上一篇
分布式数据库的特点是
分布式数据库通过数据分片存储提升处理能力,具备高可用、弹性扩展及容错性强等特点,支持多节点协同,位置透明,有效平衡负载,保障系统稳定高效
分布式数据库的核心特点与技术解析
分布式数据库是一种通过网络将数据存储在多个物理节点上的数据库系统,旨在解决传统集中式数据库在扩展性、可靠性和性能方面的瓶颈,其核心特点可归纳为以下方面:
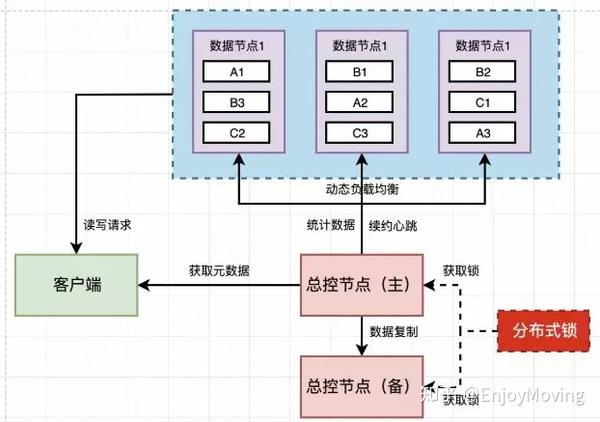
数据分片(Sharding)
分布式数据库通过将数据划分为多个子集(分片),分散存储在不同节点上,以实现负载均衡和并行处理。
- 水平分片:按行拆分数据,例如按用户ID或时间范围划分,适用于高并发读写场景。
- 垂直分片:按列拆分数据,例如将用户信息表拆分为“基础信息”和“行为记录”两部分,适合不同业务模块的独立访问。
- 混合分片:结合水平和垂直分片,适应复杂业务需求。
优势:
- 突破单节点存储容量限制,支持海量数据存储。
- 降低单点负载,提升查询和写入性能。
挑战:
- 分片策略设计复杂,需考虑数据局部性与全局一致性。
- 跨分片查询可能导致性能下降(需依赖全局索引或中间件优化)。
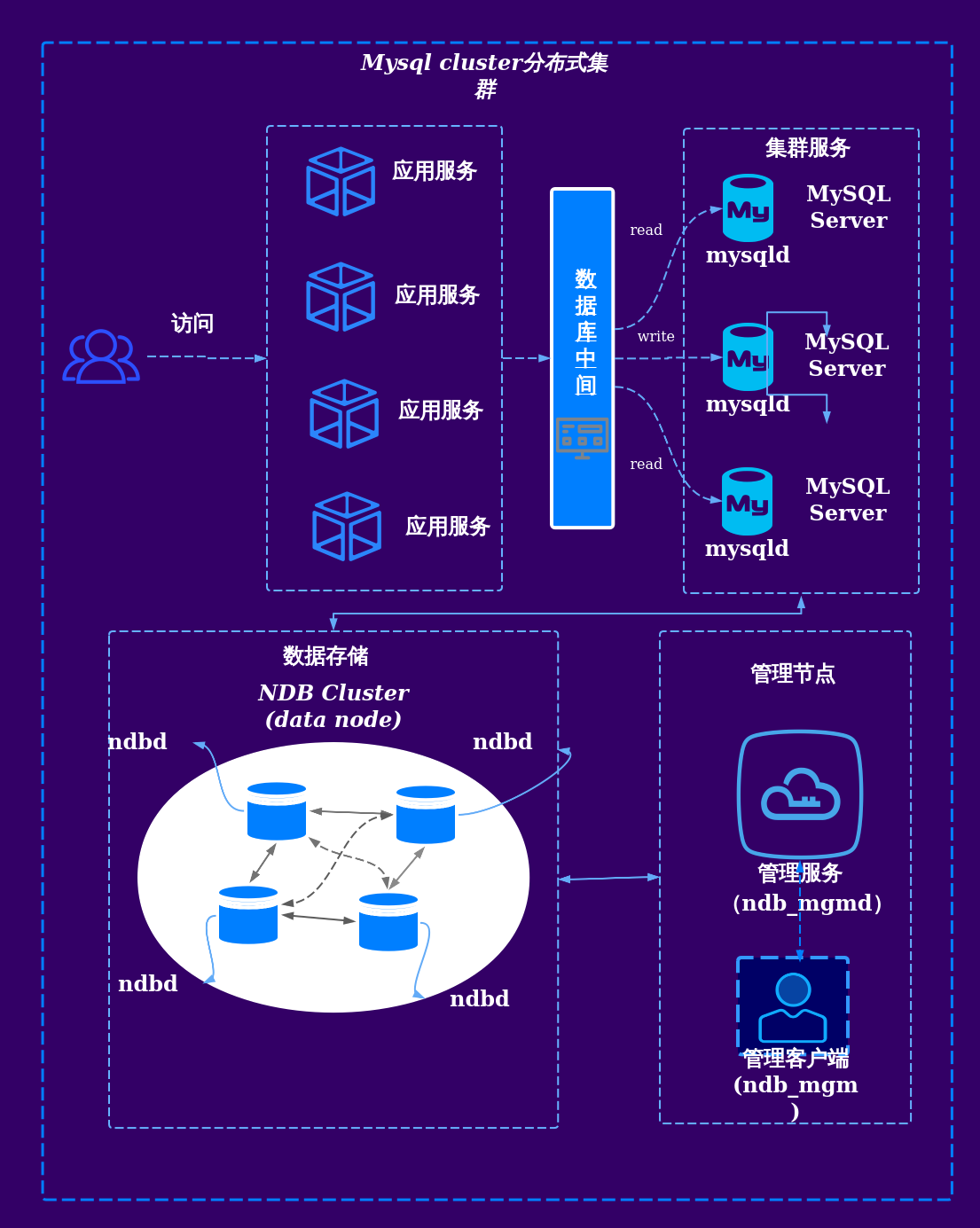
高可用性(High Availability)
通过数据冗余和故障转移机制,确保系统在节点故障时仍能持续提供服务。
- 数据副本:每份数据存储多份副本(如3份),分布在不同节点或机房,避免单点故障。
- 主备切换:采用主节点(Master)负责写入,备节点(Slave)同步数据,主节点故障时自动切换。
- Paxos/Raft协议:通过分布式共识算法保证副本间数据一致性,例如MySQL的Galera集群。
典型场景:

- 金融交易系统需99.99%可用性,通过跨机房部署和自动故障恢复实现。
弹性扩展(Elastic Scalability)
支持在线横向扩展(Scale-Out),无需停机即可添加节点。
- 水平扩展:增加服务器节点,分担数据存储和计算压力。
- 自动负载均衡:通过路由规则或中间件(如ProxySQL)动态分配请求到不同节点。
- 缩容能力:支持移除低负载节点,优化资源利用率。
