上一篇
分布式文件存储mi
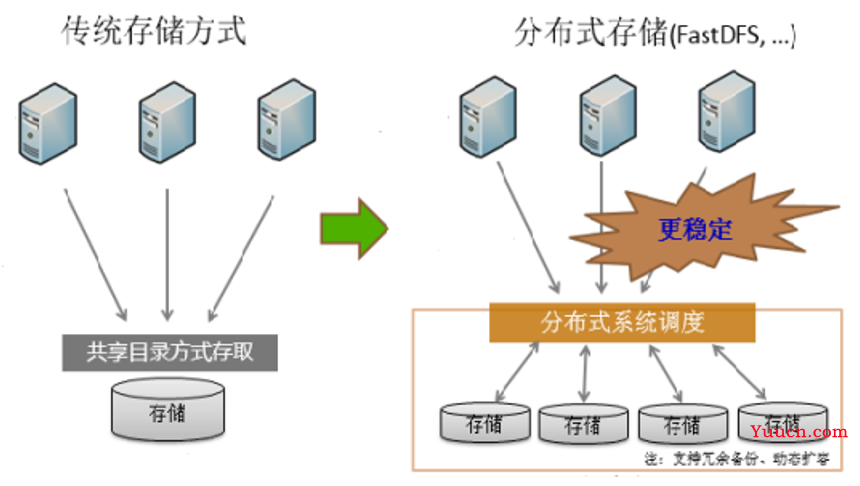
分布式文件存储通过将数据分块并冗余存储于多节点,实现高可用与扩展性,采用元数据管理与负载均衡,支持海量数据并发访问,广泛应用于云计算、大数据分析等场景,保障数据可靠性与读写性能
核心架构与组件
分布式文件存储系统通常由以下关键组件构成:

| 组件 | 功能描述 |
|---|---|
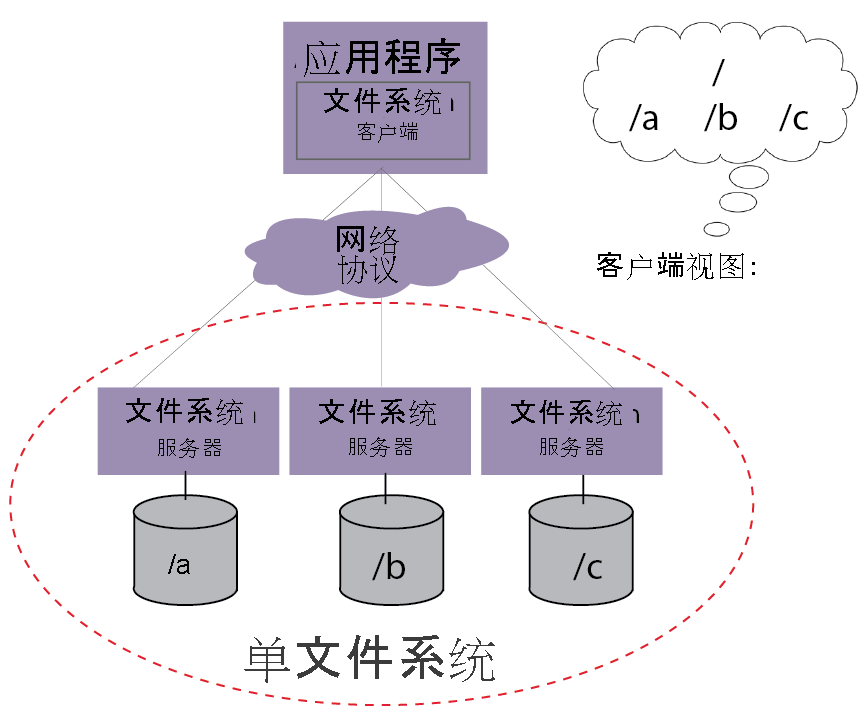
| 客户端(Client) | 负责发起文件读写请求,与元数据服务器和数据节点交互。 |
| 元数据服务器(MDS) | 管理文件元数据(如目录结构、权限、块位置),协调客户端与数据节点的交互。 |
| 数据节点(Storage Node) | 实际存储文件数据块,负责数据的读写、复制和恢复。 |
| 监控与管理模块 | 监控系统状态、负载均衡、故障检测与恢复,保障系统稳定性和性能。 |
典型架构模式
主从架构(如HDFS)
- 单一元数据服务器(Master)管理全局元数据,数据节点(Slave)负责存储。
- 优点:元数据管理简单,适合写密集型场景。
- 缺点:元数据服务器成为性能瓶颈,存在单点故障风险。
去中心化架构(如Ceph、GlusterFS)
- 元数据和数据均匀分布到多个节点,无单点故障。
- 优点:高可用、易扩展。
- 缺点:元数据管理复杂,需高效共识协议(如Paxos、Raft)。
核心技术与实现机制
数据分片与冗余
- 数据分片:将大文件拆分为固定大小的数据块(如64MB),分散存储到不同节点。
- 冗余机制:
- 副本策略:每个数据块存储多份副本(如3份),提升容错性(如HDFS)。
- 纠删码(Erasure Coding):通过算法生成冗余数据块(如k+m模式),减少存储开销(如Ceph)。
元数据管理
- 集中式元数据:单一MDS管理所有元数据,结构简单但扩展性差(如HDFS)。
- 分布式元数据:元数据分片存储,通过共识协议保证一致性(如Ceph的CRUSH算法)。
一致性与容错
- 强一致性:通过分布式锁或事务协议(如两阶段提交)确保数据一致,但性能较低。
- 最终一致性:允许短暂不一致,通过版本控制或冲突解决机制修复(如DNSMX的CAP理论权衡)。
优势与挑战
优势
| 场景 | 价值体现 |
|---|---|
| 海量数据存储 | 横向扩展能力,支持EB级数据规模。 |
| 高可用性 | 数据冗余和自动故障转移,保障服务连续性。 |
| 高性能读写 | 并行化数据访问,降低延迟(如GlusterFS的客户端直读模式)。 |
挑战
- 元数据瓶颈:集中式架构中MDS可能成为性能瓶颈。
- 数据一致性:分布式环境下保证强一致性成本高。
- 故障恢复:节点故障时数据重建和负载均衡复杂度高。
典型应用场景
| 场景 | 需求特点 | 适配技术 |
|---|---|---|
| 云计算存储 | 弹性扩展、多租户隔离 | Ceph、MinIO |
| 大数据分析 | 高吞吐量、低延迟随机读写 | HDFS、BeeGFS |
| 冷数据归档 | 低成本、高可靠性 | 纠删码优化的分布式存储(如OpenStack Swift) |
相关问答FAQs
Q1:分布式文件存储与分布式块存储的区别是什么?
- 文件存储:以文件为单位管理数据,支持POSIX标准接口,适合通用场景(如日志、视频)。
- 块存储:将存储划分为固定大小的块,通过iSCSI或NVMe协议访问,适合数据库、虚拟机。
Q2:如何优化分布式文件存储的性能?
- 数据本地化:优先从本地节点读取热数据,减少网络传输。
- 缓存机制:在客户端或中间层部署缓存(如LRU缓存)。
- 负载均衡:动态调整数据分布,避免节点过载。
通过上述分析可见,分布式文件存储通过架构创新和技术优化,解决了传统存储的局限性,但其设计与运维仍需在一致性、扩展性和性能之间权衡,未来随着软硬件协同优化(如RDMA网络、GPU加速元数据处理),其应用潜力将进一步释放