上一篇
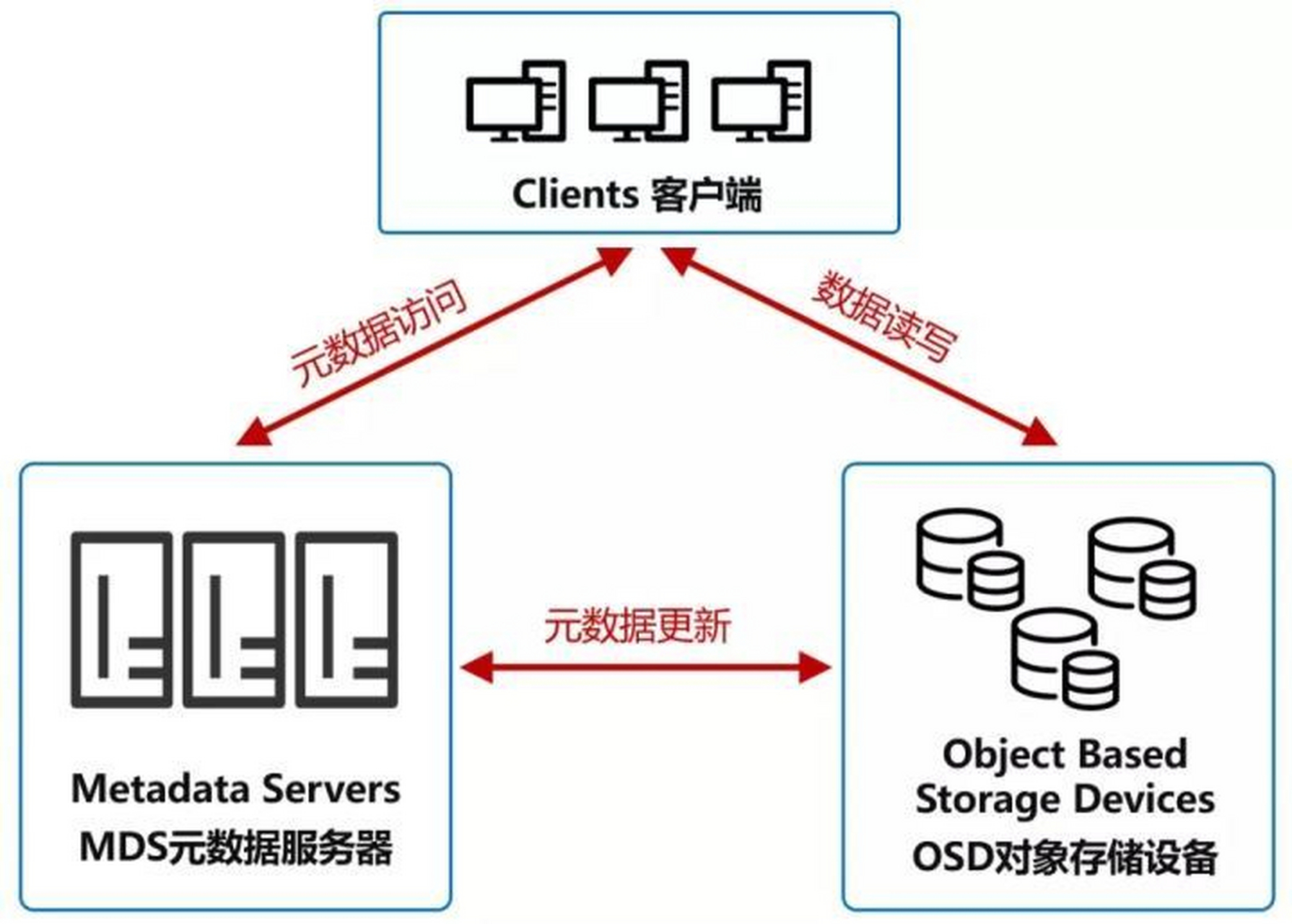
分布式数据库的存储方式
分布式数据库采用分片存储与多副本机制,实现数据冗余与负载均衡,确保高
分布式数据库的存储方式详解
分布式数据库通过将数据分散存储在多个节点上,结合数据分片、副本机制和一致性协议,实现高性能、高可用和可扩展性,其存储方式涉及数据分布策略、副本管理、存储引擎设计等多个层面,以下从核心维度展开分析:
数据分片(Sharding)
数据分片是将数据集划分为多个子集(分片),分配到不同节点上,以平衡负载和提升性能,分片策略直接影响数据分布均匀性和查询效率。
| 分片类型 | 描述 | 适用场景 |
|---|---|---|
| 水平分片 | 按行拆分数据,不同分片包含相同字段的子集 | 海量数据横向扩展(如用户表按ID分片) |
| 垂直分片 | 按列拆分数据,不同分片存储不同字段 | 高频访问特定字段(如订单表拆分为商品信息+用户信息) |
| 范围分片 | 按数值范围划分(如时间、ID区间) | 连续查询场景(如日志按日期分片) |
| 哈希分片 | 通过哈希函数均匀分布数据 | 负载均衡要求高的场景 |
| 混合分片 | 结合多种策略(如范围+哈希) | 复杂业务需求(如电商订单按时间+用户ID分片) |
分片关键问题:
- 分片键选择:需保证数据均匀分布,避免热点(如用户ID可能倾斜,需结合业务设计复合分片键)。
- 跨分片查询:涉及多个分片的关联查询需全局协调,可能引入额外开销。
- 动态扩缩容:需支持分片迁移(如通过一致性哈希或虚拟节点减少数据重分布成本)。
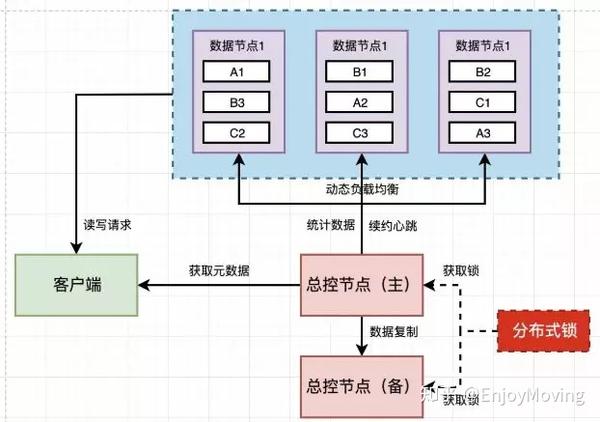
副本机制(Replication)
副本机制通过数据冗余提升容错性和读写性能,常见策略包括:
| 副本类型 | 描述 | 优缺点 |
|---|---|---|
| 主从复制 | 一主多从,主节点负责写操作,从节点同步数据 | 优点:写路径简单;缺点:主节点成为瓶颈,存在延迟 |
| 多主复制 | 所有节点均可接受写操作,通过冲突解决协议同步 | 优点:高可用;缺点:冲突处理复杂(如基于版本向量或时间戳) |
| Paxos/Raft协议 | 通过分布式共识保证数据一致性 | 优点:强一致性;缺点:性能开销较高 |
副本一致性模型:
- 强一致性:所有副本数据实时一致(如基于Raft的etcd),适用于金融交易等场景。
- 最终一致性:允许短期不一致,最终通过冲突解决达成一致(如DynamoDB),适用于互联网应用。
- 可调一致性:根据业务需求选择一致性级别(如MongoDB的Read Concern)。
存储引擎与数据编码
分布式数据库的存储引擎决定数据物理存储格式,需平衡读写性能、压缩率和查询效率。
| 存储引擎类型 | 特点 | 代表系统 |
|---|---|---|
| 键值存储 | 以键为索引,值无序存储,适合点查询 | Riak、Redis Cluster |
| 列式存储 | 按列存储数据,适合聚合计算和压缩 | HBase、Cassandra |
| 文档存储 | 以JSON/BSON格式存储半结构化数据 | MongoDB、Couchbase |
| 混合存储 | 支持多种数据模型(如NewSQL数据库) | Google Spanner、CockroachDB |
数据编码与压缩:
- 序列化格式:Protobuf、Avro等二进制格式减少存储体积和网络传输开销。
- 压缩算法:LZ4、Snappy用于快速压缩,Zlib、Gzip用于高压缩比场景。
