上一篇
Hive分布式数据仓库
Hive依托 Hadoop,是处理PB级数据的分布式数据仓库,支持SQL-like查询,适合离线分析,数据存储基于HDFS,兼容多种文件格式(如Text/RCFile),通过YARN实现资源调度,具备高扩展性
Hive分布式数据仓库详解
Hive是基于Hadoop生态系统的分布式数据仓库工具,由Facebook于2007年开发并开源,它通过类SQL语言(HiveQL)实现对大规模结构化数据的存储、管理和分析,底层依赖HDFS(分布式文件系统)和MapReduce/Tez/Spark等计算框架,Hive的核心目标是解决海量数据的高效查询问题,尤其适合离线批处理场景。
架构设计
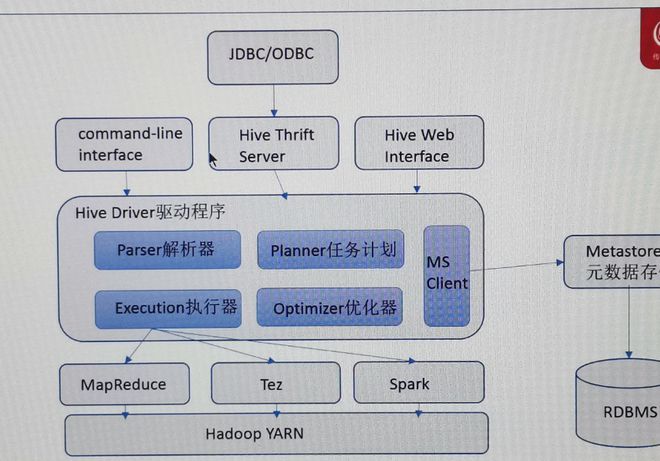
Hive采用典型的分层架构,主要包括以下组件:
| 组件 | 功能 | 技术实现 |
|---|---|---|
| Client | 用户交互接口,支持HiveQL语句提交(如Beeline、CLI) | JDBC/ODBC、Web UI |
| MetaStore | 元数据管理,存储表结构、分区信息、权限等 | 关系型数据库(MySQL/PostgreSQL) |
| Driver | 解析HiveQL,生成执行计划,协调计算资源 | Hive核心模块 |
| Execution Engine | 实际执行查询任务(MapReduce/Tez/Spark) | 可插拔计算引擎 |
| HDFS | 存储实际数据(按表、分区组织),提供高可靠、可扩展的分布式存储 | Hadoop生态 |
| YARN | 资源调度与任务管理(可选,需集成Hadoop YARN) | ResourceManager |
数据流示例:

- 用户通过Client提交查询
SELECT FROM sales WHERE date='2023-01-01'; - Driver解析语句,向MetaStore获取表结构及分区信息;
- 执行计划转换为MapReduce任务,从HDFS读取数据;
- YARN分配资源,Executor完成计算并返回结果。
核心特性
| 特性 | 说明 |
|---|---|
| SQL兼容性 | 支持大部分标准SQL语法,降低学习成本 |
| 扩展性 | 水平扩展依赖HDFS,可处理PB级数据 |
| 数据抽象 | 通过表、分区、桶(Bucket)组织数据,提升查询效率 |
| ACID支持 | 通过事务表(Transactional Table)实现插入/更新的原子性(需开启事务支持) |
| UDF扩展 | 支持自定义函数(User-Defined Functions)满足复杂需求 |
核心组件详解
MetaStore
- 存储数据库、表、列、分区、权限等元数据
- 默认使用内嵌Derby数据库,生产环境建议部署独立MySQL/PostgreSQL
- 元数据操作示例:
CREATE TABLE orders (id BIGINT, price DOUBLE) PARTITIONED BY (dt STRING)
分区与桶
- 分区(Partition):按字段值切割数据(如
dt='2023-01-01'),减少全表扫描 - 桶(Bucket):哈希分桶(如
CLUSTERED BY(user_id) INTO 10 BUCKETS),提升join效率 - 对比:
| 维度 | 分区 | 桶 |
|———–|————————-|————————-|
| 目的 | 减少扫描量 | 均匀分布数据,加速join |
| 使用场景 | 时间范围查询 | 关联查询优化 |
| 维护成本 | 动态添加(ALTER TABLE)| 固定数量,需重建表 |
- 分区(Partition):按字段值切割数据(如
存储格式
- 默认使用
TextFile,推荐ORC/Parquet格式(支持列式存储、压缩、索引) - 示例:
CREATE TABLE user_orc STORED AS ORC TBLPROPERTIES ('orc.compress'='SNAPPY')
- 默认使用
典型应用场景
| 场景 | 需求 | Hive实现方案 |
|---|---|---|
| 电商数据分析 | 统计每日订单量、销售额,用户行为分析 | 按日期分区+ORC存储,预计算聚合结果 |
| 金融风控审计 | 交易流水查询,异常模式识别 | 分区表+动态分区插入,结合窗口函数分析 |
| 物联网数据归档 | 设备传感器数据长期存储与历史查询 | 按设备ID分桶,压缩存储(Snappy+LZO) |
| 日志处理 | 网站访问日志分析,错误日志聚合 | 动态分区+正则表达式解析,生成报表 |
优势与局限
优势:
- 线性扩展能力,轻松应对EB级数据
- 标准化SQL降低开发门槛
- 与Hadoop生态无缝集成(如Sqoop导入、Zeppelin可视化)
局限性:
- 实时性差(分钟级延迟),不适合低延时场景
- 依赖HDFS,小文件过多会导致性能下降
- 复杂查询需优化执行计划(如避免全表扫描)
性能优化策略
| 优化方向 | 具体措施 |
|---|---|
| 数据存储 | 使用ORC格式+Snappy压缩,合理设置分区和分桶 |
| 查询执行 | 开启CBO(基于成本的优化器),限制EXPLAIN分析执行计划 |
| 资源配置 | 调整MapReduce任务并行度(set mapreduce.job.reduces=10) |
| 索引加速 | 创建Compacted/Bit-Shuffled索引(适用于频繁过滤字段) |
FAQs
Q1:Hive与传统关系型数据库(如MySQL)有什么区别?
A1:
| 对比维度 | Hive | 传统数据库(如MySQL) |
|——————–|—————————————–|———————————-|
| 数据规模 | 支持PB级数据,依赖HDFS扩展 | 受限于单机存储(TB级) |
| 计算模型 | 批量处理,适合离线分析 | 实时读写,支持事务 |
| 灵活性 | Schema-on-Read(读取时解析字段) | 严格的Schema定义 |
| 适用场景 | 大数据OLAP分析 | 在线事务处理(OLTP) |
Q2:如何提升Hive复杂查询的执行效率?
A2:
- 分区裁剪:确保查询条件包含分区字段(如
WHERE dt='2023-01-01') - 列式存储:使用ORC/Parquet格式减少IO开销
- 并行执行:启用
set hive.exec.parallel=true允许多任务并发 - 缓存中间结果:对频繁使用的中间表开启
CACHE功能 - 索引优化:为高频过滤字段创建Compacted索引(`CREATE IND