上一篇
分布式存储原理归纳
分布式存储通过数据分片、冗余备份及节点协作,实现高可用、容错
分布式存储原理归纳
基本概念与架构设计
分布式存储是一种通过多台服务器协同工作,将数据分散存储在多个节点上的技术,其核心目标是解决传统集中式存储的容量瓶颈、性能限制和单点故障问题,典型架构包含以下模块:
| 模块 | 功能描述 |
|---|---|
| 客户端(Client) | 负责发起数据读写请求,与存储系统交互。 |
| 元数据服务(Metadata Service) | 管理文件/数据块的元信息(如位置、权限),常见实现如HDFS的NameNode。 |
| 存储节点(Storage Node) | 实际存储数据块,提供读写能力,通常以集群形式部署。 |
| 协调服务(Coordination Service) | 负责节点状态管理、负载均衡和故障恢复(如ZooKeeper)。 |
数据分布与分片策略
数据分片(Sharding)
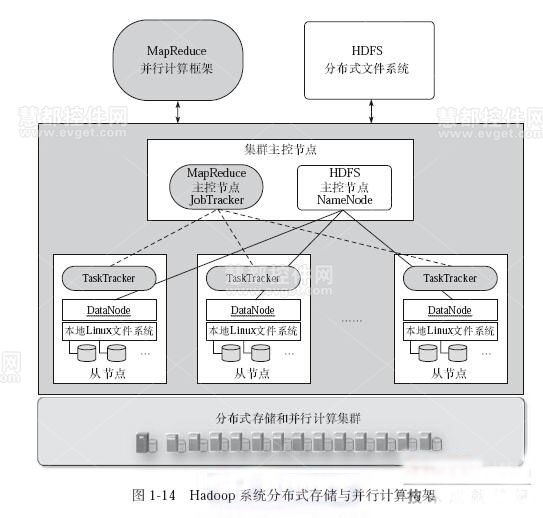
将数据划分为固定大小的块(如HDFS的128MB块),分散存储到不同节点,分片规则直接影响负载均衡和扩展性:- 哈希分片:根据数据键的哈希值取模分配节点,但存在节点增减时的数据重分布问题。
- 一致性哈希(Consistent Hashing):通过虚拟节点缓解哈希分片的缺陷,支持动态扩容(如图1)。
副本机制
为保证高可用,每个数据块会存储多份副本(如3副本),副本分布需遵循:- 跨机架/数据中心:避免单点故障导致数据不可用。
- 读写分离:主副本负责写操作,从副本用于读请求分流。
冗余与容错机制
数据冗余策略
| 策略 | 原理 | 适用场景 |
|—————|————————————-|—————————|
| 副本复制 | 完全复制数据块,简单高效 | 对一致性要求高的场景(如数据库) |
| 纠删码(Erasure Coding) | 通过算法生成冗余校验块,减少存储开销 | 大容量冷数据存储(如云存储) |
故障检测与恢复
- 心跳机制:存储节点定期向协调服务发送心跳,超时则标记为故障。
- 自动重建:故障节点的数据副本会被其他节点重新生成(如Ceph的PG修复)。
一致性模型与协议
CAP定理的权衡
分布式存储无法同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance),典型策略:- 强一致性:如Spanner的全局时钟,牺牲部分可用性。
- 最终一致性:如DynamoDB,允许短暂数据不一致以提升性能。
分布式协议
- Paxos/Raft:用于元数据服务的日志复制(如Etcd的选举机制)。
- Gossip协议:轻量级节点状态同步(如Cassandra的环状拓扑维护)。
扩展性与性能优化
水平扩展
- 无共享架构:新增节点只需接入集群,无需修改现有数据(如对象存储的扁平化设计)。
- 数据再平衡:扩容时通过哈希环迁移部分数据,避免全量重构。
性能优化
- 本地缓存:客户端缓存元数据和热点数据(如Redis加速元数据访问)。
- 并行读写:将大文件拆分为多个块并行处理(如HDFS的Pipeline写入)。
典型系统对比
| 系统 | 数据模型 | 一致性 | 冗余策略 | 适用场景 |
|---|---|---|---|---|
| HDFS | 块存储 | 强一致性 | 3副本 | 大数据分析 |
| Ceph | 对象/块 | 可配置(默认最终一致) | 纠删码/副本 | 云存储基础设施 |
| Cassandra | 列族 | 最终一致性 | 副本树 | 高可用NoSQL数据库 |
| Amazon S3 | 对象 | 读后写一致性 | 跨区域副本 | 互联网应用静态资源存储 |
FAQs
Q1:分布式存储如何应对节点故障?
A1:通过冗余副本和自动故障转移机制,当检测到节点失效时,系统会从其他副本读取数据,并在新节点上重建丢失的副本,HDFS的NameNode会监控DataNode状态,触发副本复制流程。
Q2:选择纠删码还是副本策略的关键因素是什么?
A2:主要考虑存储成本和性能需求,纠删码存储效率更高(如1.5倍存储开销 vs 3倍副本),但计算复杂度高,适合冷数据;副本策略延迟低,适合频繁