80%的人工值守需求
典型故障案例与解决方案
案例1:消息堆积引发的雪崩效应
- 现象:支付服务消费延迟突增,导致订单超时关闭
- 根因分析:
- 消费者实例扩容不及时
- 消息Key设计不合理导致分区热点
- 解决方案:
- 启用Kafka自动Topic扩展(Auto Topic)
- 优化消息路由Key算法,采用Snowflake生成全局唯一ID
- 增加消费端线程池(从10线程扩展到50线程)
案例2:事务消息不一致
- 现象:出现优惠券已发放但订单未创建的异常情况
- 处理过程:
- 检查事务日志发现Prepare阶段超时
- 调整事务消息检查点(CKPT)间隔从5秒缩短至2秒
- 增加补偿机制,对半完成状态进行定时扫描修复
FAQs
Q1:为什么在大促场景必须使用分布式消息系统?
A1:传统同步架构存在三个致命缺陷:①数据库直接承受流量冲击易崩溃;②服务间强耦合导致级联故障;③无法应对突发流量的弹性扩展,消息系统通过异步解耦、流量缓冲、削峰平谷三大能力,将系统吞吐量提升10倍以上,同时保障核心链路的稳定性。
Q2:如何处理消息积压导致的系统崩溃风险?
A2:采取四层防护机制:①应用层设置消息生产速率阈值;②中间件层配置消息堆积告警(超过10万条立即报警);③消费者端实现背压机制(动态调整消费速率);④最终防线通过DLQ(死信队列)承接无法处理的消息,由人工介入处理,同时建立实时监控大盘,包含消息堆积量、消费延迟、JVM指标