上一篇
分布式数据库与数据仓库的关系
分布式数据库支撑数据仓库存储与计算,前者侧重事务处理,后者专注分析决策,技术互补
分布式数据库与数据仓库的关系解析
基础概念定义
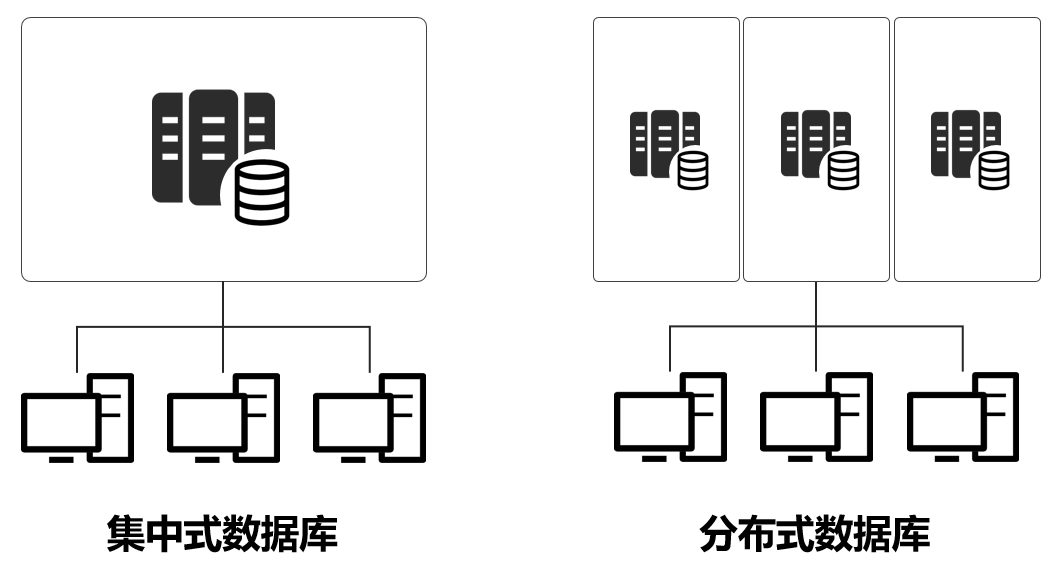
分布式数据库
分布式数据库(Distributed Database)是一种通过计算机网络将物理上分散的数据库节点连接成逻辑整体的数据库系统,其核心目标是解决大规模数据存储、高并发访问和地理分布场景下的数据管理问题,典型特征包括数据分片(Sharding)、多副本同步、分布式事务管理等。数据仓库
数据仓库(Data Warehouse)是面向主题的、集成的、非易失的且随时间变化的数据集合,主要用于支持企业决策分析,其核心功能是通过ETL(Extract, Transform, Load)流程整合多源数据,并通过预聚合、索引优化等技术加速复杂查询(如OLAP)。
核心差异对比
| 维度 | 分布式数据库 | 数据仓库 |
|---|---|---|
| 设计目标 | 支持高并发事务处理(OLTP) | 支持复杂分析查询(OLAP) |
| 数据模型 | 通常为关系型或NoSQL(灵活模式) | 多为星型/雪花模型,高度规范化 |
| 实时性 | 强实时性(毫秒级延迟) | 弱实时性(分钟/小时级延迟) |
| 数据更新频率 | 高频写入(事务型操作) | 低频写入(批量加载) |
| 扩展方式 | 水平扩展(分片+副本) | 水平扩展(分区表)或垂直扩展(硬件堆叠) |
| 典型场景 | 电商订单处理、社交网络数据存储 | 企业报表、用户行为分析、财务审计 |
技术架构的关联性
数据流动关系
- 数据采集阶段:分布式数据库常作为原始数据的存储层,通过日志同步或变更捕获(CDC)技术将数据推送至数据仓库。
- 数据处理阶段:数据仓库依赖分布式计算框架(如Apache Spark、Flink)对数据库中的数据进行清洗、转换和聚合。
- 数据服务阶段:分析结果可能反向写入分布式数据库(如Redis)以支持实时业务决策。
技术栈互补

- 存储引擎:数据仓库可基于分布式数据库(如HBase、Cassandra)构建,利用其扩展性和容错性。
- 计算引擎:分布式数据库的计算能力(如Google Spanner的SQL优化)可被数据仓库借用以加速查询。
- 一致性模型:数据仓库的最终一致性与分布式数据库的强一致性形成互补。
