上一篇
分布式数据库的原理
分布式数据库通过数据分片、多副本复制实现扩展与容错,依赖一致性协议保障数据一致,采用分布式事务协调跨节点操作
分布式数据库的原理详解
分布式数据库是一种通过网络将数据分散存储在多个物理节点上的数据库系统,旨在解决传统集中式数据库在扩展性、可用性和性能方面的瓶颈,其核心原理围绕数据分片、复制、一致性协议、分布式事务管理等关键技术展开,以下从架构设计、数据分布策略、一致性保障、容错机制等维度进行详细分析。
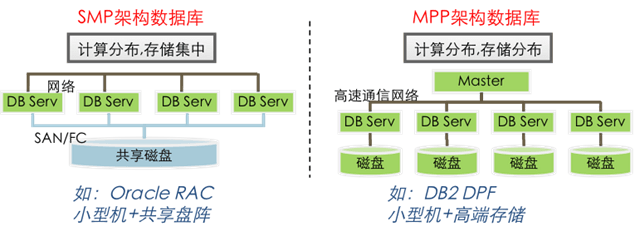
分布式数据库的核心架构
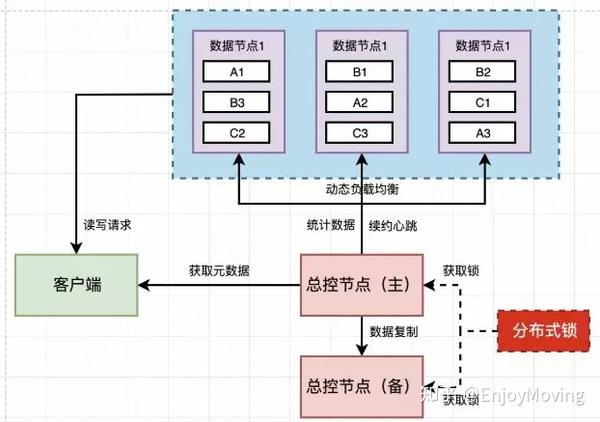
分布式数据库的架构设计需平衡数据分布、节点通信和故障恢复能力,典型架构包括以下两类:
| 架构类型 | 特点 | 适用场景 |
|---|---|---|
| 共享存储架构 | 所有节点访问同一存储系统(如SAN),无数据分片,依赖日志同步实现一致性。 | 小规模集群,对延迟敏感的场景 |
| 共享无存储架构 | 数据分片存储在不同节点,每个节点独立处理本地数据,通过复制和协议保证一致性。 | 大规模分布式系统,高可用需求 |
典型组件:
- 协调节点(Coordinator):负责路由请求、元数据管理(如分片位置、节点状态)。
- 数据节点(Data Node):存储实际数据分片,执行本地查询和事务。
- 全局事务管理器:处理跨分片的分布式事务,确保ACID特性。
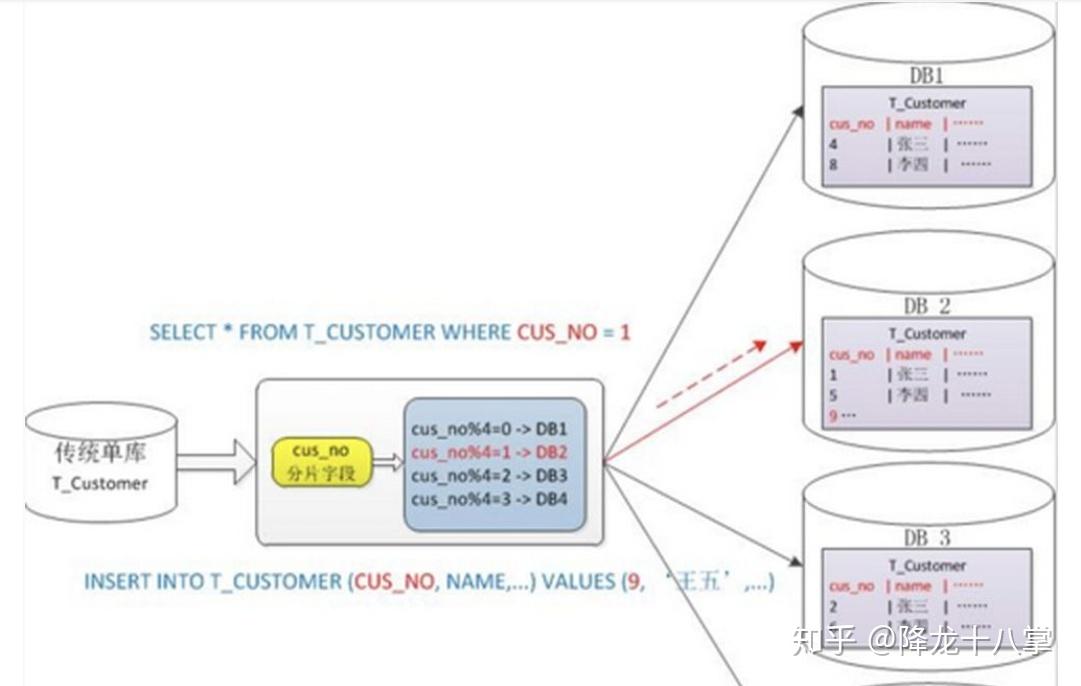
数据分片(Sharding)原理
数据分片是将数据集划分为多个子集(分片),分配到不同节点以实现负载均衡和扩展性,分片策略直接影响性能和复杂度:

| 分片策略 | 实现方式 | 优缺点 |
|---|---|---|
| 哈希分片 | 按主键哈希值取模分配分片 | 均匀分布,但范围查询需扫描多个分片 |
| 范围分片 | 按主键范围划分(如时间、ID区间) | 支持范围查询,但易导致热点分片 |
