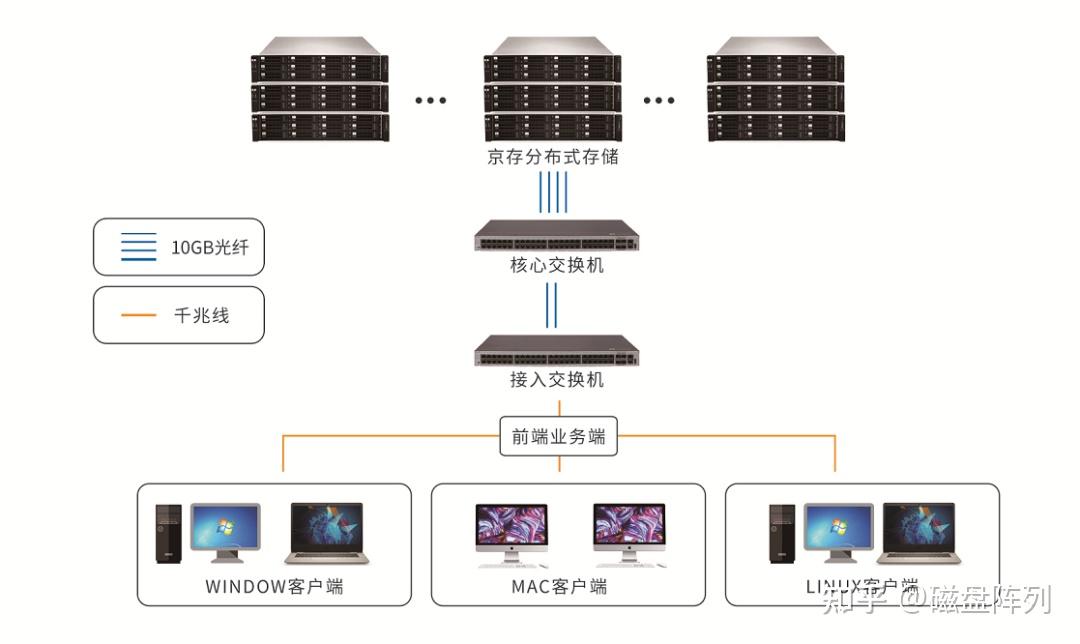
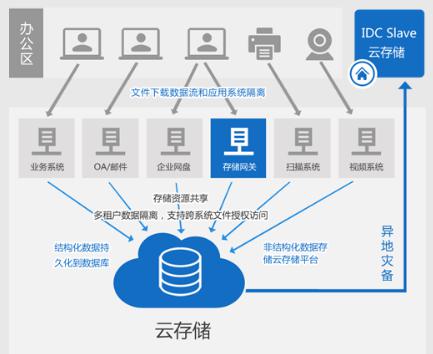
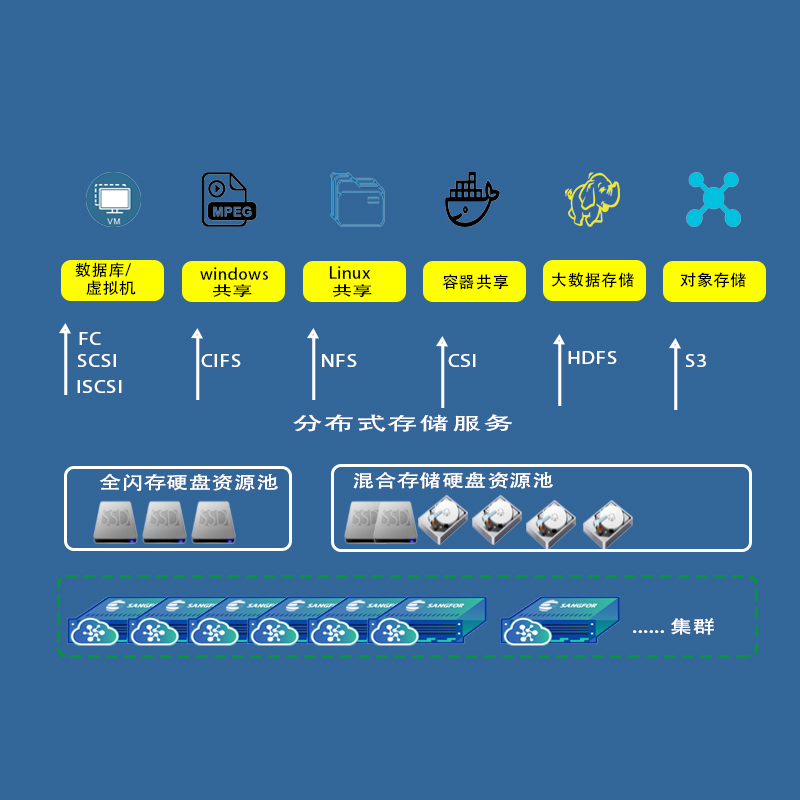
上一篇
如何制定高效的分布式存储系统存储策略?
