上一篇
分布式数据采集系统发生故障怎么办
分步排查网络、节点状态,隔离故障模块,恢复
分布式数据采集系统发生故障怎么办?
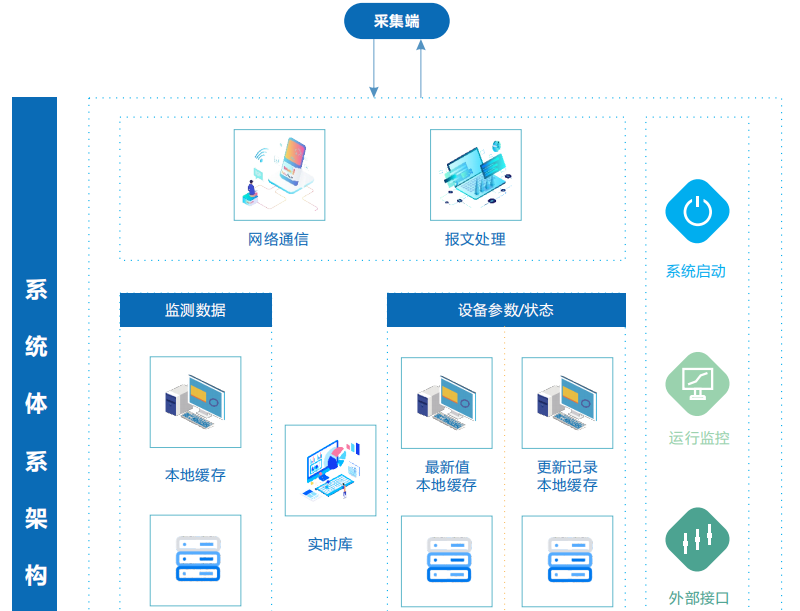
分布式数据采集系统因其高可用性和可扩展性被广泛应用,但在实际运行中仍可能因网络、硬件、软件等问题出现故障,以下是一套系统性的故障处理方案,涵盖故障检测、定位、解决、恢复及预防措施,帮助快速恢复系统并降低影响。
故障检测与初步判断
监控系统告警
- 通过Prometheus、Zabbix等监控工具实时采集系统指标(CPU、内存、网络延迟、数据吞吐量等),设置阈值触发告警。
- 示例告警场景:
- 某节点数据写入速率骤降50%以上
- 心跳包丢失超过设定时间(如30秒)
- 磁盘使用率超过90%
日志分析

- 集中查看各节点日志(如ELK Stack),关注错误关键词:
TimeoutException(网络超时)OutOfMemoryError(内存溢出)DataConsistencyException(数据一致性错误)
- 使用日志分级(ERROR/WARN/INFO)快速定位关键问题。
- 集中查看各节点日志(如ELK Stack),关注错误关键词:
数据流健康检查
- 验证数据链路完整性:
- 输入端:检查传感器、API接口是否正常推送数据
- 中间传输:确认消息队列(如Kafka、RabbitMQ)是否积压
- 存储端:验证数据库(如HBase、Cassandra)是否可写
- 验证数据链路完整性:
故障定位与分类
| 故障类型 | 典型表现 | 可能原因 |
|---|---|---|
| 网络故障 | 节点间通信超时、数据包丢失 | 物理链路中断、防火墙规则、负载均衡器故障 |
| 节点故障 | 单节点离线、服务不可用 | 硬件宕机、进程崩溃、内存泄漏 |
| 数据一致性故障 | 重复数据、数据缺失、时序错乱 | 时钟同步问题(如NTP不准确)、主从库延迟 |
| 资源耗尽 | CPU/内存/磁盘100%使用率 | 流量突发、内存泄漏、磁盘配额不足 |
| 配置错误 | 任务调度失败、数据路由异常 | 配置文件错误、版本不兼容、参数阈值设置不当 |
分场景解决方案
网络故障处理
- 步骤1:验证网络连通性
- 使用
ping和telnet测试节点间端口连通性(如RPC端口、数据库端口)。 - 检查防火墙规则是否阻止关键端口(如2181/Kafka、9092/RocketMQ)。
- 使用
- 步骤2:切换网络路径
- 若使用多机房部署,临时切换到备用网络链路。
- 调整负载均衡器策略(如Nginx健康检查频率)。
- 步骤3:重启网络服务
# 重启网卡驱动(以Linux为例) systemctl restart network-manager # 清除TCP连接队列积压 sysctl -w net.ipv4.tcp_max_orphans=4096
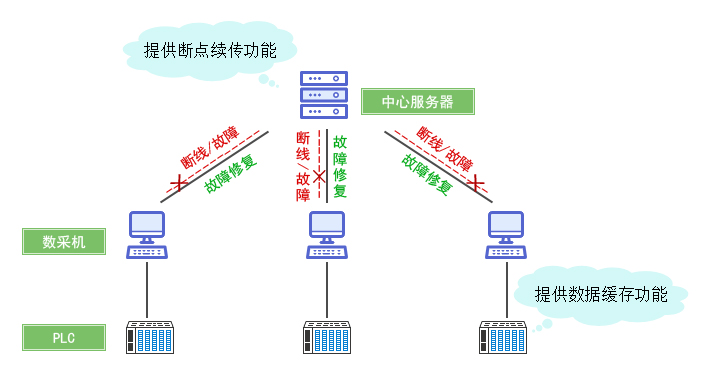
单节点故障恢复
- 步骤1:节点隔离
