上一篇
hive数据仓库原理和架构
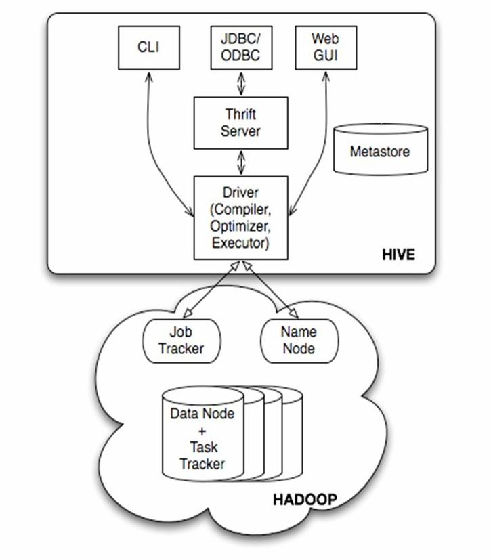
Hive基于Hadoop,将SQL转为MapReduce处理HDFS数据,架构含Client、MetaStore(存元数据)及Execution Engine,支持OLAP批处理
Hive数据仓库核心原理
Hive是基于Hadoop生态系统的分布式数据仓库工具,其核心原理是通过类SQL语言(HiveQL)将数据查询任务转换为MapReduce作业,从而实现对大规模数据的分析和处理,以下是其关键原理:
SQL语义解析与编译
- Hive通过
Parser模块解析用户提交的HiveQL语句,生成抽象语法树(AST)。 Semantic Analyzer对AST进行语义分析,包括表名、字段名校验、权限验证等。Logical Plan阶段将AST转换为逻辑执行计划,例如筛选条件、连接顺序等。Optimizer模块对逻辑计划进行优化,例如谓词下推、列裁剪等,减少数据扫描量。
物理执行计划生成
- 逻辑计划被转换为可执行的物理计划(
Physical Plan),例如将JOIN操作映射为MapReduce任务。 - Hive支持多种执行引擎,如MR、Tez、Spark,用户可通过参数配置选择。
元数据管理
- Hive的元数据(表结构、分区信息、存储位置等)存储在关系型数据库(如MySQL、PostgreSQL)中。
MetaStore服务负责管理元数据,客户端通过MetaStore获取表信息、分区列表等。
数据存储与格式
- Hive默认基于HDFS存储数据,支持多种文件格式(如TextFile、ORC、Parquet)。
- 分区(Partition):按指定字段划分数据目录,提升查询效率。
- 桶(Bucket):将数据均匀分配到多个桶中,支持基于哈希的采样查询。
Hive架构分层设计
Hive架构分为以下核心组件,各组件协同工作完成数据存储与查询任务:

| 组件 | 功能描述 |
|---|---|
| Client Interface | 提供命令行(CLI)、JDBC/ODBC接口、Thrift API,供用户提交查询或管理任务。 |
| MetaStore | 存储Hive元数据(表结构、分区信息、权限等),依赖外部数据库(如MySQL)。 |
| Driver | 负责编译HiveQL语句,生成执行计划,并提交给执行引擎。 |
| Compiler | 包括解析器、语义分析器、优化器,将HiveQL转换为可执行的逻辑计划和物理计划。 |
| Execution Engine | 执行物理计划,调用底层计算框架(如MR、Tez、Spark)处理数据。 |
| HDFS/Storage | 实际存储Hive表数据,支持水平扩展,通过分区和桶实现高效数据组织。 |
Hive数据存储结构
Hive的存储结构设计以“分区+桶”为核心,结合文件格式优化查询性能:
表类型
| 表类型 | 特点 |
|---|---|
| 内部表 | 数据存储在Hive指定的HDFS路径,删除表时数据一并删除。 |
| 外部表 | 数据路径由用户指定,删除表仅删除元数据,保留数据。 |
分区与桶
- 分区(Partition):按字段值划分目录(如
dt=2023-10-01),查询时可跳过无关分区。 - 桶(Bucket):将数据哈希分配到多个桶中,支持高效
JOIN和采样查询。
文件格式对比
| 格式 | 优点 | 缺点 |
|---|---|---|
| TextFile | 兼容性好,简单易用。 | 无压缩,存储空间大,解析慢。 |
| ORC | 高压缩比,支持列式存储,查询效率高。 | 需要依赖ORC库,兼容性较差。 |
| Parquet | 列式存储,支持复杂数据类型,广泛兼容。 | 写入性能略低。 |
Hive执行流程示例
以一条SELECT查询为例,执行流程如下:
- 客户端提交查询:通过CLI或API提交HiveQL语句。
- 语法解析与优化:
Parser解析语句,Optimizer优化逻辑计划。 - 生成执行计划:将逻辑计划转换为MapReduce/Tez/Spark任务。
- 元数据检索:从
MetaStore获取表结构、分区列表。 - 数据扫描与处理:执行引擎读取HDFS数据,按计划完成计算。
- 结果返回:将计算结果返回给客户端或存入文件。
Hive性能优化策略
| 优化方向 | 具体方法 |
|---|---|
| 数据组织 | 合理设计分区字段,避免过多小分区;使用桶表加速JOIN。 |
| 文件格式 | 优先选择ORC/Parquet格式,开启压缩(如Snappy)减少IO。 |
| 执行引擎 | 使用Tez或Spark替代MapReduce,提升任务调度效率。 |
| 资源配置 | 调整Map/Reduce任务数,优化YARN资源分配(内存、并发)。 |
FAQs
问题1:Hive与传统关系型数据库(如MySQL)的核心区别是什么?
- 回答:
Hive专为大规模数据处理设计,基于HDFS存储,支持PB级数据;而MySQL是OLTP系统,适用于高并发事务,Hive使用HiveQL(类SQL),查询延迟较高(分钟级),而MySQL支持实时查询,Hive依赖分布式计算框架(如MR),无事务支持(Hive 3.0后部分支持),而MySQL具备ACID特性。
问题2:如何优化Hive查询性能?
- 回答:
- 分区裁剪:确保查询条件包含分区字段,避免全表扫描。
- 列式存储:使用ORC/Parquet格式,减少无关列的IO开销。
- 并行执行:启用
parallel参数,充分利用集群资源。 - 数据倾斜处理:对KEY分布不均的字段进行预处理(如盐值打散)。
- 缓存中间结果:对频繁使用的中间表开启
CACHE提示,减少重复