
上一篇
分布式数据库的产生过程
随着数据量激增和集中式数据库瓶颈凸显,结合网络与存储技术进步,为满足高可用、可扩展需求,分布式数据库应运而生,相关理论及实践逐步完善
分布式数据库的产生过程
分布式数据库的产生是计算机技术、网络通信和数据管理需求共同演进的结果,其发展经历了从理论探索到工业实践、再到云时代全面普及的漫长过程,以下从技术背景、核心需求、关键里程碑和现代演进四个维度展开分析。
技术背景与核心驱动力
| 驱动因素 | 具体表现 |
|---|---|
| 数据规模爆炸 | 20世纪80年代后,企业数据量以年均50%速度增长,单机存储能力难以满足需求 |
| 硬件成本限制 | 大型机/小型机价格昂贵,普通服务器性价比提升推动分布式架构 |
| 网络技术进步 | TCP/IP协议普及(1983年)、局域网/广域网带宽提升(10Mbps→Gbps) |
| 高可用性需求 | 金融、电信等行业对7×24小时服务的要求倒逼冗余设计 |
| 地理分布需求 | 跨国企业需要全球数据同步,传统集中式数据库存在时延和法规限制 |
典型案例:
- 1980年代美国航空公司的SABRE系统面临性能瓶颈,单日处理百万级机票预订请求时响应时间超过10秒
- 1990年代亚马逊订单量年增200%,MySQL单库架构频繁出现锁表问题
- 2000年代支付宝”双11″峰值交易导致Oracle数据库CPU利用率达99%
技术演进的三个阶段
理论奠基期(1970s-1990s)
- 1979年:Codd提出关系型数据库理论,但未解决分布式场景
- 1982年:IBM研究员发表《Distributed Data Bases: A Survey》首次系统定义分布式数据库特性
- 1986年:MIT开发SDD-1系统,实现基于半连接算法的分布式查询优化
- 1992年:Stonebraker提出分布式SQL标准,奠定分布式查询语言基础
技术突破:

- 两阶段提交协议(2PC)标准化(X/Open组织,1994)
- CAP定理雏形(Eric Brewer, 2000年正式提出)
- 一致性哈希算法(1997年由Karger等人提出)
工业实践期(2000s-2010s)
| 代表系统 | 时间 | 核心技术 | 创新点 |
|---|---|---|---|
| Google Bigtable | 2006 | 列族存储+SSTable+分区线性化 | 首次实现PB级数据高效随机读写 |
| Amazon Dynamo | 2007 | 最终一致性+矢量时钟+数据分片 | 放弃强一致性换取高可用性 |
| Yahoo PNUTS | 2008 | 动态扩缩容+版本化存储 | 支持每秒百万级请求 |
| Microsoft Drydeen | 2010 | Paxos协议+混合存储引擎 | 首个支持ACID事务的分布式系统 |
行业痛点突破:
- 淘宝”去IOE”运动(2009):通过OceanBase实现双十一峰值交易处理
- Facebook开发Cassandra(2008):解决Inbox搜索的跨数据中心延迟问题
- LinkedIn使用Espresso(2012):将数据延迟从秒级降至亚毫秒级
云原生时代(2010s-至今)
- 2012年:Spanner发布,首创全球一致的时间戳机制(TrueTime)
- 2014年:NewSQL运动兴起,CockroachDB实现水平扩展+ACID
- 2017年:TiDB开源,融合HTAP混合负载处理能力
- 2020年:Serverless架构普及,AWS Aurora Serverless实现按需计费
关键技术创新:
- Raft协议替代Paxos(Etcd/Consul广泛应用)
- 多模数据存储(支持文档/时序/图数据)
- 存算分离架构(计算节点与存储节点解耦)
- 智能调优(自动分片/索引/负载均衡)
核心挑战与解决方案演进
| 挑战类型 | 早期方案 | 现代解决方案 | 技术演进路径 |
|---|---|---|---|
| 数据一致性 | 2PC协议 | Paxos/Raft+线性化读 | 从锁机制到共识算法 |
| 分区容忍 | 手动Hash分片 | 自适应分片+热点检测 | 静态→动态分片策略 |
| 容灾恢复 | 主备复制 | 多副本+异地多活+混沌工程 | 冷备→热备→自动故障转移 |
| 查询优化 | 中心化优化器 | 分布式查询计划+代价模型 | 串行→并行优化 |
| 事务处理 | 单主模式 | 多领导者选举+全局事务拆分 | 从单点瓶颈到去中心化 |
现代分布式数据库特征
- 弹性扩展:支持秒级扩容(如PolarDB可扩展至128节点)
- 混合负载:同时处理OLTP(<1ms延迟)和OLAP(TB/s吞吐)
- 多地多活:跨洲际部署(如阿里云PolarDB-X支持5个AZ)
- 智能运维:自愈系统(故障检测→自动切换→容量预测)
- 安全合规:国密级加密+数据主权隔离(符合GDPR/CCPA)
FAQs
Q1:分布式数据库与集中式数据库的本质区别是什么?
A:核心差异体现在三个方面:
- 数据分布:前者数据分片存储于多节点,后者集中于单节点
- 扩展方式:分布式可通过横向扩展提升性能,集中式依赖纵向升级硬件
- 故障域:分布式天然具备容错能力,单节点故障不影响整体可用性
Q2:CAP定理对分布式数据库设计有何指导意义?