对比传统数据库:
| 特性 | 分布式数据库 | 传统集中式数据库 |
|—————-|———————|———————-|
| 扩展方式 | 横向扩展(Add Nodes)| 纵向扩展(Upgrade Hardware)|
| 容量上限 | 无固定上限 | 受单节点硬件限制 |
| 故障影响 | 局部功能受损 | 全系统不可用 |
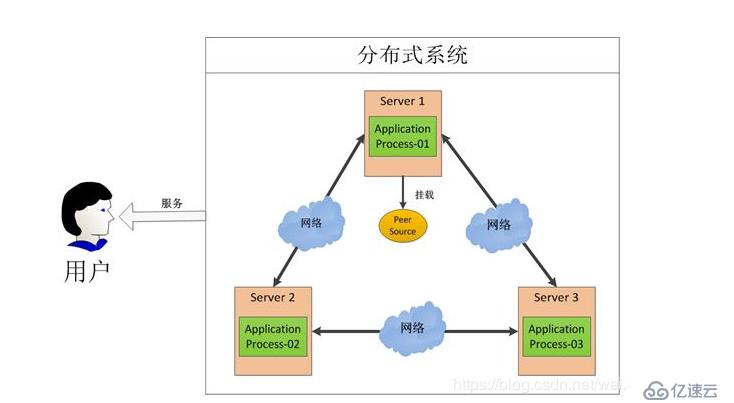
透明性(Transparency)
对用户和应用层屏蔽分布式复杂性,提供类似单机数据库的使用体验。
- 位置透明:应用程序无需感知数据存储位置,由系统自动路由。
- 复制透明:读写操作自动指向主节点或最近副本,保证低延迟。
- 事务透明:通过分布式事务协议(如两阶段提交)隐藏跨节点协调细节。
技术实现:
- 中间件层:如MyCAT、ShardingSphere,负责分片规则解析和SQL路由。
- 全局事务管理:采用XA协议或TCC(Try-Confirm-Cancel)模式处理跨分片事务。
容错性(Fault Tolerance)
通过冗余设计和自愈机制应对硬件故障、网络分区等问题。
- 数据副本重分配:节点故障时,自动将数据副本迁移至健康节点。
- 心跳检测:定期检查节点状态,快速识别故障并触发切换。
- 分区容忍:在网络分区(如机房断网)时,仍能保证部分服务可用(遵循CAP定理)。
案例:
- 亚马逊Aurora通过日志复制和秒级故障恢复,实现数据库实例的自动重启。
一致性模型(Consistency Models)
根据业务需求选择强一致性或最终一致性。
- 强一致性:所有副本数据实时同步,适用于金融、订单等场景(如Spanner的TrueTime技术)。
- 最终一致性:允许短期数据不一致,适用于社交媒体、日志等场景(如DynamoDB的乐观复制)。
- 可调一致性:通过配置参数平衡性能与一致性(如MongoDB的Write Concern)。
CAP定理权衡:
- 在分布式系统中,需在一致性(Consistency)、可用性(Availability)和分区容忍(Partition Tolerance)三者间取舍。