通过ZooKeeper/Etcd等协调服务标记故障节点,停止向其分配新任务。
- 步骤2:故障诊断
- 检查进程状态:
ps -ef | grep collector - 分析内存转储文件(如
/var/crash/)。
- 检查进程状态:
- 步骤3:快速恢复
- 自动重启机制:通过Systemd/Supervisord配置自启策略。
- 数据补偿:从消息队列中重新消费未完成的数据分片。
数据一致性修复
- 时间同步问题
- 强制所有节点同步NTP时间服务器:
ntpdate -u pool.ntp.org
- 强制所有节点同步NTP时间服务器:
- 主从库数据修复
- 使用工具(如Percona Toolkit)对比主从库差异并修复:
pt-table-checksum --repair --no-check-replication-filters
- 使用工具(如Percona Toolkit)对比主从库差异并修复:
- 去重与补全
通过唯一标识(如UUID)过滤重复数据,结合时间戳补全缺失片段。
资源耗尽应急处理
- 内存溢出
- 立即停止高消耗进程,清理缓存文件。
- 调整JVM参数(如
-Xmx限制堆内存)。
- 磁盘满
- 删除过期数据(如保留7天策略):
DELETE FROM raw_data WHERE timestamp < NOW() INTERVAL '7 days';
- 扩展存储容量或迁移至冷存储(如MinIO)。
- 删除过期数据(如保留7天策略):
系统恢复与验证
- 逐步回滚变更
若故障由版本升级引起,回退到上一个稳定版本。
- 数据完整性校验
- 对比输入端与存储端数据量,确保无丢失:
SELECT COUNT() FROM raw_data WHERE timestamp > '2023-10-01';
- 对比输入端与存储端数据量,确保无丢失:
- 压力测试
- 模拟高并发场景,验证系统稳定性:
# 使用JMeter或Locust压测数据采集接口 jmeter -n -t test_plan.jmx -l result.jtl
- 模拟高并发场景,验证系统稳定性:
长期预防措施
| 策略 | 实施方法 |
|---|---|
| 高可用设计 | 部署至少3个副本节点,使用Raft/Paxos协议保证选举一致性 |
| 自动化监控 | 集成Prometheus+Grafana,设置动态阈值告警 |
| 容灾演练 | 每季度模拟单机房断电、主节点宕机等场景,检验恢复流程 |
| 代码健壮性 | 实现熔断机制(如Hystrix)、重试策略(指数退避算法) |
| 文档与培训 | 编写故障处理手册,定期开展运维人员实战演练 |
FAQs
Q1:如何快速重启一个故障节点?
A1:优先通过容器编排工具(如Kubernetes)执行kubectl delete pod触发自动重建;若为物理机,使用Ansible脚本批量重启服务并验证健康状态。
Q2:数据丢失后如何恢复?
A2:若启用了Kafka/RocketMQ等消息队列,从最早未确认的消费位点(Offset)重新消费;若存储层有备份,从冷存储中恢复增量数据;必要时人工补采关键