分布式存储系统通过数据分片、副本复制和一致性协议等策略,实现了高可靠性、可扩展性和性能优化,有效应对了大规模数据存储的挑战。
分布式存储系统是现代数据管理中的关键组成部分,其设计旨在通过将数据分散存储在多个物理节点上,以实现高可用性、高性能和可扩展性,以下是关于分布式存储系统存储策略的详细探讨:
一、存储策略
分布式存储系统的存储策略主要围绕数据的分布、复制、一致性和容错性等方面展开,这些策略共同决定了系统的性能、可靠性和可维护性。
二、数据分布策略
1、数据分片(Sharding):将数据划分为多个小块(称为分片),每个分片可以独立存储和访问,这种策略有助于提高系统的并行处理能力和容错性。
2、哈希分布:使用哈希函数将数据映射到不同的节点上,确保数据分布均匀,常见的哈希算法包括一致性哈希等。
3、范围分布:按照数据的范围(如键值范围)将数据分配到不同的节点上,适用于有序数据或需要按顺序访问的数据。
三、数据复制策略
1、主从复制:数据有一个主副本和多个从副本,主副本负责处理写操作,从副本负责读操作,当主副本发生故障时,从副本可以提升为主副本。
2、多副本复制:在不同节点上保存多个数据副本,以提高数据的可靠性和可用性,副本数量根据业务需求和存储成本综合确定。
3、纠删码(Erasure Coding):将数据编码为多个校验块,即使部分数据丢失,也可以通过校验块恢复原始数据,这种策略在节省存储空间的同时提高了数据的可靠性。

四、一致性策略
1、强一致性:保证所有节点上的数据在任何时刻都是一致的,适用于对数据一致性要求极高的场景,但可能会牺牲一定的性能和可扩展性。
2、弱一致性:允许在一定时间内存在数据不一致的情况,适用于对数据一致性要求不高的场景,能够提供更好的性能和可扩展性。
3、最终一致性:保证在没有新的更新操作的情况下,所有节点上的数据最终会达到一致,是强一致性和弱一致性之间的折衷方案。
五、容错与恢复策略
1、副本机制:通过数据复制来提高数据的可靠性和容错性,当某个节点发生故障时,可以从其他节点上的副本恢复数据。
2、自动故障检测与恢复:系统定期检查节点的健康状态,一旦发现故障节点,自动将其上的数据迁移到其他健康节点上。
3、数据快照与备份:定期对系统数据进行快照和备份,以防数据丢失或损坏,在灾难发生时,可以通过备份数据快速恢复系统。
六、性能优化策略
1、缓存机制:利用缓存技术提高数据的访问速度,常见的缓存策略包括LRU(最近最少使用)缓存、LFU(最少频率使用)缓存等。
2、并行处理:通过数据分片、并发访问等技术提高系统的并行处理能力。
3、数据压缩:对数据进行压缩以减少存储空间的使用,同时可能提高数据传输的速度。
七、安全性策略
1、数据加密:对数据进行加密处理,确保数据在传输和存储过程中的安全性。
2、访问控制:限制对数据的访问权限,只允许授权用户访问敏感数据。
3、审计与监控:建立完善的审计和监控机制,及时发现并处理潜在的安全威胁。
| 存储策略 | 描述 | 优点 | 缺点 | 适用场景 |
| 数据分片 | 将数据划分为多个小块独立存储 | 提高并行处理能力 | 实现复杂 | 大规模数据处理 |
| 哈希分布 | 使用哈希函数映射数据到节点 | 数据分布均匀 | 需处理哈希冲突 | 通用场景 |
| 范围分布 | 按数据范围分配数据到节点 | 有序数据访问高效 | 负载不均问题 | 有序数据集 |
| 主从复制 | 主副本处理写操作,从副本处理读操作 | 读写分离提高效率 | 写操作性能受限 | 高可用性需求 |
