上一篇
分布式文件存储java
分布式文件存储Java指用Java实现跨多节点存储文件
分布式文件存储系统与Java实现深度解析
分布式文件存储核心概念
分布式文件存储通过将数据分散存储在多个节点上,实现数据的高可用性、可扩展性和高性能访问,其核心特性包括:
| 特性 | 说明 |
|---|---|
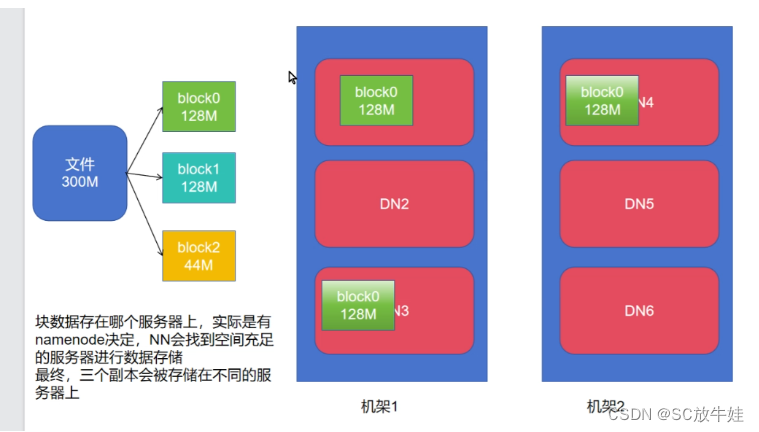
| 数据分片 | 将大文件拆分为多个块(Block)分布存储 |
| 元数据管理 | 记录文件名、块位置、权限等元信息 |
| 副本机制 | 每个数据块存储多份副本(如3副本)保证数据可靠性 |
| 负载均衡 | 动态分配存储节点,避免单点压力过大 |
| 容错处理 | 节点故障时自动切换到健康副本 |
Java作为企业级开发首选语言,在分布式存储领域具有天然优势,其丰富的生态(如Netty网络库、Protobuf序列化工具)和成熟的框架支持,使其成为构建高性能分布式系统的理想选择。
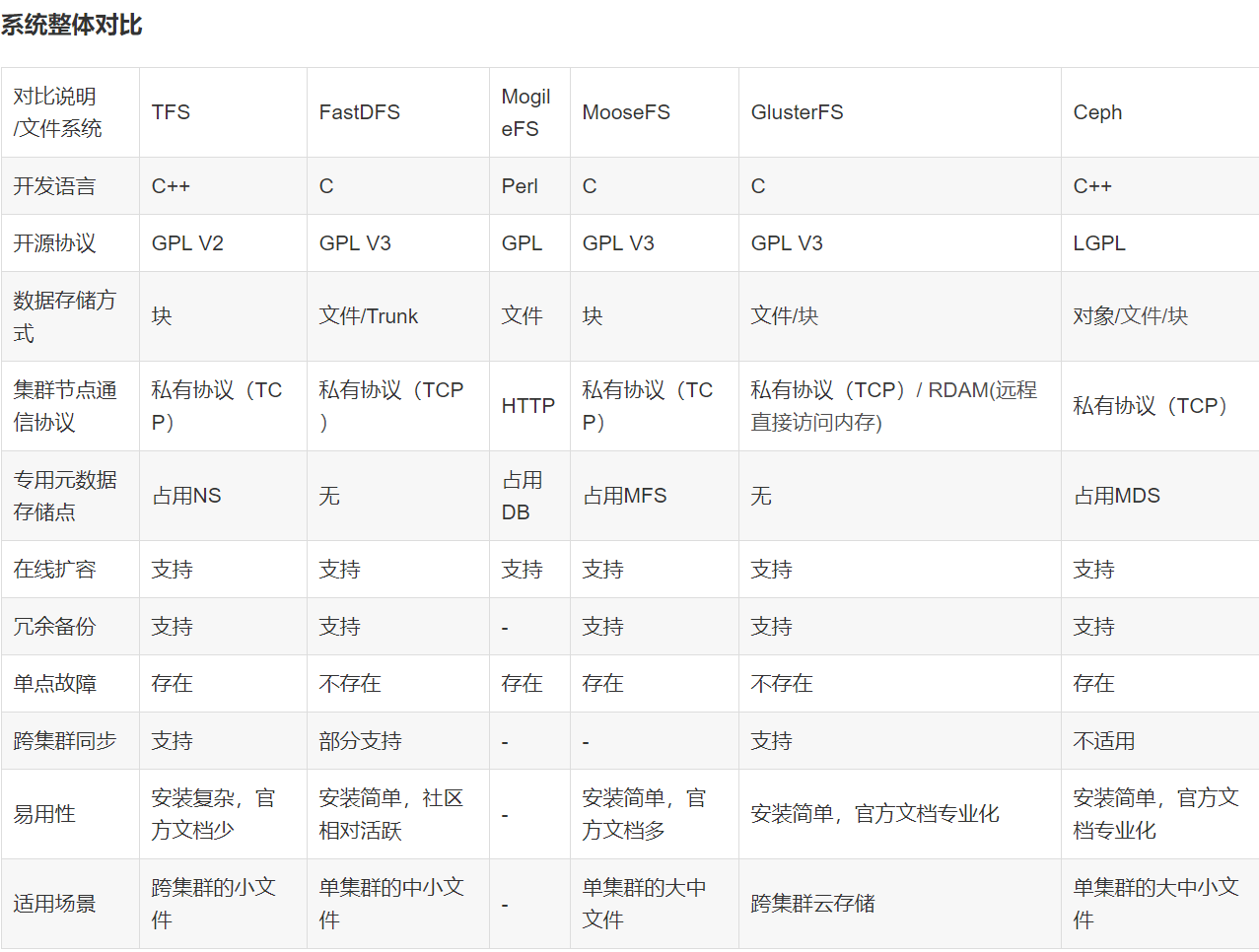
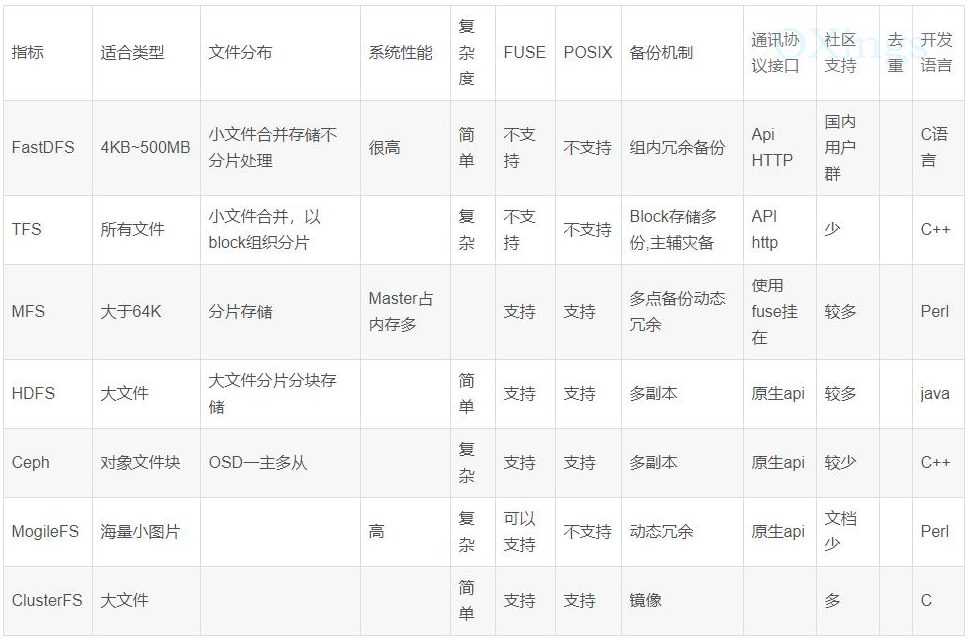
主流分布式文件存储方案对比
| 框架 | 语言支持 | 架构特点 | 适用场景 |
|---|---|---|---|
| Hadoop HDFS | Java | 主从架构,NameNode管理元数据 | 大数据批处理 |
| FastDFS | C/Java | 分组存储,Tracker管理 | 图片/视频等静态资源存储 |
| Ceph | C/Java | 统一存储,CRUSH算法 | 云存储/块存储 |
| MinIO | Go/Java | S3协议兼容,Erasure Code编码 | 对象存储,容器化部署 |
| JuiceFS | Java | POSIX兼容,Redis元数据 | 弹性文件系统,AI训练数据 |
Java开发者常选择HDFS(Hadoop生态系统)、MinIO(S3兼容)或自研系统,其中HDFS适合大数据场景,MinIO适合云原生对象存储,而JuiceFS则擅长弹性文件系统。

Java实现分布式文件存储的核心模块
- 客户端设计
- 分块策略:固定大小分块(如64MB)或智能分块(根据网络状况动态调整)
- 断点续传:记录已上传分块状态,支持失败重试
- 示例代码(MinIO Java SDK):
MinioClient client = MinioClient.builder() .endpoint("http://minio-server") .credentials("accessKey", "secretKey") .build();
// 上传文件分块
for (int partNumber = 0; partNumber < totalParts; partNumber++) {
byte[] partData = readFilePart(partNumber);
client.uploadPart(
UploadObjectArgs.builder()
.bucket(“mybucket”)
.object(“myfile.dat”)
.partNumber(partNumber + 1)
.stream(new ByteArrayInputStream(partData), partData.length, -1, null)
.build()
);
}
2. 元数据管理
存储方案:内存数据库(Redis)、关系型数据库(MySQL)、专用元数据服务
关键操作:文件创建/删除、块位置映射、权限校验
典型架构:
```mermaid
