上一篇
分布式数据库与数据库集群的区别
分布式数据库内置分片与副本管理,支持透明扩展;数据库集群为多节点高可用架构,基于
分布式数据库与数据库集群的区别详解
在现代数据库技术中,分布式数据库和数据库集群是两个常被提及的概念,但它们的核心设计理念、应用场景和技术实现存在显著差异,以下从多个维度对比分析两者的区别,并通过表格归纳关键特性。
核心定义与架构设计
分布式数据库
分布式数据库是一种将数据逻辑上统一、物理上分散存储的系统,其核心目标是解决海量数据存储和高并发访问问题,通过数据分片(Sharding)、副本复制(Replication)等技术,将数据分布到多个节点上,每个节点可以独立处理部分数据,同时通过分布式协议保证数据一致性和可用性。
典型特征:- 数据按分片规则(如哈希、范围)分散存储。
- 节点间无主次之分,所有节点共同参与计算和存储。
- 支持水平扩展(添加节点即可扩容)。
数据库集群
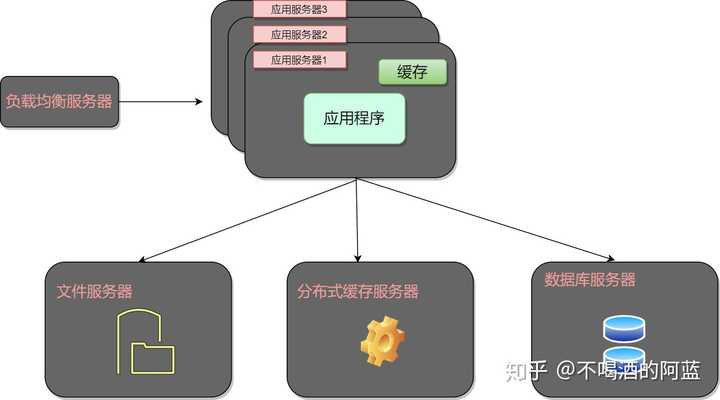
数据库集群是通过多台服务器协同工作来提升性能和可靠性的技术,其核心目标是通过负载均衡、主从复制或并行计算,解决单节点性能瓶颈或单点故障问题,集群中的节点通常分为不同角色(如主库、从库、协调节点等),数据可能集中存储或部分复制。
典型特征:- 数据可能集中存储(如共享存储集群)或部分复制。
- 节点间存在主次关系或角色分工。
- 扩展能力受限于架构设计(垂直扩展或有限水平扩展)。
关键区别对比
| 对比维度 | 分布式数据库 | 数据库集群 |
|---|---|---|
| 数据存储方式 | 数据分片存储,每个节点存储部分数据 | 数据集中存储或全量复制,节点共享数据 |
| 节点角色 | 无主次之分,所有节点平等 | 存在主节点、从节点或协调节点 |
| 扩展性 | 水平扩展(添加节点即可扩容) | 垂直扩展或有限水平扩展 |
| 容错性 | 自动故障转移,数据冗余保障可用性 | 依赖主从切换或手动干预 |
| 一致性模型 | 最终一致性(如NoSQL)或强一致性(如NewSQL) | 通常保持强一致性(如主从复制) |
| 适用场景 | 海量数据、高并发、跨地域部署 | 高可用、读写分离、本地高性能需求 |
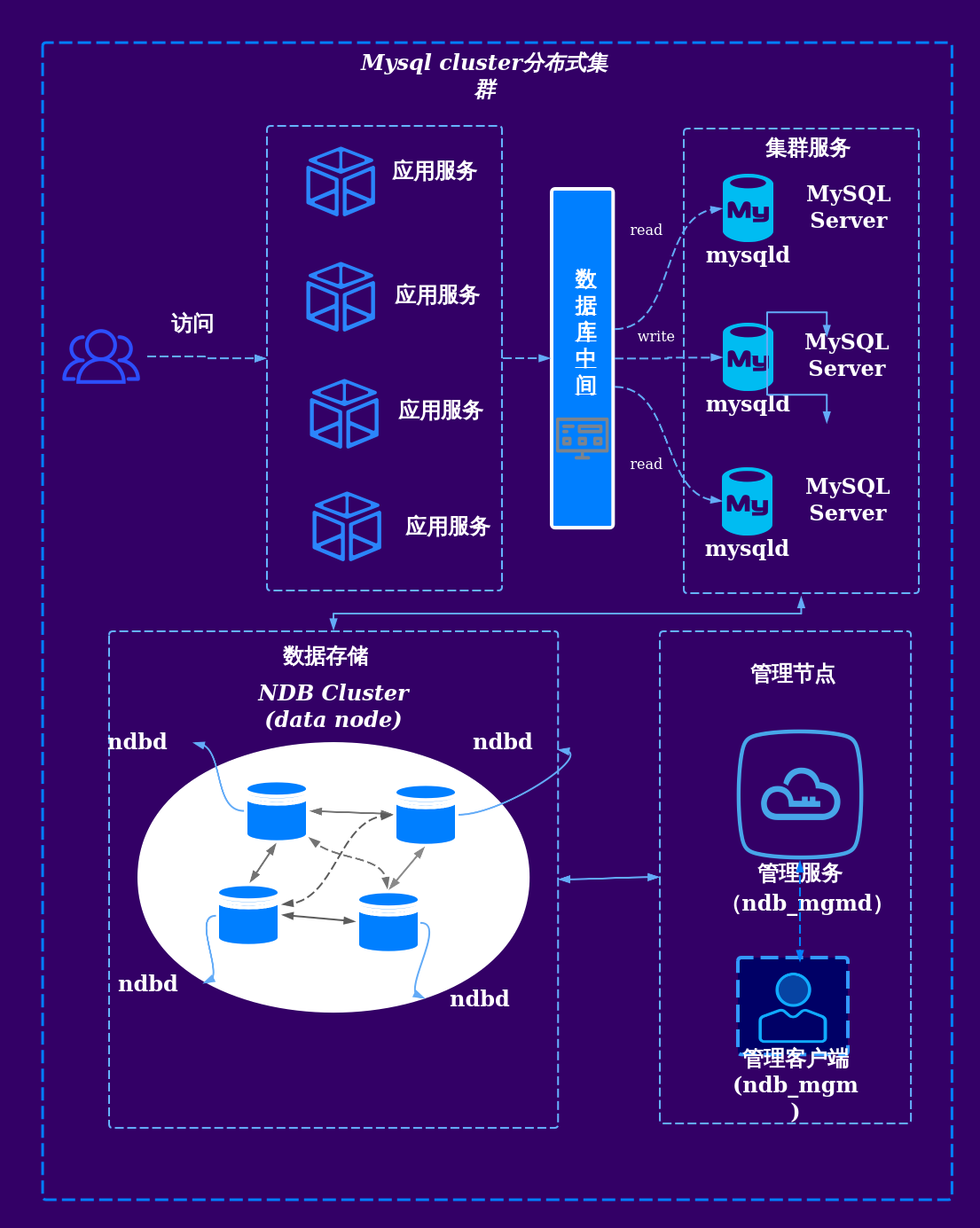
| 技术复杂度 | 较高(需处理分片、路由、分布式事务等) | 中等(依赖成熟集群方案如MySQL Cluster) |
| 典型产品 | Cassandra、CockroachDB、TiDB | MySQL Cluster、Redis Cluster、MongoDB副本集 |
