上一篇
分布式文件存储介绍
分布式文件存储通过多节点协同,将数据分块存储并冗余备份,保障高可用与扩展性,确保数据
分布式文件存储系统详解
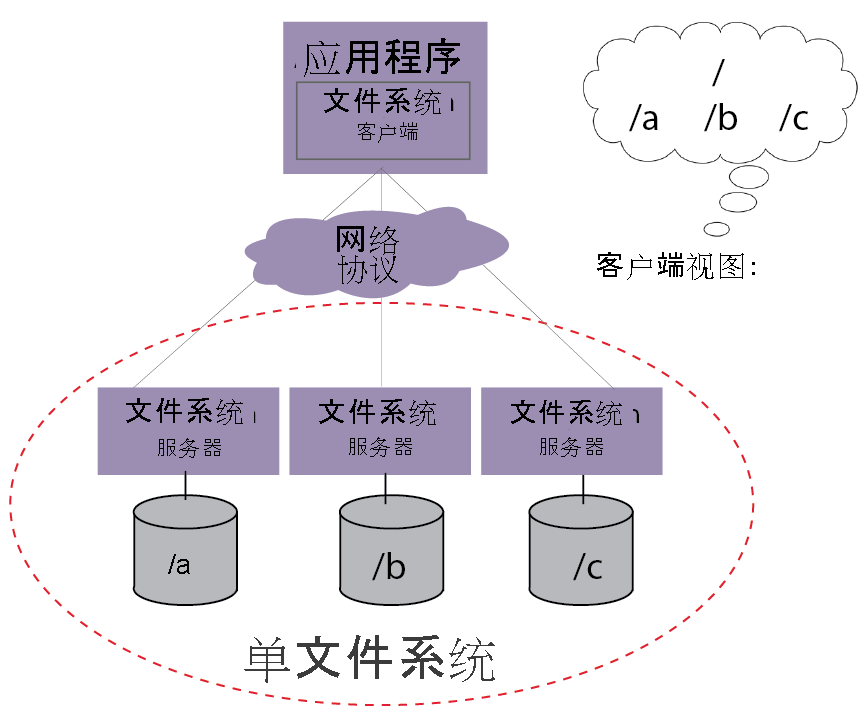
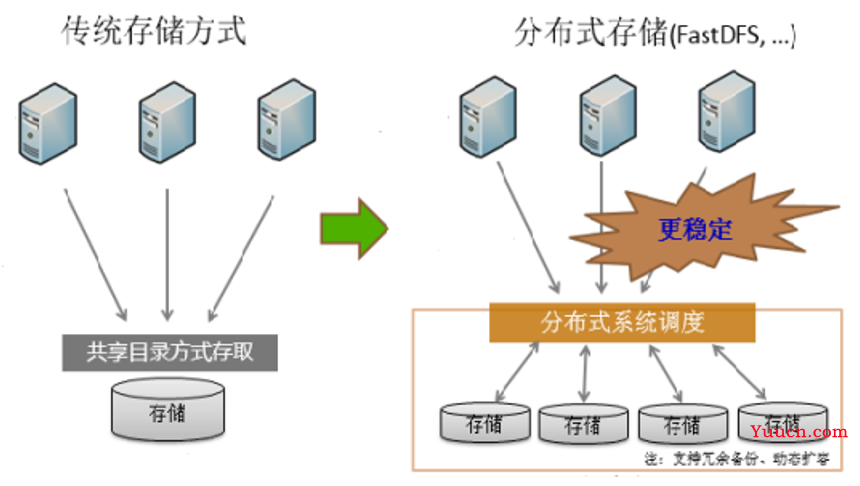
传统存储系统的局限性
在信息技术发展早期,企业普遍采用集中式存储架构(如NAS/SAN)或本地服务器存储文件,随着数据量指数级增长和业务复杂度提升,传统存储暴露出明显缺陷:
| 痛点 | 具体表现 |
|---|---|
| 容量瓶颈 | 单节点存储上限受限,扩展需停机改造 |
| 性能天花板 | 并发访问时IOPS不足,带宽成为瓶颈 |
| 可靠性风险 | 单点故障导致服务中断,硬件故障可能造成数据永久丢失 |
| 地理限制 | 数据访问受限于物理位置,跨地域协作效率低下 |
| 成本结构失衡 | 过度依赖高端硬件,扩容成本与容量不成正比 |
分布式文件存储的核心特征
分布式文件存储通过软件定义方式将多台普通服务器组合成存储集群,具备以下关键特性:
弹性扩展能力
- 横向扩展:通过增加节点线性提升容量和性能
- 动态扩容:无需停机即可完成节点增减
- 典型指标:EB级存储规模支持,百万级QPS处理能力
高可用架构
- 数据冗余:采用副本(如HDFS 3副本)或纠删码(如Ceph CRUSH算法)
- 故障自愈:自动检测坏块并触发数据重建
- 多活部署:支持跨机架/机房/地域的多副本存储
性能优化机制
- 数据分片:将大文件拆分为固定大小的数据块(如HDFS默认128MB)
- 负载均衡:基于哈希或一致性哈希的智能调度算法
- 就近访问:结合CDN技术实现边缘节点缓存加速
元数据管理

- 独立命名空间:维护文件目录树结构及权限体系
- 分布式锁机制:保障并发操作的原子性
- 索引优化:采用分布式数据库(如Ceph使用MongoDB)存储元数据
关键技术架构解析
现代分布式文件存储系统通常包含以下核心组件:
| 模块 | 功能描述 |
|---|---|
| 客户端SDK | 提供标准API接口(POSIX/REST/S3协议),支持多平台访问 |
| 网关层 | 负责请求路由、负载均衡、安全认证(如Kerberos集成) |
| 元数据服务 | 管理文件命名空间、权限控制、目录结构(常采用ZooKeeper或Etcd实现) |
| 数据存储节点 | 实际存储文件分片,执行数据读写操作(如Ceph OSD节点) |
| 监控告警系统 | 实时采集系统指标(Prometheus+Granfana),异常自动触发恢复机制 |
典型数据流转过程:
- 客户端发起文件写入请求
- 网关层进行身份验证和权限校验
- 元数据服务生成文件索引记录
- 数据分片后按策略分配至存储节点
- 存储节点返回写入确认并同步副本
- 客户端获取操作结果
主流分布式文件存储方案对比
| 系统名称 | 架构特点 | 适用场景 | 核心优势 |
|---|---|---|---|
| HDFS | 主从架构,二次开发生态完善 | 大数据批处理(Hadoop生态) | 高吞吐量、低成本硬件适配 |
| Ceph | 统一存储(对象/块/文件) | 云存储、混合云环境 | 高度可扩展、CRUSH算法智能分布 |