| 目录分片 | 基于业务逻辑(如用户ID、地域)自定义分片规则 | 灵活但需人工维护规则,易出现数据倾斜 |
分片示例:
假设用户表按user_id哈希分片,节点A存储user_id % 3 == 0的数据,节点B存储user_id % 3 == 1,节点C存储user_id % 3 == 2,写入时直接计算目标节点,读取时仅需访问对应分片。
数据复制与一致性保障
为保证高可用性,分布式数据库通常采用数据复制(Replication),复制方式与一致性协议决定了系统的容错能力和性能:
| 复制类型 | 描述 | 一致性协议 |
|---|---|---|
| 主从复制(Master-Slave) | 一个主节点负责写入,数据异步复制到从节点。 | 最终一致性(如MySQL) |
| 多主复制(Multi-Master) | 所有节点均可读写,通过冲突解决机制(如版本向量)合并数据。 | 强一致性(如Spanner) |
| Paxos/Raft协议 | 通过投票选举主节点并同步日志,确保多数派达成一致。 | 强一致性(如etcd、ZooKeeper) |
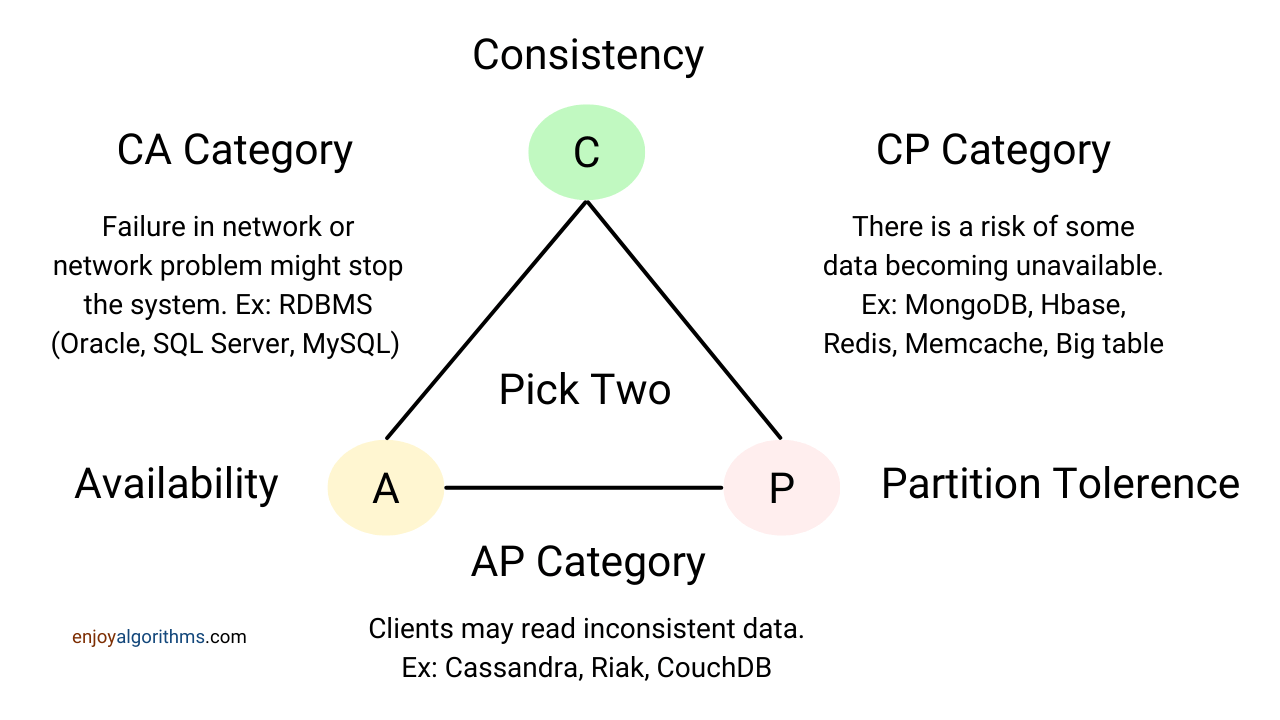
CAP定理的权衡:
分布式系统无法同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance),常见策略如下:
- CP模式(如HBase):优先保证一致性和分区容忍,牺牲部分可用性(如主节点故障时拒绝写入)。
- AP模式(如DynamoDB):优先保证可用性和分区容忍,允许临时不一致(如最终一致性)。
- CA模式:仅适用于无分区场景(如单机房部署),实际极少使用。
分布式事务管理
分布式事务需解决跨分片操作的ACID特性,核心挑战是协调多个节点的原子性,常见实现方案:
| 方案 | 原理 | 性能代价 |
|---|---|---|