深度分析
数据分片与副本机制
分布式数据库通过数据分片将不同数据分配到不同节点,每个节点仅处理局部数据,例如按用户ID哈希分片,为保证高可用,每个分片通常会存储多个副本(如3个副本),而数据库集群(如MySQL主从复制)通常将数据完整复制到从节点,所有节点保存相同数据,主节点负责写操作,从节点负责读操作。
扩展性差异
分布式数据库的扩展性更优,新增节点只需调整分片规则,无需重构数据,Cassandra通过增加节点可线性提升吞吐量,而数据库集群的扩展受限于架构,例如MySQL Cluster在节点数增加时可能面临性能下降或管理复杂度上升的问题。一致性与性能权衡
分布式数据库通常遵循CAP定理,在设计时需权衡一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance),Cassandra选择牺牲强一致性以提升可用性,而CockroachDB则通过多副本协议(如Raft)实现强一致性,数据库集群(如MongoDB副本集)通常优先保证强一致性,但分区故障时可能降低可用性。运维复杂度
分布式数据库的运维更复杂,需处理分片元数据管理、跨节点事务、网络分区等问题,Global Transaction(全局事务)在分布式系统中需依赖2PC或TCC协议,而数据库集群的运维相对简单,例如MySQL主从复制只需配置日志同步和故障切换脚本。
如何选择?
选择分布式数据库的场景:
- 数据规模达到TB/PB级,且需要全球部署(如电商、社交网络)。
- 需要高吞吐和低延迟的并发读写(如物联网数据流)。
- 业务对一致性要求可适度放宽(如用户画像、日志分析)。
选择数据库集群的场景:
- 本地高性能需求,数据量在GB到TB级(如企业内部系统)。
- 需要强一致性和简单扩展(如金融交易、库存管理)。
- 现有技术栈已支持集群方案(如MySQL、Redis)。
FAQs
问题1:分布式数据库是否一定比数据库集群更先进?
答:两者适用场景不同,没有绝对优劣,分布式数据库擅长处理海量数据和高并发,但牺牲了部分一致性;数据库集群更适合对一致性要求高、数据量适中的场景,且技术成熟度更高,选择需结合业务需求,例如互联网金融可能优先选择数据库集群保障强一致性,而短视频平台可能采用分布式数据库支撑高并发。
问题2:是否可以将分布式数据库部署为数据库集群?
答:可以,分布式数据库通常需要集群环境支撑,但其核心区别在于数据分片和无主架构,TiDB(分布式数据库)可以部署在Kubernetes集群中,但底层仍通过分片和Raft协议实现数据分布与一致性,分布式数据库是集群的一种