
上一篇
hdfs能存储图片吗
HDFS可存储图片,支持大文件及二进制数据,适合分布式存储图片,需注意块大小与访问
HDFS(Hadoop Distributed File System)作为大数据生态系统中的核心存储组件,其设计初衷是处理海量非结构化数据,关于能否存储图片的问题,答案是肯定的,但需结合其特性与实际需求进行优化,以下从技术原理、适用场景、操作实践等多维度展开分析。
HDFS存储图片的可行性分析
| 特性 | HDFS | 传统文件系统(如NFS) | 对象存储(如AWS S3) |
|---|---|---|---|
| 数据规模 | 支持EB级数据存储 | 受限于单节点容量 | 支持PB级数据 |
| 文件类型 | 任何二进制/文本文件(包括图片) | 无限制 | 任何类型 |
| 访问延迟 | 高(适合批量处理,不适合低延迟场景) | 低 | 中等(依赖网络) |
| 扩展性 | 横向扩展(添加节点即可扩容) | 纵向扩展(受限于硬件) | 横向扩展 |
| 数据冗余 | 3x副本(可配置)确保高可用 | RAID或备份策略 | 多区域冗余存储 |
:HDFS在技术上完全支持图片存储,但其性能表现与图片的使用场景密切相关。
HDFS存储图片的优势
海量数据管理
当图片数量达到百万级甚至更多时,HDFS的分布式架构可通过横向扩展轻松管理,1亿张平均大小为1MB的图片(总数据量约100TB),HDFS可通过增加DataNode节点实现线性扩容。高容错与可靠性
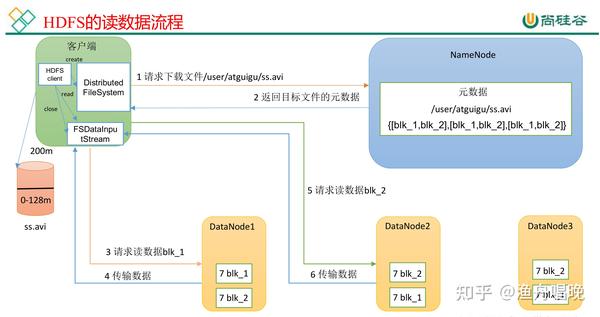
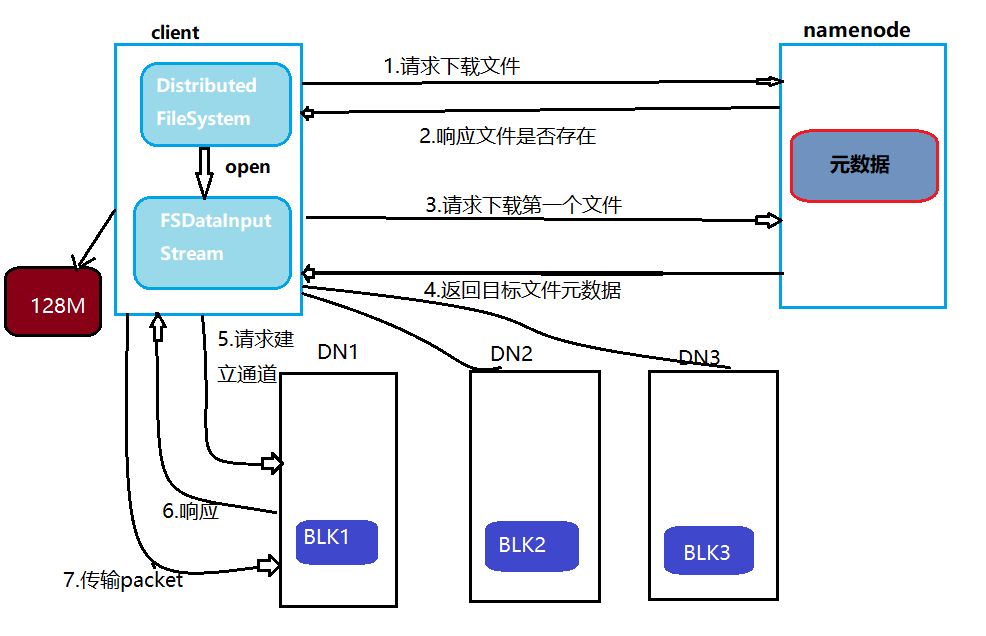
每张图片会被自动分割为多个Block(默认128MB,可调整),并存储3份副本在不同节点,即使某个节点故障,图片仍可通过其他副本恢复。
批处理友好
若需对图片进行大规模处理(如特征提取、格式转换),HDFS可直接与MapReduce、Spark等计算框架集成,实现“存储-计算”一体化。低成本存储
HDFS可部署在廉价PC服务器上,相比专用NAS/SAN设备成本更低,适合冷数据存储(如归档类图片)。
HDFS存储图片的挑战与解决方案
小文件问题
- 问题:单张图片通常小于128MB(如手机照片约2-5MB),若直接存储会导致大量小Block,浪费NameNode内存并降低读写效率。
- 解决方案:
- 合并小文件:使用
Hadoop Archives(HAR)或第三方工具(如Facebook的Haystack)将多张图片打包为大文件。 - 调整Block大小:将Block尺寸从128MB缩小至64MB或更小,但需权衡内存消耗。
- 分层存储:将高频访问的小文件迁移至对象存储(如MinIO),仅保留大文件在HDFS。
- 合并小文件:使用
元数据压力
- 问题:NameNode需维护文件路径、Block位置等元数据,百万级图片可能导致内存溢出。
- 解决方案:
- 启用联邦模式:通过多个NameNode分摊元数据压力。
- 使用Secondary NameNode:定期合并EditLog,减少主NameNode负载。
访问延迟
- 问题:HDFS的读写依赖RPC调用,单张图片的读取延迟可能达数百毫秒,不适合实时场景。
- 解决方案:
- 缓存加速:部署Alluxio(原Tachyon)等内存缓存层,将热图加载至内存。
- 协议优化:启用WebHDFS或FUSE模块,通过HTTP/POSIX接口提升访问效率。
实际操作步骤
环境准备
- 部署Hadoop集群(至少1个NameNode + 3个DataNode)。
- 调整
dfs.replication参数(默认3,可根据需求降低)。 - 修改Block大小(
dfs.blocksize),例如设置为64MB:hadoop dfs -setrep -w 64MB /path/to/images
上传图片
- 命令行工具:
hadoop fs -put /local/image/directory /hdfs/image/directory
- 程序化接口:通过Java API或Python的
pydoop库批量上传。
- 命令行工具:
访问图片
- 直接下载:
hadoop fs -get /hdfs/image/directory/image.jpg /local/path
- Web访问:启用WebHDFS,通过URL访问:
http://namenode:50070/webhdfs/v1/image.jpg?op=OPEN
- 直接下载:
性能监控
- 使用Hadoop自带的
hdfs dfsadmin -report查看存储使用情况。 - 通过YARN ResourceManager监控DataNode负载。
- 使用Hadoop自带的
典型应用场景
| 场景 | 说明 |
|---|---|
| 人工智能训练数据 | 存储数百万张标注图片,供TensorFlow/PyTorch分布式训练读取。 |
| 日志增强分析 | 日志文件中嵌入截图(如错误页面),通过HDFS统一管理。 |
| 冷数据归档 | 将低频访问的历史图片迁移至HDFS,节省对象存储成本。 |
| 分发 | 结合CDN,将HDFS作为源存储,通过脚本同步热门图片至边缘节点。 |
相关问答FAQs
Q1:HDFS适合存储实时访问的图片吗?
A:不适合,HDFS设计目标是高吞吐而非低延迟,单次读取延迟通常在百毫秒级,实时场景建议使用Redis(内存缓存)或对象存储(如OSS)搭配CDN加速。
Q2:如何在HDFS中按图片创建日期分类存储?
A:可利用HDFS的目录结构模拟分区表,按年份/月份创建子目录:
hadoop fs -mkdir -p /images/2023/10/01 hadoop fs -put local_image.jpg /images/2023/10/01
后续通过hdfs dfs -ls /images/2023/10/01快速定位特定日期的图片。
相关文章
爬虫数据存储hdfs_HDFS数据
DFS挂载文件存储HDFS