A:CAP定理揭示分布式系统无法同时满足:
- 一致性(Consistency):所有节点数据相同
- 可用性(Availability):每次请求都能收到响应
- 分区容忍(Partition Tolerance):网络分割时仍能工作
实际设计中需根据业务场景取舍:
- CP优先:金融交易(如Spanner保证强一致性)
- AP优先:社交媒体(如Dynamo采用最终一致性)
- BASE理论:通过柔性事务平衡性能与一致性(如淘宝Tair)
相关文章
大数据的产生与发展_华为云的激励是消费产生的激励,还是充值产生的激励?

大数据的产生_华为云的激励是消费产生的激励,还是充值产生的激励?
CRT如何连接数据库命令,提出了一个具体而明确的问题,即如何使用CRT工具连接到数据库。它没有过多的修饰词,直接指向了主题,即CRT工具与数据库连接的命令或方法。同时,它也符合文章的主要内容,因为文章详细介绍了使用CRT连接数据库的步骤和命令。此外,这个标题也具有一定的吸引力,因为它是针对那些需要使用CRT连接数据库的用户,这些用户可能会对这个标题产生兴趣并进一步阅读文章。
如何高效实现MySQL数据库的分库分表及迁移到分布式数据库DDM?
分布式数据库的数据透明性有哪几种
分布式数据库的数据存储策略
分布式数据库的数据一致性
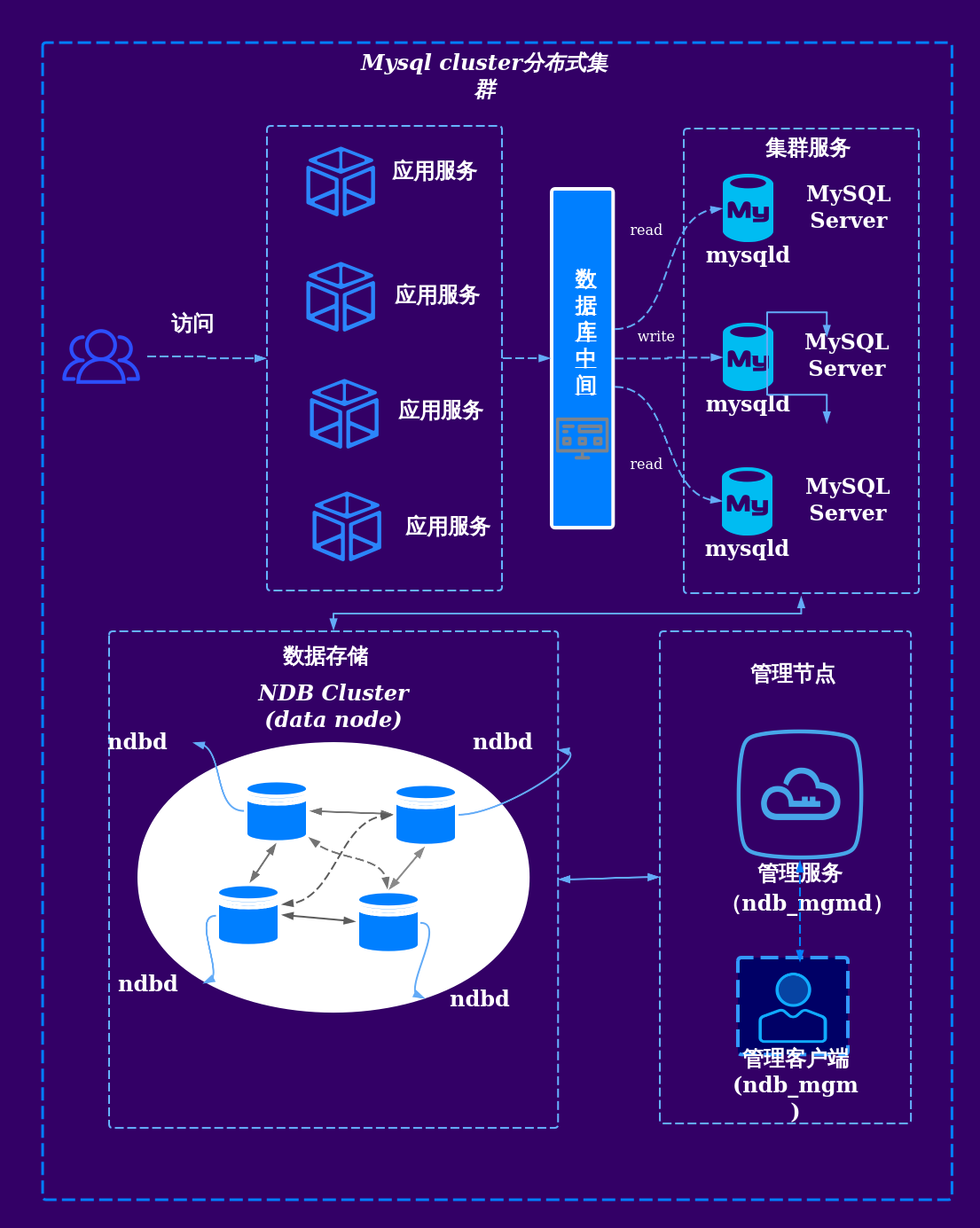
分布式数据库与数据仓库的关系








