上一篇
分布式数据处理系统能干啥
分布式数据处理系统能高效处理海量数据,实现分布式存储与计算,提升可靠性及扩展性,支持实时分析与复杂任务
分布式数据处理系统的核心功能与应用场景解析
分布式数据处理系统通过将数据分散存储在多个节点上,并利用并行计算能力实现高效处理,已成为现代大数据时代的核心技术架构,其核心价值在于突破单机性能瓶颈,解决海量数据的存储、计算与分析难题,以下从技术特性、核心功能及典型应用场景三个维度展开详细说明。

技术特性与核心优势
| 特性 | 说明 |
|---|---|
| 横向扩展性 | 通过增加节点数量线性提升处理能力,支持PB级数据存储与计算 |
| 高容错性 | 数据自动冗余备份(如HDFS的3副本机制),节点故障时任务自动迁移 |
| 低成本 | 可基于普通PC服务器集群构建,相比小型机方案成本降低80%以上 |
| 实时性 | 支持批处理(小时级)、流处理(毫秒级)混合模式 |
| 地理分布 | 节点可部署在不同数据中心,实现全球数据就近处理 |
核心功能模块详解
海量数据存储管理
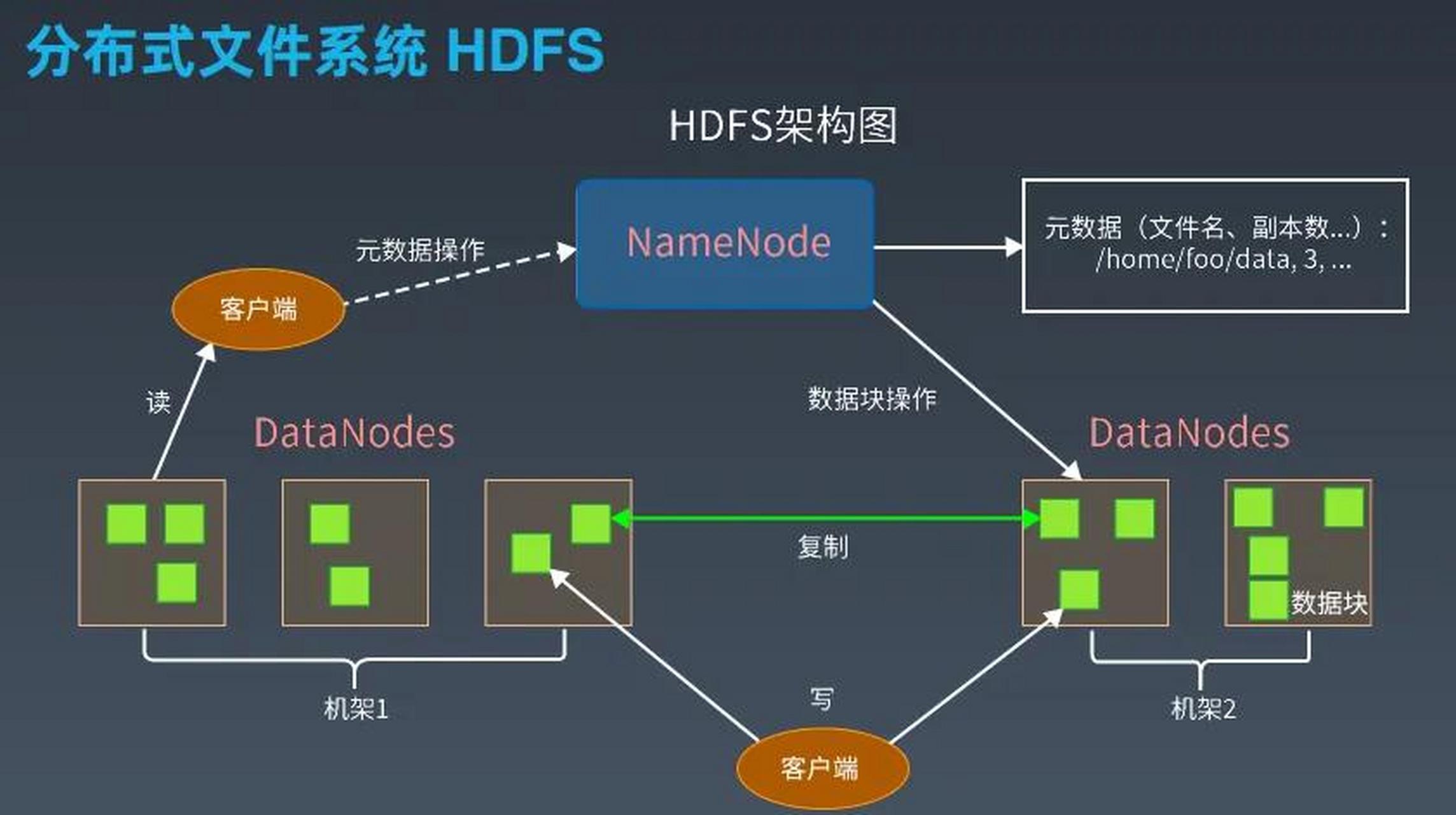
- 分布式文件系统:采用分块存储(如HDFS将文件切分为64MB块)、元数据管理(NameNode记录块位置)
- 数据压缩优化:列式存储(Parquet/ORC)、智能压缩算法(Snappy/LZO)降低50%存储空间
- 冷热数据分层:热数据(频繁访问)存SSD,冷数据(历史归档)存HDD或对象存储
- 多模数据支持:结构化(MySQL Binlog)、半结构化(JSON/XML)、非结构化(音视频)
并行计算引擎
| 计算框架 | 适用场景 | 性能特征 |
|---|---|---|
| MapReduce | 离线批处理(日志分析、ETL) | 高吞吐量,延迟小时级 |
| Spark | 迭代计算、机器学习 | 内存计算,速度较MapReduce快10倍 |
| Flink | 实时流处理(窗口计算、CEP) | 亚秒级延迟,精确状态管理 |
| GraphX | 图计算(社交网络分析) | 分布式图遍历,支持千亿边规模 |
实时数据处理
- 流批一体处理:Flink/Spark Streaming统一API处理实时与离线数据
- 事件时间处理:Watermark机制解决乱序数据,支持精确到毫秒的窗口计算
- 状态管理:Checkpoint/Savepoint实现故障恢复,RocksDB存储大规模状态
- 复杂事件处理:模式匹配(CEP)检测特定事件序列(如欺诈交易识别)
数据集成与治理
- 异构数据源接入:JDBC/ODBC连接器、Kafka实时采集、Flume日志收集
- 元数据管理:Hive Metastore维护表结构,Apache Atlas实现血缘追踪
- 数据质量监控:Great Expectations框架校验数据完整性、一致性
- 安全体系:Kerberos认证、Ranger权限控制、动态数据脱敏
智能调度优化
- 资源调度:YARN/Mesos动态分配CPU/内存,支持优先级队列
- 任务优化:谓词下推减少数据传输量,倾斜数据检测与自动均衡
- 成本控制:Spot Instance竞价实例降低云平台使用成本30%以上
- 多租户隔离:Kubernetes namespace实现资源配额管理
典型行业应用场景
互联网行业
| 场景 | 技术实现 |
|---|---|
| 用户行为分析 | Spark处理日志数据,ClickHouse实时查询,Elasticsearch全文检索 |
| 推荐系统 | ALS矩阵分解算法,Flink实时更新用户画像 |
| 搜索排序 | Hadoop集群预处理文档,Lucene索引构建,RankSVM模型训练 |
| 广告投放优化 | Kafka收集曝光数据,Spark MLlib训练CTR预估模型 |
