上一篇
分布式文件存储系统ceph安装
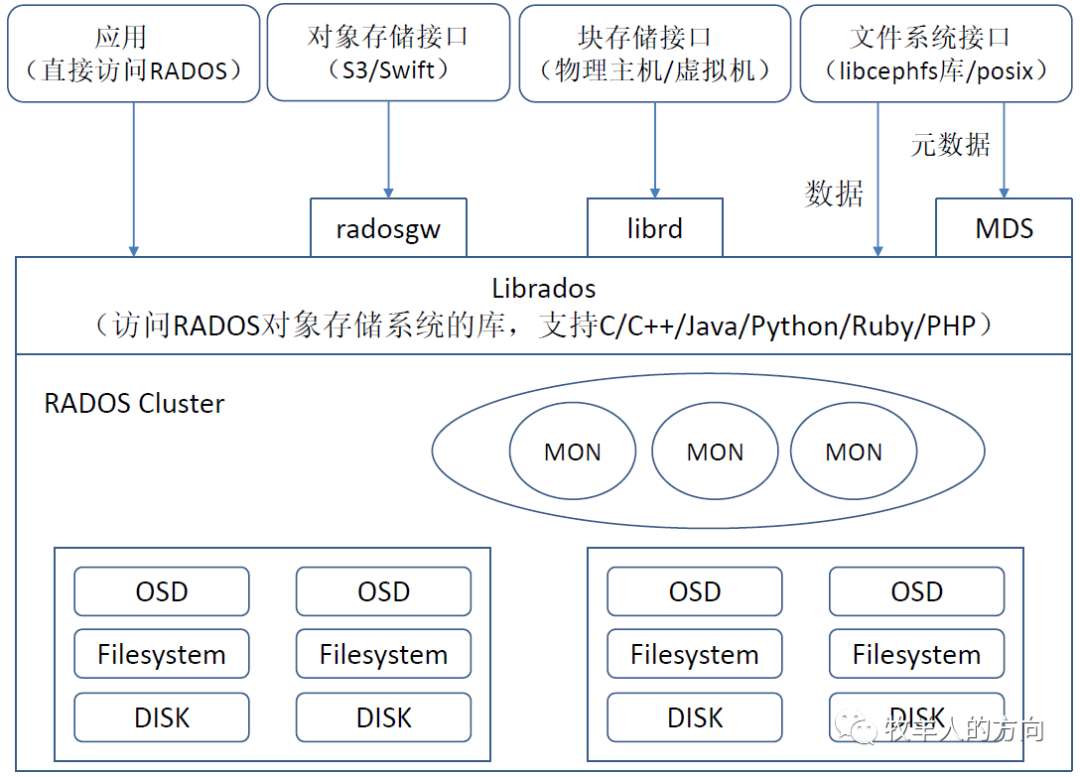
Ceph分布式存储系统安装需先部署集群监视器(Mon),配置管理节点(Mgr),创建对象存储(OSD),最后配置客户端
分布式文件存储系统Ceph安装详解
环境准备
Ceph集群的部署需要满足硬件和软件的基本要求,以下是典型部署环境的规划:
| 类别 | 要求 |
|---|---|
| 硬件要求 | 至少3个物理节点(用于Monitor、Manager、OSD角色) 每节点至少1块SSD(用于OSD Journal)和1块大容量HDD/SSD(用于数据存储) 千兆网卡或更高带宽网络 CPU:4核以上,内存:8GB以上 |
| 操作系统 | CentOS 7/8、Ubuntu 20.04 LTS、Red Hat Enterprise Linux 8 内核版本≥4.x(推荐5.x) |
| 网络配置 | 所有节点之间互通(低延迟、高带宽) 关闭防火墙或开放以下端口:6789(Mon)、6800/6801(OSD)、80/443(Dashboard) |
| 时间同步 | 所有节点需通过NTP或chrony实现时间同步(误差≤1秒) |
安装前配置
SSH免密登录
在所有节点之间配置SSH免密登录,便于后续自动化部署。ssh-keygen -t rsa # 生成密钥对 ssh-copy-id -i ~/.ssh/id_rsa.pub root@<目标节点IP>
主机名与IP映射
编辑/etc/hosts文件,添加所有节点的主机名和IP对应关系:168.1.10 mon1 192.168.1.11 mon2 192.168.1.12 mon3
禁用防火墙(生产环境建议使用安全组替代)
systemctl stop firewalld && systemctl disable firewalld setenforce 0 # 临时关闭SELinux
部署Ceph组件
安装Ceph软件包
所有节点执行以下命令(以CentOS为例):rpm --import 'https://download.ceph.com/keys/release.asc' curl -O https://download.ceph.com/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm rpm -Uvh ceph-release-1-1.el7.noarch.rpm yum install -y ceph-deploy ceph-common ceph-mds ceph-mgr ceph-osd ceph-mon ceph-radosgw
初始化集群并部署Monitor节点
使用ceph-deploy工具快速部署:
ceph-deploy new mon1 mon2 mon3 # 初始化集群并部署Mon节点 ceph-deploy admin mon1 mon2 mon3 # 分发管理员密钥
部署Manager节点
选择一台节点作为Manager:ceph-deploy mgr mon1 # 在mon1上部署Manager
部署OSD(对象存储守护进程)
在存储节点上准备磁盘并部署OSD:ssh <存储节点> 'fdisk /dev/vdb <<EOF # 假设/dev/vdb为数据盘 n p 1 默认 e 默认 w EOF' ceph-deploy osd mon1:/dev/vdb # 将/dev/vdb作为OSD加入集群
集群配置与优化
配置CRUSH地图
Ceph通过CRUSH算法管理数据分布,默认配置通常适用,但可根据硬件拓扑优化:ceph osd crush reweight-by-utilization <权重值> # 动态调整OSD负载均衡
设置副本数与PG数量
修改副本数(默认3)和PG数量(默认128):ceph osd pool set <池名> size 3 # 设置副本数为3 ceph osd pool set <池名> pg_num 128 # 设置PG数量
网络调优
修改/etc/ceph/ceph.conf,优化TCP参数:[global] tcp_congestion_algorithm=bbr # 启用BBR拥塞控制算法
客户端配置
安装客户端工具
在客户端节点安装ceph-common:yum install -y ceph-common
挂载Ceph文件系统
使用CephFS挂载到本地目录:mount -t ceph -o name=admin,secret=<密钥> <MON_IP>:/ /mnt/cephfs
验证挂载
创建测试文件并查看:echo "Hello Ceph" > /mnt/cephfs/test.txt ls /mnt/cephfs/
验证集群状态
执行以下命令检查集群健康状态:
ceph health # 应返回HEALTH_OK ceph osd tree # 查看OSD树状拓扑 ceph df # 查看存储空间使用情况
FAQs
Q1:集群状态显示HEALTH_WARN,提示“OSD_DOWN”如何解决?
A1:
- 检查故障OSD节点的磁盘状态:
ssh <故障节点> dmesg | grep -i error - 若磁盘损坏,替换磁盘并执行:
ceph osd out <OSD_ID> # 标记OSD下线 ceph osd crush remove <OSD_ID> # 从CRUSH地图移除 ceph osd destroy <OSD_ID> # 清理元数据
- 重新部署新OSD并等待数据再平衡。
Q2:新增OSD后数据未自动平衡如何处理?
A2:
- 手动触发数据平衡:
ceph osd reweight-by-utilization - 检查CRUSH地图是否正确包含新OSD:
ceph osd crush dump - 确保新OSD状态正常:
ceph osd tree,若状态异常则重启OSD服务:`systemctl restart ceph-osd@