上一篇
hive数据仓库mysql
Hive为大数据仓储,依托Hadoop处理海量数据;MySQL系传统关系库,适OLTP,二者于数据规模、架构
Hive数据仓库与MySQL的深度解析与对比
基础概念与核心特性
| 特性 | Hive数据仓库 | MySQL关系数据库 |
|---|---|---|
| 定位 | 大数据批处理分析引擎 | OLTP(在线事务处理)系统 |
| 架构基础 | 基于Hadoop生态(HDFS存储+MapReduce计算) | 传统单机/主从架构 |
| 数据模型 | 类SQL语义(HiveQL),支持动态分区 | 严格关系模型(ACID事务) |
| 存储格式 | 文本/SequenceFile/ORC/Parquet | InnoDB(行式存储) |
| 延迟 | 分钟级(复杂查询) | 毫秒级(实时响应) |
| 扩展性 | 横向扩展(依赖HDFS/YARN) | 纵向扩展(硬件升级) |
| 典型场景 | ETL批处理、离线分析、数据湖治理 | 高并发事务、实时业务系统 |
架构设计与运行机制
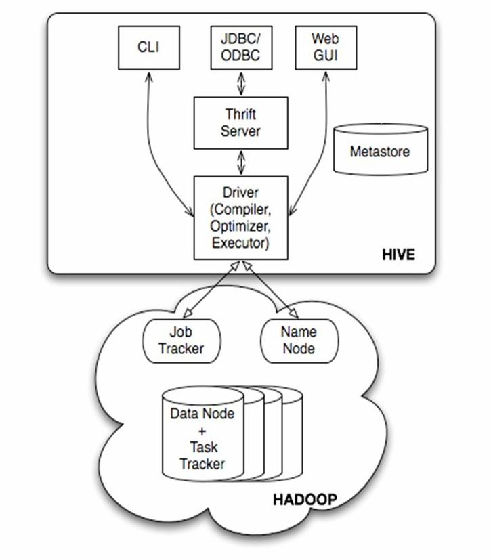
Hive核心组件
- Metastore:元数据管理(表结构/分区信息),默认使用内嵌Derby数据库,可对接MySQL/PostgreSQL
- Driver:解析HiveQL生成执行计划
- Execution Engine:调用MapReduce/Tez/Spark执行任务
- SerDe:序列化/反序列化框架(如JSON、Avro支持)
MySQL关键模块
- InnoDB存储引擎:支持事务(ACID)、行级锁、MVCC
- Query Optimizer:基于成本的优化器(CBO)
- Binary Log:实现主从复制与数据恢复
- Index System:B+树索引、全文索引(InnoDB/MyISAM)
数据交互与集成方案
数据导入导出工具
| 工具 | 功能 | 命令示例 |
|————|—————————————|—————————————|
| Sqoop | MySQL ↔ Hive批量传输 | sqoop import --connect jdbc:mysql://... --table user_log --target-dir /hive/warehouse/logs |
| Load Data | 本地文件加载到Hive表 | LOAD DATA INPATH '/tmp/user_data.csv' INTO TABLE user_dim |
| INSERT | MySQL数据写入Hive表 | INSERT OVERWRITE TABLE hive_table SELECT FROM mysql_table |

混合架构实践
- 维度表存储:将MySQL中的用户/商品维度表同步至Hive,通过
PARTITIONED BY按日期分区 - 事实表处理:日志/交易事实表存储于Hive ORC格式,开启Snappy压缩
- 临时数据交换:使用MySQL暂存ETL中间结果,通过
UNION ALL合并多日数据
性能优化策略对比
| 优化维度 | Hive优化方案 | MySQL优化方案 |
|---|---|---|
| 存储层 | ORC格式+Snappy压缩、开启列式存储 | 建立聚簇索引、拆分大字段(TEXT→BLOB) |
| 计算引擎 | Tez替代MapReduce、LLAP缓存 | 查询缓存(query_cache=true) |
| 数据分区 | 按业务时间/地域分区、虚拟列bucket分区 | 水平分表(user_1~user_100) |
| 资源调优 | 调整mapreduce.job.reduces参数 | 调整innodb_buffer_pool_size |
| 索引策略 | 创建BITMAP索引加速过滤 | 联合索引(idx_order_uid_time) |
典型应用场景对比
Hive优势场景
- PB级日志分析(如电商用户行为分析)
- 历史数据归档与深度挖掘
- 复杂多表关联分析(JOIN over 10+ tables)
- 机器学习特征工程(Spark on Hive)
MySQL优势场景
- 高并发订单处理(如瞬秒系统)
- 实时库存更新与查询
- 用户认证与权限管理
- 毫秒级响应的BI报表前端服务
常见问题与解决方案
FAQs
Q1:如何判断业务应该用Hive还是MySQL?
A:评估三个维度:①数据量(GB级以下用MySQL,TB+用Hive);②实时性(毫秒级选MySQL,分钟级容忍可用Hive);③操作类型(频繁DML选MySQL,只读分析选Hive),例如用户画像更新适合MySQL,而历史订单分析适合Hive。
Q2:如何实现Hive与MySQL的实时同步?
A:方案一:使用Apache NiFi构建数据管道,通过ExecuteSQLRecord处理器捕获MySQL binlog变更,实时写入Kafka,最终由Hive消费;方案二:部署Debezium+Kafka Connect,配置CDC(Change Data Capture)到Hive Icedberg表,注意需开启MySQL的row-level binlog并设置