上一篇
分布式数据库的数据存储策略
分布式数据库采用数据分片、副本机制提升可用性,结合一致性哈希优化存储分布,通过分区表实现逻辑划分,并利用负载均衡保障节点
分布式数据库的数据存储策略详解
数据分片策略
分布式数据库通过数据分片(Sharding)将海量数据分散存储到多个节点,以实现水平扩展和负载均衡,常见的分片策略包括:
| 分片策略 | 原理 | 适用场景 | 缺点 |
|---|---|---|---|
| 哈希分片 | 通过哈希函数对分片键(如用户ID)计算哈希值,均匀分配到不同节点 | 负载均匀的读写场景(如社交用户数据) | 范围查询效率低,分片键不可变 |
| 范围分片 | 按时间、地理位置等连续范围划分数据(如按日期分片) | 需要按范围查询的场景(如订单数据) | 容易出现热点分片,负载不均衡 |
| 混合分片 | 结合哈希与范围分片(如先按哈希分片,再在分片内按范围划分) | 复杂查询与负载均衡兼顾 | 实现复杂度高,维护成本大 |
分片键选择原则:
- 唯一性:分片键应具有高基数(如UUID),避免热点
- 业务相关性:优先选择查询条件中的字段(如用户ID)
- 稳定性:避免频繁变更的字段(如状态位)
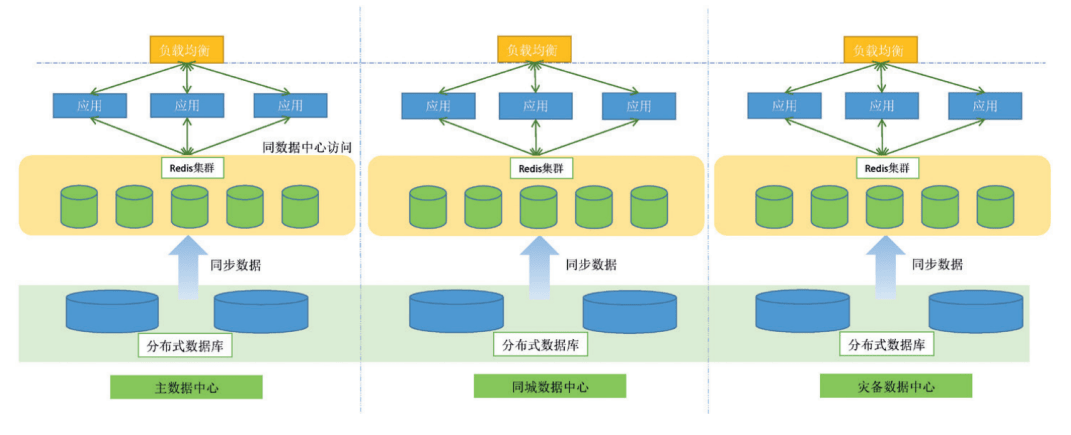
数据副本机制
为保证高可用性和容灾能力,分布式数据库采用多副本存储,核心策略包括:
| 副本类型 | 特点 | 典型协议 | 适用场景 |
|---|---|---|---|
| 主从复制 | 一主多从,主节点负责写操作,从节点同步数据 | MySQL Binlog | 读多写少场景(如内容分发) |
| 多主复制 | 所有节点均可读写,通过冲突检测解决数据不一致 | CockroachDB | 高并发读写场景(如电商库存) |
| Paxos/Raft | 基于分布式共识算法,保证强一致性 | etcd/ZooKeeper | 金融级交易系统 |
副本一致性保障:
- 同步复制:写操作需等待所有副本确认(强一致性但性能低)
- 异步复制:主节点确认即返回,副本异步同步(高可用但存在数据丢失风险)
- 半同步复制:多数副本确认后返回(平衡性能与一致性)
一致性模型选择
分布式系统中的CAP定理决定了一致性、可用性、分区容忍性不可兼得,主流策略包括:

| 模型 | 核心特性 | 代表系统 | 适用业务 |
|---|---|---|---|
| 强一致性(CP) | 保证数据更新后所有节点一致 | HBase(单行事务) | 金融交易、订单系统 |
| 最终一致性(AP) | 允许短期不一致,最终达到一致 | DynamoDB/Cassandra | 社交媒体、日志分析 |
| 因果一致性 | 保证因果关系有序,但不要求全局一致 | Kafka/Eventual Consistency | 物联网数据流、实时分析 |
存储引擎优化
不同业务场景需选择适配的存储引擎:
| 存储引擎 | 特点 | 最佳实践 |
|---|---|---|
| 行式存储 | 适合OLTP(在线事务处理),支持ACID事务 | MySQL InnoDB、PostgreSQL |
| 列式存储 | 压缩率高,适合OLAP(分析查询),但更新性能差 | HBase、ClickHouse |
| 文档存储 | 灵活Schema,适合半结构化数据(如JSON) | MongoDB、CouchDB |