| GlusterFS | 纯用户态设计,无元数据服务 | 中小规模企业存储 | 零配置部署、Linux原生兼容 |
| JuiceFS | 对象存储之上的文件系统 | 云原生应用、容器化环境 | 无缝对接公有云、弹性按需付费 |
| BeeGFS | 高性能并行文件系统 | 科学计算、基因测序等IO密集型场景 | 低延迟、高聚合带宽 |
核心算法与协议实现
数据分片策略
- 哈希分片:根据文件名计算一致性哈希值分配节点
- 范围分片:按文件大小划分存储区间(适用于顺序读写场景)
- 混合策略:结合时间戳和热度进行动态分片
一致性保障机制
- Paxos/Raft协议:用于元数据服务的分布式共识
- 版本向量(Vector Clocks):解决并发修改冲突
- 乐观锁机制:允许高并发下的最终一致性
网络传输优化
- RDMA技术:实现远程内存直接访问,降低延迟
- 数据压缩:采用Zstandard/Snappy算法减少传输量
- 差异同步:仅传输变更数据块(如rsync算法)
典型应用场景
大数据分析平台
- 案例:某金融机构使用HDFS存储PB级交易日志,支撑Spark实时风控分析
- 收益:存储成本降低60%,分析任务提速4倍
云存储服务
- 案例:阿里云OSS融合JuiceFS实现混合云存储,支持弹性扩容
- 收益:客户无需改造现有应用,冷热数据自动分层
影视渲染农场
- 案例:Weta Digital采用Ceph集群存储4K素材,通过BeeGFS加速并行渲染
- 收益:渲染效率提升70%,存储利用率达92%
实施建议与技术选型
评估维度
- 数据特征:结构化/非结构化、读写模式(顺序/随机)
- 性能需求:IOPS要求、延迟敏感度
- 成本预算:硬件投入、运维复杂度、扩容成本
- 生态兼容性:是否需要对接现有大数据平台
常见组合方案
| 场景 | 推荐方案 | 理由 |
|———————|———————————–|————————————–|
| Hadoop生态 | HDFS + ZooKeeper | 原生兼容,社区支持成熟 |
| 混合云存储 | MinIO + JuiceFS | S3协议兼容,跨云迁移方便 |
| 超算中心 | BeeGFS + Lustre | 高吞吐低延迟,并行文件处理优化 |
FAQs
Q1:分布式文件存储与对象存储的本质区别是什么?
A1:核心差异体现在数据访问接口和存储模型:
- 文件存储:保留传统文件系统语义,支持POSIX标准操作,适合需要文件权限管理、目录结构的场景
- 对象存储:采用扁平化键值对模型(如S3 API),天然适合互联网应用,但缺乏文件系统特性
典型组合方案:Ceph同时支持文件/对象存储,JuiceFS在对象存储上构建文件系统。
Q2:如何保障分布式环境下的数据一致性?
A2:主要通过三种机制实现:
- 强一致性协议:使用Raft/Paxos算法保证元数据服务一致(如Ceph MON集群)
- 版本控制:为每个文件维护版本号,冲突时基于版本合并
- 事务日志:记录所有变更操作,支持故障恢复(如HDFS EditLog)
不同系统在一致性强度上有所取舍,例如HDFS选择最终一致性以提升性能,而Ceph通过CRUSH map实现数据