- 强一致性+分区容忍 → 可能牺牲可用性(如ZooKeeper选举期间)。
- 高可用性+分区容忍 → 可能采用最终一致性(如Cassandra)。
安全性(Security)
分布式环境下需解决数据泄露、节点信任等问题。
- 传输加密:使用TLS/SSL加密节点间通信,防止数据被窃听。
- 访问控制:基于角色(RBAC)或属性(ABAC)的权限管理,限制敏感数据访问。
- 审计日志:记录所有操作日志,便于追踪异常行为。
运维复杂性(Operational Complexity)
分布式数据库的运维难度显著高于单机数据库,需依赖自动化工具。
- 监控体系:集成Prometheus、Grafana等工具监控节点状态、性能指标。
- 自动化运维:通过Ansible、Terraform实现节点扩缩容、配置同步。
- 数据迁移:支持在线数据重平衡(如Cassandra的Token Ring机制)。
分布式数据库 vs. 传统数据库对比表
| 特性 | 分布式数据库 | 传统集中式数据库 |
|---|---|---|
| 扩展性 | 横向无限扩展 | 受硬件限制 |
| 高可用性 | 多副本+自动故障转移 | 单点故障风险 |
| 性能瓶颈 | 无单一瓶颈点 | CPU/IO易成为瓶颈 |
| 数据一致性 | 需权衡CAP定理 | 天然强一致性 |
| 运维成本 | 高(需管理多节点) | 低 |
FAQs 常见问题解答
Q1:如何选择合适的分布式数据库?
A:需综合考虑以下因素:
- 业务场景:高频交易需强一致性(如CockroachDB),互联网应用可接受最终一致性(如Cassandra)。
- 数据规模:PB级数据推荐HBase或Greenplum。
- 技术栈兼容性:例如MySQL生态可选ShardingSphere,NoSQL场景可选MongoDB。
- 运维能力:评估团队对分布式系统维护的经验。
Q2:分布式数据库的事务处理是否比单机更慢?
A:是的,主要原因包括:
- 网络延迟:跨节点通信增加耗时(如两阶段提交需多次RPC调用)。
- 锁粒度变大:全局事务可能锁定多个分片,降低并发度。
- 解决方案:采用BASE理论(基本可用、软状态、最终一致)或分片内事务优化(如Google