| 内存存储 | 极低延迟,但成本高,用于高频访问的热数据 | Redis Cluster、MemSQL |
索引优化策略:
- 全局索引:跨分片建立二级索引(如Elasticsearch倒排索引)
- 局部索引:分片内建立B+Tree/LSM Tree索引
- 分区索引:范围分片场景下按分区边界建立索引
数据压缩与编码
为降低存储成本和网络传输带宽,分布式数据库采用多种压缩技术:
| 压缩类型 | 原理 | 应用场景 |
|---|---|---|
| 列式压缩 | 同一列数据类型统一,采用Run-Length Encoding或字典编码 | 分析型数据库(如Hive) |
| 页级压缩 | 对数据页(如8KB)整体压缩(如LZ4/ZSTD算法) | 通用型数据库(如TiDB) |
| 增量编码 | 仅存储与前一个值的差值(如时间序列数据) | 时序数据库(如InfluxDB) |
冷热数据分层
通过数据生命周期管理实现存储成本优化:
| 数据层级 | 存储介质 | 访问频率 | 典型策略 |
|---|---|---|---|
| 热数据 | SSD/内存 | 高频读写 | 缓存预热、LRU淘汰策略 |
| 温数据 | HDD/对象存储 | 中频查询 | 定期归档至低成本存储(如AWS S3 Glacier) |
| 冷数据 | 蓝光/磁带库 | 极少访问 | 长期保留策略,符合合规审计要求 |
自动分层示例:
-基于时间窗口的冷热数据识别 INSERT INTO cold_storage SELECT FROM user_logs WHERE last_access_time < NOW() INTERVAL '30 days'; DELETE FROM user_logs WHERE last_access_time < NOW() INTERVAL '30 days';
多租户隔离方案
在SaaS场景中,需保证租户数据隔离与资源公平:
| 隔离方式 | 实现机制 | 优缺点 |
|---|---|---|
| 物理隔离 | 独立数据库实例/硬件资源 | 安全性高,但资源利用率低 |
| 逻辑隔离 | 共享实例,通过租户ID区分数据(如Schema隔离) | 资源高效,但需防范SQL注入风险 |
| 混合隔离 | 关键数据物理隔离,非敏感数据逻辑隔离 | 平衡安全与成本 |
故障恢复策略
分布式数据库需应对节点故障、网络分区等异常:
- 副本自动切换:通过心跳检测触发Paxos选举新主节点
- 数据重建:基于日志(WAL)或增量快照恢复数据
- 跨机房容灾:采用多活数据中心部署(如阿里云DRDS)
成本优化实践
- 存储介质混合使用:热数据用SSD,冷数据用HDD/对象存储
- 数据去重:通过BloomFilter/MD5哈希检测重复数据
- 计算存储分离:采用存算分离架构(如AWS Aurora)降低扩容成本
FAQs
Q1:如何选择合适的分片键?
A1:需满足三个条件:
- 高基数:避免单分片数据量过大(如UUID优于性别字段)
- 查询相关性:优先选择常用查询条件字段(如电商订单的
user_id) - 业务稳定性:避免频繁变更的字段(如订单状态)
Q2:强一致性和最终一致性有什么区别?
A2:
- 强一致性:每次写操作后所有副本立即可见,适用于金融交易等严苛场景,但牺牲可用性(如CAP中的CP模型)。
- 最终一致性:允许短期数据不一致,但最终通过冲突解决达成一致,适合社交媒体等对实时性要求不高的场景,可用性更高(