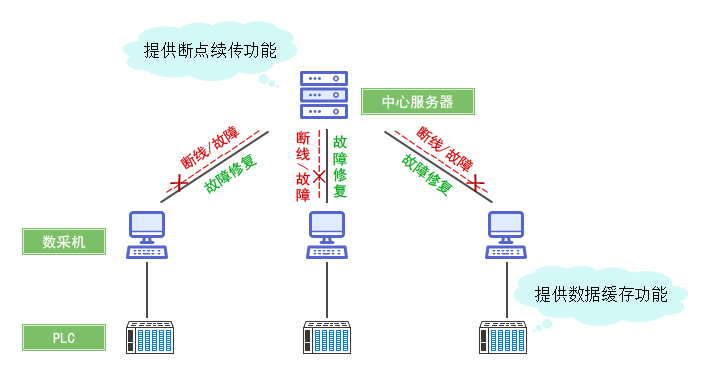
上一篇
分布式数据库能干啥
分布式数据库能实现数据分片存储、高可用容灾、弹性扩展及跨地域协同,可支撑海量数据处理、高并发访问、故障自动切换,适用于大型互联网服务、金融交易及全球化业务场景,有效提升
分布式数据库的核心能力与应用场景解析
分布式数据库是一种通过将数据分散存储在多个节点上、结合分布式计算技术实现高效管理的数据库系统,相较于传统集中式数据库,其核心优势在于横向扩展能力、高可用性和地理分布适应性,能够解决大规模数据存储、高并发访问、跨区域部署等复杂场景下的需求,以下从技术特性、应用场景、实现原理等维度详细分析分布式数据库的功能与价值。

分布式数据库的核心能力
| 能力维度 | 具体表现 |
|---|---|
| 横向扩展 | 通过增加节点实现存储与计算能力的线性扩展,突破单机性能瓶颈。 |
| %ignore_a_3% | 数据多副本冗余、自动故障转移,保障服务连续性(通常可达99.99%以上SLA)。 |
| 容错性 | 节点故障时自动切换,数据通过校验和修复机制保证一致性。 |
| 地理分布支持 | 数据可部署在多个数据中心,满足低延迟访问或跨区域灾备需求。 |
| 弹性伸缩 | 根据业务负载动态调整资源,按需付费(如云原生数据库)。 |
| 大规模数据处理 | 支持PB级数据存储与秒级查询响应,适用于海量数据分析场景。 |
分布式数据库的典型应用场景
互联网企业核心业务系统
- 场景需求:高并发用户访问(如电商瞬秒、社交平台)、海量数据实时处理。
- 解决方案:
- 分库分表:将用户、订单等数据按规则拆分到不同节点,避免单库性能瓶颈。
- 读写分离:主库负责写入,从库分担读请求,提升吞吐量。
- 案例:淘宝、抖音等平台通过分布式数据库支撑亿级用户并发。
金融行业交易与风控
- 场景需求:高频交易、实时风控、数据安全与合规。
- 解决方案:
- 强一致性保障:通过Paxos/Raft协议实现分布式事务,确保交易数据准确。
- 多活架构:两地三中心部署,满足金融级灾备要求。
- 案例:银行核心账务系统、证券交易平台。
物联网(IoT)数据管理
- 场景需求:设备数据采集、实时监控、海量时序数据存储。
- 解决方案:
- 时间序列分片:按设备ID或时间窗口划分数据,优化查询效率。
- 边缘计算集成:在设备端预处理数据,减少中心节点压力。
- 案例:智慧城市传感器网络、工业设备监控平台。
游戏行业全球化部署
- 场景需求:低延迟访问、全球玩家数据互通、弹性应对流量高峰。
- 解决方案:
- 地理分区部署:玩家数据按区域存储,就近访问(如AWS DynamoDB Global Table)。
- 热更新与滚服:通过分布式架构快速扩容或合并服务器。
- 案例:王者荣耀、原神等游戏的全球服架构。
电商平台大促活动
- 场景需求:瞬秒、优惠券发放、订单洪峰处理。
- 解决方案:
- 分片键优化:按商品ID或用户ID分片,避免热点数据集中。
- 缓存与数据库协同:Redis缓存热点数据,分布式数据库处理持久化。
- 案例:天猫双11、拼多多百亿补贴活动。
物流与供应链管理
- 场景需求:订单轨迹追踪、仓储数据实时同步、多角色权限隔离。
- 解决方案:
- 事件驱动架构:通过Kafka等消息队列同步物流状态变更。
- 多租户隔离:不同企业数据独立存储,兼顾共享协作。
- 案例:菜鸟网络、顺丰快递的订单管理系统。
政府与公共服务
- 场景需求:人口信息管理、社保医保数据互通、高并发政务服务。
- 解决方案:
- 数据联邦与隐私保护:跨部门数据加密共享,符合GDPR等法规。
- 读写分离与负载均衡:应对突发的政务办理高峰(如公积金查询)。
- 案例:各省市“一网通办”平台。
分布式数据库的关键技术实现
数据分片(Sharding)策略
| 分片方式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 哈希分片 | 均匀分布数据,避免热点 | 简单高效 | 范围查询性能差 |
| 范围分片 | 按时间、ID区间划分(如订单月份) | 范围查询友好 | 易产生热点数据 |
| 混合分片 | 结合哈希与范围(如先哈希后排序) | 平衡查询与负载 | 实现复杂度高 |
一致性模型选择
- 强一致性:通过2PC、TCC等协议保证事务原子性(如金融交易)。
- 最终一致性:允许短暂数据不一致,适用于高并发场景(如社交媒体点赞)。
- 可调一致性:根据业务需求动态选择(如阿里云PolarDB)。
分布式事务处理
- 2PC协议:经典分布式事务方案,但存在性能瓶颈。
- TCC(Try-Confirm-Cancel):补偿机制,适合高并发场景。
- Base理论:牺牲强一致性换取可用性(如电商库存扣减)。
全局索引与查询优化
- 二级索引:在分片数据上建立全局索引,提升跨分片查询效率。
- 路由优化:通过DNS解析或代理层智能路由请求到目标分片。
- 向量化执行:批量处理查询请求,减少网络交互开销。
分布式数据库的局限性与挑战
- 复杂度高:架构设计、运维调优需要专业人才。
- 成本较高:硬件资源、网络带宽、软件授权等投入较大。
- 数据一致性权衡:强一致性可能影响性能,需根据场景取舍。
- 生态依赖:部分分布式数据库与现有工具链(如BI工具)兼容性不足。
FAQs
Q1:如何判断业务是否需要分布式数据库?
- 关键指标:
- 单日数据量超过百万级,或峰值QPS超1万。
- 业务需7×24小时高可用,且无法接受长时间停机。
- 用户或数据分布在多个地理区域。
- 传统数据库出现性能瓶颈(如慢查询、连接数超限)。
Q2:分布式数据库和传统数据库的主要区别是什么?
- 扩展性:分布式可水平扩展,传统数据库依赖垂直升级。
- 部署模式:分布式支持多中心、云原生,传统数据库多为单节点。
- 一致性模型:分布式提供多种可选级别,传统数据库默认强一致。
- 运维复杂度:分布式需管理集群、分片规则,传统数据库更轻量。
通过上述分析可见,分布式数据库的核心价值在于解决大规模、高并发、高可用场景下的数据管理难题,但其成功应用需结合业务特点进行架构设计与