graph TD
A[客户端] --> B{元数据节点}
B --> C[数据库集群]
B --> D[心跳检测]
D -->|故障| E[元数据迁移]- 数据分片与副本机制
- 一致性哈希算法:将存储节点映射到哈希环,减少节点变动时的数据迁移
- 副本放置策略:机架感知策略(避免同一机架存放多个副本)
- 纠删码(Erasure Coding):相比3副本节省50%存储空间,但计算开销大
- 网络通信层
- RPC框架选择:gRPC(高性能)、Netty(灵活定制)、HTTP/REST(简单易用)
- 序列化协议:Protobuf(高效)、Avro(动态类型)、JSON(可读性好)
- 示例:基于Netty的自定义协议
public class FileTransferEncoder extends MessageToByteEncoder<FileChunk> { @Override protected void encode(ChannelHandlerContext ctx, FileChunk msg, ByteBuf out) { out.writeInt(msg.getChunkId()); out.writeBytes(msg.getData()); out.writeLong(msg.getChecksum()); } }
关键技术挑战与解决方案
- 数据一致性
- 强一致性:采用Raft/Paxos协议(如Ceph的Monitor集群)
- 最终一致性:允许短暂不一致,通过版本控制解决冲突(如Amazon S3)
- Java实现:使用Apache Curator实现ZooKeeper协调,或HashiCorp Raft库
- 故障检测与恢复
- 心跳机制:节点定期发送心跳(如每5秒),超时判定故障
- 数据重建:自动触发副本重建任务,优先选择网络延迟低的节点
- 示例流程:
sequenceDiagram Client->>StorageNode: 上传文件请求 StorageNode->>MetadataService: 注册块信息 MetadataService-->>StorageNode: 确认存储位置 StorageNode->>Client: 上传成功 Client->>StorageNode: 心跳检测超时 FaultToleranceService->>MetadataService: 标记节点失效 MetadataService-->>FaultToleranceService: 返回待重建块列表
- 性能优化
- 缓存策略:本地缓存(Caffeine)、分布式缓存(Redis)
- 并行传输:分块并行上传(限速控制防止网络拥塞)
- 压缩算法:Zstd(高压缩比) vs LZ4(高速)
实战案例:基于MinIO的Java对象存储
环境搭建
docker run -d --name minio -p 9000:9000 -e "MINIO_ACCESS_KEY=admin" -e "MINIO_SECRET_KEY=password" quay.io/minio/minio server /data
Java客户端操作
// 初始化客户端 MinioClient minioClient = MinioClient.builder() .endpoint("http://localhost:9000") .credentials("admin", "password") .build();
// 创建桶
boolean isCreated = minioClient.bucketExists(BucketExistsArgs.builder().bucket(“photos”).build());