| 多副本复制 | 不同节点保存多个数据副本 | 提高可靠性和可用性 | 存储成本增加 | 高可靠性需求 |
| 纠删码 | 编码数据为多个校验块 | 节省存储空间,提高可靠性 | 编解码开销大 | 大规模数据存储 |
| 强一致性 | 所有节点数据实时一致 | 数据准确性高 | 性能和可扩展性受限 | 高一致性需求 |
| 弱一致性 | 允许短时间内数据不一致 | 性能好,可扩展性强 | 一致性难以保证 | 低一致性需求 |
| 最终一致性 | 无新更新时数据最终一致 | 平衡一致性和性能 | 一致性达成时间不确定 | 中等一致性需求 |
| 副本机制 | 通过复制提高数据可靠性 | 提高容错性 | 存储成本增加 | 通用容错场景 |
| 自动故障检测与恢复 | 定期检查节点健康并恢复故障节点 | 提高系统稳定性 | 实现复杂 | 高可用性系统 |
| 数据快照与备份 | 定期备份数据以防丢失 | 灾难恢复能力强 | 备份成本和时间开销 | 重要数据保护 |
| 缓存机制 | 利用缓存提高数据访问速度 | 提高访问性能 | 缓存一致性问题 | 高频访问场景 |
| 并行处理 | 通过分片和并发访问提高处理能力 | 提高系统吞吐量 | 实现复杂 | 高性能计算场景 |
| 数据压缩 | 压缩数据以减少存储空间使用 | 节省存储成本,提高传输速度 | 压缩和解压缩开销 | 大规模数据存储 |
| 数据加密 | 对数据进行加密处理 | 确保数据安全 | 加密和解密开销 | 敏感数据保护 |
| 访问控制 | 限制数据访问权限 | 保护数据不被未授权访问 | 管理复杂性增加 | 多用户环境 |
| 审计与监控 | 建立审计和监控机制 | 及时发现安全威胁 | 实现和维护成本高 | 高安全性需求场景 |
九、FAQs
Q1: 如何在分布式存储系统中实现数据的高可用性和容错性?
A1: 在分布式存储系统中,实现数据的高可用性和容错性主要依赖于数据复制、副本机制和自动故障检测与恢复等策略,通过在不同的节点上保存数据的多个副本,可以提高数据的可靠性和可用性,系统需要定期检查节点的健康状态,一旦发现故障节点,自动将其上的数据迁移到其他健康节点上,以确保业务的连续性,纠删码技术也是一种有效的容错手段,它通过编码数据为多个校验块来实现数据的冗余存储和快速恢复。
Q2: 分布式存储系统中的数据一致性是如何保证的?
A2: 分布式存储系统中的数据一致性保证依赖于合适的一致性模型和同步机制,常见的一致性模型包括强一致性、弱一致性和最终一致性,强一致性模型要求所有节点上的数据在任何时刻都保持一致,适用于对数据一致性要求极高的场景,弱一致性模型允许在一定时间内存在数据不一致的情况,适用于对数据一致性要求不高的场景,最终一致性模型则保证在没有新的更新操作的情况下,所有节点上的数据最终会达到一致,为了实现这些一致性模型,系统通常采用分布式一致性协议(如Paxos、Raft等)来确保各个节点之间的数据操作保持一致,通过合理的数据复制和同步机制也可以进一步提高数据的一致性。
十、小编有话说
随着大数据时代的到来,分布式存储系统已经成为企业级应用不可或缺的一部分,面对海量数据的存储和管理挑战,选择合适的存储策略至关重要,本文详细介绍了分布式存储系统的多种存储策略及其优缺点和适用场景,希望能为您在设计和优化分布式存储系统时提供有益的参考,实际应用中还需要根据具体业务需求和技术环境灵活选择和组合这些策略以达到最佳效果。