- 索引优化:二级索引(如B+树、LSM树)加速查询,但需平衡写入放大效应。
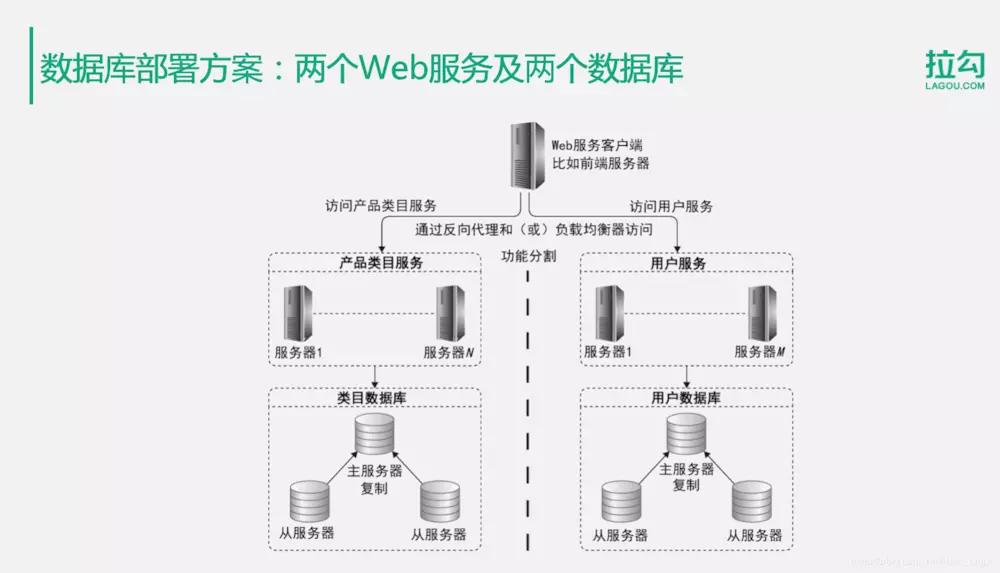
分区表与分片集群
分布式数据库常通过分区表(Partition Table)或分片集群(Sharded Cluster)管理数据,两者区别如下:
| 维度 | 分区表 | 分片集群 |
|---|---|---|
| 实现方式 | 单节点内逻辑分区(如MySQL分区表) | 多节点物理分片 |
| 扩展性 | 受限于单节点硬件 | 横向扩展(添加节点即可扩容) |
| 故障影响 | 单点故障可能导致全表不可用 | 分片独立,局部故障仅影响部分数据 |
| 适用场景 | 小规模数据或临时测试 | 大规模生产环境 |
一致性与事务处理
分布式环境下,CAP定理表明无法同时满足一致性、可用性和分区容忍性,实际系统需根据业务需求权衡:
- BASE理论:通过牺牲强一致性(如使用最终一致性)提升可用性,适用于社交媒体等场景。
- 分布式事务:
- 两阶段提交(2PC):同步阻塞协议,保证强一致性但性能较低(如XA事务)。
- TCC(Try-Confirm-Cancel):异步化改进,减少锁等待。
- NewSQL方案:通过多副本共识(如Raft)实现分布式事务(如Spanner的TrueTime)。
FAQs
Q1:如何选择水平分片与垂直分片?
- 水平分片:适用于单表数据量极大且查询粒度为单行的场景(如用户表)。
- 垂直分片:适用于高频访问特定字段且字段间关联性低的场景(如订单表拆分为商品信息和物流信息)。
Q2:副本数量如何配置?
- 读密集型:增加从库数量(如3主1从),提升读吞吐量。
- 写密集型:减少从库或采用多主架构,避免主节点瓶颈。
- 容灾需求:至少3个副本(如2主1备),防止