上一篇
分布式数据库与关系型数据库
分布式数据库通过多节点存储实现高可用与扩展,适合海量数据处理;关系型数据库基于结构化与ACID特性,支持复杂事务,适用于
分布式数据库与关系型数据库核心差异解析
基础概念对比
| 维度 | 分布式数据库 | 关系型数据库(RDBMS) |
|---|---|---|
| 核心目标 | 解决大规模数据存储与高可用需求 | 保证数据一致性与结构化存储 |
| 数据分布 | 数据分片存储于多节点 | 数据集中存储于单一/主从节点 |
| 扩展方式 | 水平扩展(增加节点) | 垂直扩展(提升硬件配置) |
| 事务支持 | 最终一致性(BASE理论) | 强一致性(ACID特性) |
架构设计差异
数据存储架构
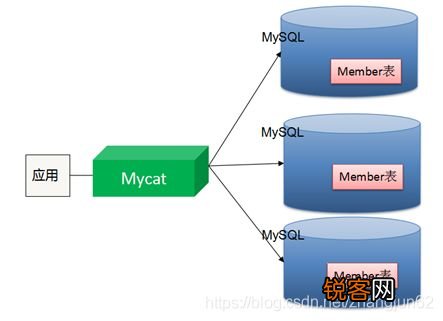
- 分布式数据库:采用Sharding(分片)技术,将数据按哈希/范围等策略拆分到不同节点,通过Raft/Paxos协议保障数据副本一致,典型如Cassandra的环形哈希分片、TiDB的Region划分。
- 关系型数据库:基于B+树索引的单点存储,通过主从复制实现读写分离,但存在单点瓶颈(如MySQL主库写压力)。
容错机制
- 分布式数据库:自动故障转移(如CockroachDB的Survival Goal)、数据副本自动恢复,支持跨机房部署。
- 关系型数据库:依赖手动主从切换(如Oracle Data Guard),RTO/RPO指标较高。
关键特性对比
| 特性 | 分布式数据库 | 关系型数据库 |
|---|---|---|
| 数据模型 | NoSQL/NewSQL混合模型 | 严格的关系模型(表/字段) |
| 扩展能力 | 线性水平扩展(理论无上限) | 垂直扩展受限于硬件天花板 |
| 一致性级别 | 可配置(强/因果一致性) | 默认强一致性(ACID) |
| SQL支持 | 部分支持(如CQL/Spark SQL) | 完整支持标准SQL |
| 运维复杂度 | 高(需管理多节点/网络) | 相对较低 |
性能与成本分析
读写性能

- 分布式数据库:通过并行查询(如Greenplum的MPP架构)、本地化计算提升吞吐量,但引入网络延迟。
- 关系型数据库:低并发场景性能优异,高并发时容易产生锁争用(如死锁检测开销)。
成本对比
| 成本类型 | 分布式数据库 | 关系型数据库 |
|—————-|—————————————|———————————-|
| 硬件成本 | 初期较低(可商用PC服务器集群) | 高端服务器(如Exadata一体机) |
| 运维成本 | 需专业DBA团队管理分片/负载均衡 | 相对简单(但高可用方案复杂) |
| 扩展成本 | 边际成本低(新增节点即可) | 指数级增长(硬件升级成本) |
适用场景选择
分布式数据库最佳实践
- 互联网规模应用(如TikTok用户画像存储)
- 实时数据分析(如电商大促日志处理)
- 全球化部署(如Uber多区域数据中心)
关系型数据库优势领域
- 金融交易系统(如银行核心账务处理)
- 企业ERP系统(如SAP HANA场景)
- 小规模高精度查询(如企业内部报表)
技术演进趋势
- 融合创新:NewSQL(如Google Spanner)结合分布式优势与SQL支持,TiDB实现HTAP混合负载。
- 云原生适配:AWS Aurora将MySQL分布式化,Azure Cosmos DB支持多模数据。
- 智能优化:分布式数据库引入AI调优(如PolarDB的自适应分片策略)。
FAQs
Q1:如何判断业务应该选择分布式数据库还是关系型数据库?
A:评估三个维度:①数据量(PB级选分布式);②一致性要求(金融交易需强一致性);③团队技术栈(传统企业倾向RDBMS),建议初期用RDBMS,当单机性能瓶颈出现后再考虑分库分表。
Q2:分布式数据库如何保证事务的ACID特性?
A:通过2PC/3PC协议实现跨节点事务(如CockroachDB),或采用补偿机制(如Saga模式),部分系统提供有限ACID支持,如Google Spanner的全局时钟