if (!isCreated) {
minioClient.makeBucket(MakeBucketArgs.builder().bucket(“photos”).build());
}
// 上传文件
minioClient.uploadObject(
UploadObjectArgs.builder()
.bucket(“photos”)
.object(“2023/photo.jpg”)
.filename(“/path/to/local/photo.jpg”)
.contentType(“image/jpeg”)
.build()
);
3. 高级功能实现
预取数据:设置Prefetch标志,提前加载相邻块
版本控制:启用桶版本管理,保留历史版本
生命周期管理:设置过期策略自动清理旧数据
# 六、典型应用场景与最佳实践
| 场景 | 建议方案 | 关键参数 |
|---------------------|-----------------------------------|-----------------------------|
| 大数据分析 | Hadoop HDFS + Java客户端 | blocksize=128MB, replication=3 |分发 | MinIO + CDN加速 | 分片大小=5MB, 开启EC纠删码 |
| AI训练数据共享 | JuiceFS + Redis元数据 | 缓存大小=10GB, 条带宽度=64k |
| 日志归档 | FastDFS + Kafka持久化 | 分组存储,同步写3副本 |
最佳实践:
1. 冷热数据分离:高频访问数据使用SSD,冷数据转存HDD
2. 容量规划公式:`所需节点数 = (总数据量 × 副本数) / (单节点存储 × 纠删码效率)`
3. 监控指标:QPS、P99延迟、磁盘IO利用率、网络带宽饱和度
# 七、常见问题与解决方案
FAQs
Q1: 如何选择合适的分布式文件存储框架?
A: 根据业务需求评估:
大数据批处理 → Hadoop HDFS(成熟生态)
云原生应用 → MinIO(S3兼容)
弹性文件系统 → JuiceFS(POSIX兼容)
多媒体存储 → FastDFS(轻量级)
需考虑社区活跃度、二次开发成本、硬件兼容性等因素,建议初期采用开源方案,后期根据规模增长逐步优化。
Q2: 如何处理节点故障时的数据恢复?
A: 实施三级恢复机制:
1. 实时监控:通过Prometheus+Grafana监控节点状态
2. 自动迁移:使用Curator实现ZooKeeper协调,触发数据重建任务
3. 离线修复:定期执行数据完整性检查(MD5/SHA校验),生成修复报告
示例代码片段:
```java
public void handleNodeFailure(String failedNodeId) {
List<DataBlock> affectedBlocks = metaDataService.queryBlocksByNode(failedNodeId);
for (DataBlock block : affectedBlocks) {
List<String> newNodes = storageScheduler.selectNewNodes(block.getReplicationFactor());
for (String newNode : newNodes) {
byte[] data = fetchDataFromOtherReplica(block);
rpcClient.sendCopyRequest(newNode, block, data);
}