服务器可以存储图片吗
高性能存储:闪存存储技术的崛起「高性能存储:闪存存储技术的崛起与发展」
SVN服务器更新:取消FSFS文件系统 (svn服务器取消fsfs)
一个关于MySQL数据库中LIMIT和OFFSET用法的疑问句标题可以这样写,,MySQL查询优化,LIMIT 2、LIMIT 2,3与LIMIT 2 OFFSET 3有何区别?,清晰地表达了文章的核心主题,即探讨MySQL中LIMIT和OFFSET的不同用法及其对查询结果的影响。同时,它遵循了SEO原则,包含了关键词MySQL、LIMIT和OFFSET,有助于搜索引擎更好地理解和索引文章内容。此外,通过使用疑问句形式,标题还吸引了读者的注意力,激发了他们点击阅读的兴趣。
实用操作指南:DFS文件服务器的部署与管理简介 (部署并管理文件服务器dfs)

高性能存储服务器_高性能存储

离散傅里叶变换(DFT)是一种将时域信号转换为频域信号的数学工具。它通过傅里叶分析,把时间或空间域中的信号转换到频率域,从而揭示信号的频谱结构和变化规律。,基于DFT的原理和特性,我们可以提出以下疑问,,如何优化DFT算法以减少计算复杂度?,要学以致用,您可以思考如何运用快速傅里叶变换(FFT)算法来降低离散傅里叶变换(DFT)的计算复杂度。FFT通过递归分治策略将长序列分解为更短的序列,从而显著减少了乘法运算的次数。探索如何实现这一优化,并考虑其在实际信号处理中的应用。