| 两阶段提交(2PC) | 协调者先执行“准备阶段”(预提交所有节点),再执行“提交阶段”完成事务。 | 阻塞等待,影响吞吐量 |
| 三阶段提交(3PC) | 增加“预提交阶段”减少阻塞,但复杂度更高。 | 仍存在资源锁定问题 |
| TCC(Try-Confirm-Cancel) | 应用层拆分事务为尝试、确认、取消三步,支持异步处理。 | 依赖业务逻辑实现 |
| 乐观并发控制 | 假设冲突较少,先执行后验证(如版本号检查),冲突时重试。 | 高冲突场景性能下降 |
示例(2PC流程):
- 准备阶段:协调者向所有分片发送
Prepare请求,分片锁定数据并返回ACK。 - 提交阶段:若全部
ACK,发送Commit;否则回滚(Rollback)。
容错与恢复机制
- 节点故障检测:通过心跳机制(如ZooKeeper)实时监控节点状态。
- 自动故障转移:主节点失效时,通过选举(如Raft)提升从节点为新主节点。
- 数据修复:利用副本比对(如校验和、日志回放)修复损坏或丢失的数据。
- 脑裂问题处理:通过仲裁节点(如多数派投票)解决网络分区后的数据冲突。
FAQs
Q1:为什么分布式数据库无法同时满足CAP定理的三个条件?
A1:CAP定理指出,在网络分区(Partition)发生时,系统必须在一致性(Consistency)和可用性(Availability)之间取舍,若网络中断导致节点间无法通信(分区),坚持一致性(CP模式)需拒绝部分请求以保证数据正确;而选择可用性(AP模式)则允许临时不一致,但能继续服务请求,设计时需根据业务需求选择优先级。
Q2:分布式事务的2PC和3PC有什么区别?
A2:两者均用于保证跨节点事务的原子性,但3PC通过增加“预提交”阶段减少阻塞时间:
- 2PC:协调者在准备阶段同步阻塞,直到所有节点响应后才进入提交阶段,可能导致长时间锁定资源。
- 3PC:引入“预提交”阶段(Can Commit),各节点非阻塞反馈可行性,最后协调者决定是否进入正式提交,降低资源占用,但3PC实现更复杂,且无法完全解决“协调者单点故障