上一篇
分布式文件存储代码
分布式架构,数据分片与冗余备份,一致性哈希优化分布,元数据管理高效,确保高可用、
分布式文件存储代码实现详解
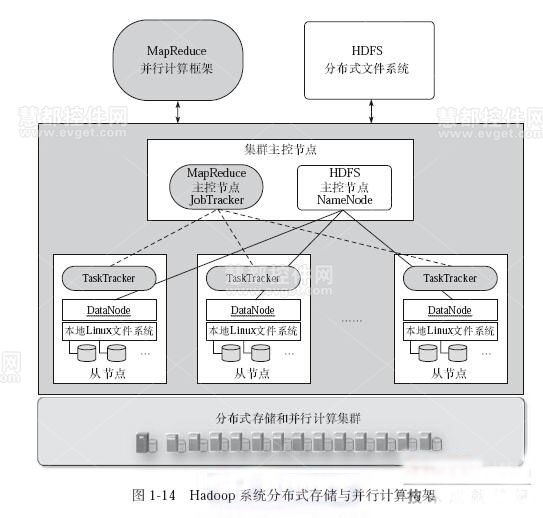
分布式文件存储系统是现代云计算和大数据基础设施的核心组件,其设计目标是通过多节点协作实现数据的可靠存储、高效访问和横向扩展,以下从架构设计、核心组件、代码实现三个维度展开分析,并提供关键代码示例。
系统架构设计
分布式文件存储系统通常采用Master-Slave架构或去中心化架构,核心模块包括:

- 元数据服务(Metadata Service):管理文件元信息(如文件名、块位置、权限)
- 存储节点(Storage Node):实际存储数据块
- 客户端(Client):提供文件上传/下载接口
- 心跳监测(Heartbeat):监控节点健康状态
| 组件 | 功能 | 技术选型示例 |
|---|---|---|
| 元数据服务 | 文件命名空间管理、块定位 | etcd/ZooKeeper |
| 存储节点 | 数据分块存储、副本管理 | MinIO/Ceph |
| 客户端 | 文件切分、并行传输 | Java/Python/SDK |
| 心跳监测 | 节点故障检测 | gRPC/HTTP |
核心组件实现
元数据服务(Python Flask示例)
from flask import Flask, request, jsonify
import hashlib
app = Flask(__name__)
metadata_store = {} # 内存中的元数据存储(实际应持久化)
@app.route('/upload', methods=['POST'])
def upload_file():
file_id = request.json['file_id']
chunk_index = request.json['chunk_index']
storage_node = request.json['storage_node']
# 生成文件元数据记录
metadata_store[file_id] = metadata_store.get(file_id, {
'chunks': [],
'replicas': 3 # 默认副本数
})
metadata_store[file_id]['chunks'].append({
'index': chunk_index,
'node': storage_node
})
return jsonify({'status': 'success'}), 200
@app.route('/get_file_info/<file_id>', methods=['GET'])
def get_file_info(file_id):
return jsonify(metadata_store.get(file_id, 'Not Found')), 200
if __name__ == '__main__':
app.run(port=5000)一致性哈希算法(Python实现)
import hashlib
from bisect import bisect_left
class ConsistentHash:
def __init__(self, nodes=None, replicas=3):
self.replicas = replicas
self.ring = []
self.node_map = {}
if nodes:
self.add_nodes(nodes)
def add_node(self, node):
for i in range(self.replicas):
key = self.hash_func(f"{node}:{i}")
self.ring.append(key)
self.node_map[key] = node
self.ring.sort()
def get_node(self, key_str):
key = self.hash_func(key_str)
idx = bisect_left(self.ring, key)
return self.node_map[self.ring[idx % len(self.ring)]]
def hash_func(self, key):
return int(hashlib.md5(key.encode()).hexdigest, 16)存储节点服务(Python FastAPI示例)
from fastapi import FastAPI, File, UploadFile
import os
app = FastAPI()
storage_dir = '/data/storage' # 实际应配置分布式存储路径
@app.post('/upload_chunk/{file_id}/{chunk_index}')
async def upload_chunk(file_id: str, chunk_index: int, file: UploadFile = File(...)):
file_path = os.path.join(storage_dir, file_id, f"chunk_{chunk_index}")
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, 'wb') as f:
f.write(await file.read())
return {"status": "chunk saved"}
@app.get('/download_chunk/{file_id}/{chunk_index}')
async def download_chunk(file_id: str, chunk_index: int):
file_path = os.path.join(storage_dir, file_id, f"chunk_{chunk_index}")
return StreamingResponse(open(file_path, 'rb'), media_type='application/octet-stream')关键挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 节点故障 | 心跳检测 + 自动副本重建(示例:定期扫描失联节点并重新分配数据块) |
| 数据一致性 | 强一致性(Raft协议)或最终一致性(版本控制) |
| 动态扩展 | 一致性哈希虚拟节点 + 数据再平衡(示例:新增节点时逐步迁移数据) |
| 大文件传输优化 | 分块并行上传 + 断点续传(示例:客户端分片MD5校验) |
完整流程示例
文件上传:
- 客户端将文件切分为固定大小数据块(如1MB)
- 对每个块计算MD5哈希值,通过一致性哈希选择存储节点
- 并行上传数据块到不同节点,同时向元数据服务注册块信息
文件下载:
- 客户端查询元数据服务获取块位置信息
- 并行下载所有数据块
- 校验每个块的MD5值,按顺序合并为原始文件
FAQs
Q1: 如何保证数据在节点故障时的可用性?
A1: 通过数据副本机制(如3副本)实现冗余存储,当检测到节点故障时,元数据服务会自动触发副本重建流程,从存活节点复制数据到新节点。
Q2: 如何处理海量小文件的存储效率问题?
A2: 可采用合并存储策略,将多个小文件打包为大的数据块存储,或使用分级存储(如将元