金融领域
- 风险控制:HBase存储客户征信数据,Spark图计算检测欺诈团伙
- 实时交易监控:Flink处理交易流水,规则引擎实时拦截异常交易
- 监管合规:分布式文件系统长期保存交易记录,满足5年审计要求
- 量化投资:Spark处理历史行情数据,回测策略执行效率提升50倍
物联网场景
- 设备遥测数据:InfluxDB时序数据库存储传感器数据,Grafana可视化
- 预测性维护:Flink窗口计算设备振动频谱,提前发现故障隐患
- 边缘计算:AWS Greengrass本地预处理数据,仅传输关键信息至云端
- 车联网分析:Spark处理OBD数据,优化路径规划与油耗分析
人工智能领域
- 模型训练:Horovod分布式框架加速TensorFlow/PyTorch训练
- 特征工程:Spark处理原始数据,生成万亿级特征向量
- 推理加速:TensorRT分布式部署,千台GPU集群实现秒级响应
- 数据标注:众包平台结合分布式存储,百万级样本标注效率提升
实施建议与技术选型
架构设计原则
- CAP定理权衡:根据业务需求选择CP(金融)或AP(社交)系统
- 数据分区策略:Hash分区保证负载均衡,Range分区优化范围查询
- 一致性保障:2PC协议保证事务原子性,Paxos算法实现元数据强一致
- 监控体系:Prometheus采集指标,Ganglia可视化集群健康状况
主流技术栈对比
| 组件 | Hadoop生态 | Spark生态 | Flink生态 | Greenplum |
|---|---|---|---|---|
| 核心计算引擎 | MapReduce | Spark Core | Flink | MPP架构 |
| 最佳适用场景 | ETL/批处理 | 交互式分析 | 低延迟流处理 | OLAP分析 |
| 状态管理 | HDFS持久化 | Tachyon内存 | Checkpoint | 无状态 |
| 开发语言 | Java/Python | Python/Scala | Java/Scala | SQL |
| 典型延迟 | 分钟级 | 亚秒级 | 毫秒级 | 亚秒级 |
成本优化策略
- 存储层:Erasure Code编码替代3副本,存储成本降低40%
- 计算层:Spot Instance+作业排队机制节省30%云资源费用
- 网络层:RDMA远程直接内存访问减少TCP传输开销
- 生命周期管理:自动删除30天前的临时数据,冷热分层存储
FAQs常见问题解答
Q1:分布式系统与传统数据库的主要区别是什么?
A1:传统数据库(如Oracle/MySQL)适用于ACID事务型场景,提供强一致性但扩展性受限,分布式系统(如HBase/Cassandra)通过数据分片和最终一致性机制,牺牲部分实时一致性换取水平扩展能力,适合海量非结构化数据处理,关键差异包括:
- 扩展方式:纵向升级 vs 横向扩展
- 数据模型:关系表 vs NoSQL/NewSQL
- 一致性:强一致性 vs 最终一致性
- 成本结构:软件授权费用 vs 开源+硬件成本
Q2:如何选择适合的分布式处理框架?
A2:需根据业务特征进行多维度评估:
- 数据量级:GB级可选用单机版Spark,TB级以上必须分布式架构
- 延迟要求:实时场景选Flink/Kafka Streams,离线分析用Spark/Hadoop
- 计算类型:
- 批量处理:MapReduce/Spark
- 流处理:Flink/Structured Streaming
- 图计算:GraphX/JanusGraph
- 生态兼容性:已有Hadoop集群优先Spark,云原生环境考虑Serverless架构(如AWS Glue)
- 运维复杂度:容器化部署(Kubernetes)可降低管理成本40%以上