典型应用场景融合
| 场景 | 分布式数据库的作用 | 数据仓库的作用 |
|---|---|---|
| 实时风控系统 | 存储用户交易数据(如支付宝订单) | 分析历史交易模式生成风险评分 |
| 用户画像构建 | 收集用户行为日志(点击、浏览) | 聚合多维度数据生成标签体系 |
| 供应链优化 | 记录物流节点状态(如仓储库存) | 分析全链路数据预测需求波动 |
挑战与协同优化
数据一致性问题
- 挑战:分布式数据库的CAP定理(牺牲一致性)与数据仓库的完整性要求存在冲突。
- 解决方案:采用事件驱动架构(如Kafka),通过变更数据捕获(CDC)实现近实时同步。
性能瓶颈
- 挑战:数据仓库的复杂查询可能拖慢分布式数据库的写入性能。
- 优化策略:
- 冷热数据分离:高频数据保留在数据库,历史数据迁移至仓库。
- 异步ETL:通过消息队列解耦实时写入与批量处理。
成本控制
- 存储成本:分布式数据库需多副本存储,而数据仓库可通过列式存储压缩数据。
- 计算成本:数据仓库的预处理(如预计算立方体)可降低查询时的计算开销。
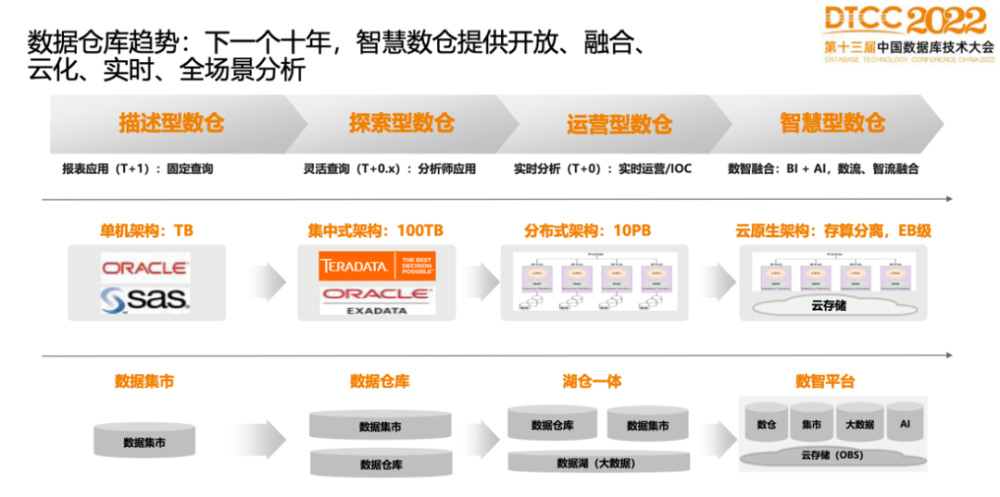
未来演进趋势
混合架构融合
- HTAP(Hybrid Transaction/Analytical Processing):同一系统同时支持事务与分析(如Google Spanner、阿里云PolarDB)。
- 流批一体:通过Flink等引擎实现数据库变更实时流入数据仓库。
云原生协同
- Serverless数据仓库:基于分布式数据库的弹性存储(如AWS Redshift Spectrum直接查询S3)。
- 边缘计算:在靠近数据源的分布式节点完成预处理,减少回传带宽。
FAQs
问题1:是否可以用分布式数据库直接替代数据仓库?
答:不推荐,分布式数据库虽然具备扩展性,但其设计目标是事务处理,缺乏数据仓库的预聚合、维度建模等优化功能,直接使用会导致复杂查询性能低下,且ETL流程难以高效实现。
问题2:如何选择合适的技术组合?
答:根据业务需求:
- 实时性要求高(如监控):优先使用分布式数据库(如TiDB)+ 实时数仓(如Apache Druid)。
- 历史分析为主(如财报):选择离线数仓(如Hive)+ 冷数据存储(如Amazon S3)。
- 混合负载(如电商):采用HTAP数据库(如PolarDB)减少数据