上一篇
hdfs文件存储在哪里
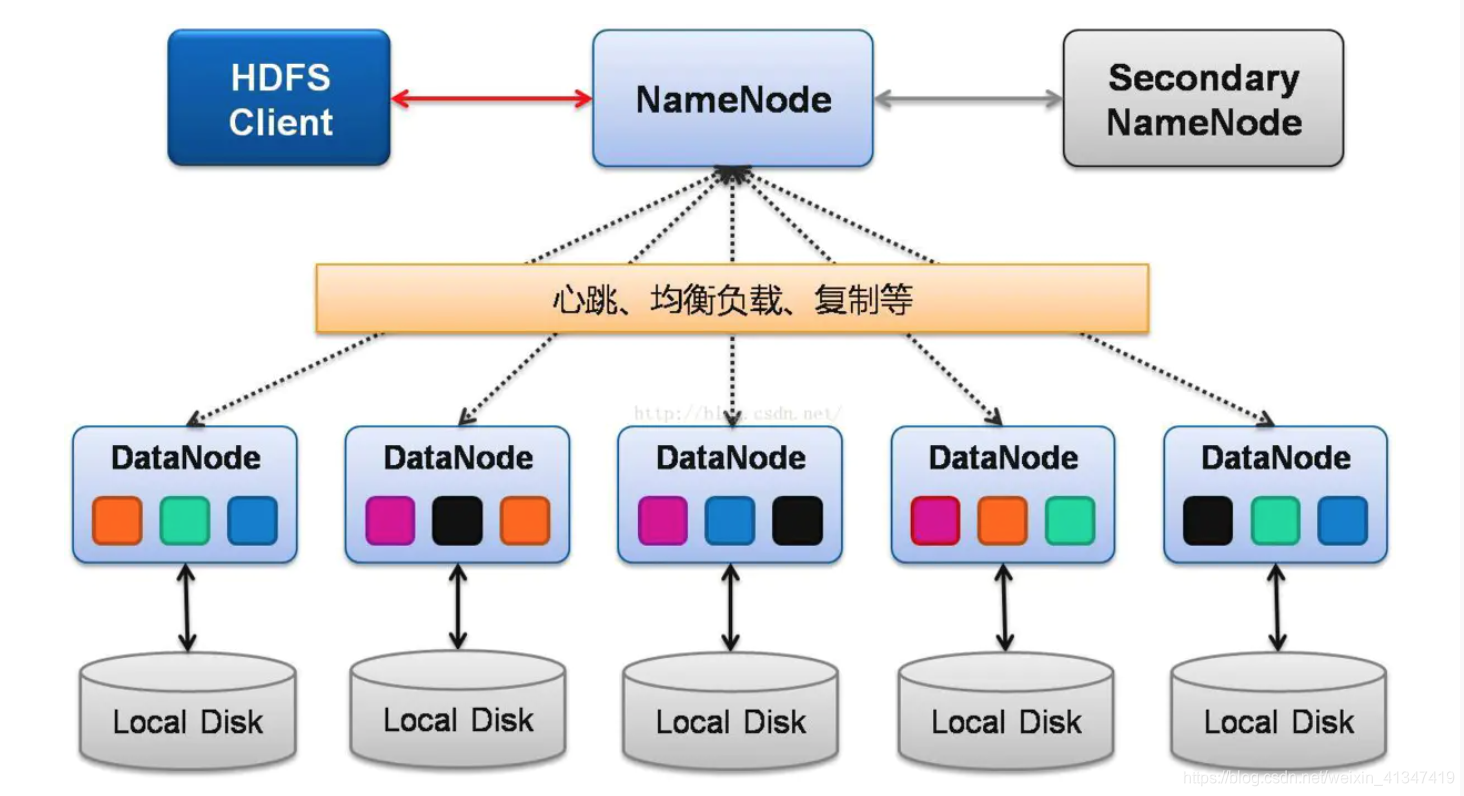
HDFS文件以数据块形式存储在集群的DataNode节点本地文件系统中,默认路径为/dfs/data,由NameNode管理元数据, DataNode负责实际物理
HDFS(Hadoop Distributed File System)作为大数据存储的核心组件,其文件存储机制与传统文件系统存在显著差异,以下从存储架构、数据组织形式、物理存储路径等多个维度详细解析HDFS文件的具体存储位置。
HDFS存储架构与核心组件
| 组件 | 功能定位 |
|---|---|
| NameNode | 元数据管理节点,记录文件目录结构、Block位置映射、权限等信息 |
| DataNode | 数据存储节点,负责实际数据块的存储和读写操作 |
| SecondaryNameNode | 辅助元数据节点,定期合并NameNode日志,非实时存储 |
关键特性:
- 分布式存储:文件被切割为固定大小(默认128MB)的Block,分散存储在不同DataNode
- 冗余备份:每个Block默认存储3个副本,分布在不同机架/节点
- 松耦合架构:客户端直接与DataNode交互,NameNode仅管理元数据
HDFS文件存储的三层逻辑结构
| 层级 | 示例路径 | |
|---|---|---|
| 文件系统层 | /user/hadoop/input/data.txt | 用户可见的完整文件路径,由NameNode维护目录结构和文件元数据 |
| Block层 | BlockID: BP-123456789-101112 | 实际物理存储单元,每个Block包含多个数据副本 |
| 数据块层 | datanode1:5001/current/BP-123/blk_1001 | DataNode本地存储路径,包含数据文件和元数据文件 |
存储流程示例:

- 用户上传1GB文件至HDFS
- NameNode将其切割为8个128MB Block(不足块按实际大小)
- 每个Block分配3个存储节点(如DataNode1、DataNode2、DataNode3)
- 客户端直接与DataNode建立数据流连接完成写入
物理存储路径详解
HDFS在Linux系统上的物理存储路径通常遵循以下规范:
默认存储目录
/var/hdfs/data/df/dn # DataNode默认存储根目录
目录结构说明
/current/ # 当前活跃的Block存储目录
BP-123456/ # Block Pool标识(对应文件系统命名空间)
blk_1001 # Block ID,存储实际数据
blk_1001.meta # 元数据文件(记录Block属性、校验和等)
/tmp/ # 临时目录,存储正在写入的Block
/finalized/ # 已完成写入的Block归档目录
/in_use.lock # 并发访问锁文件Block存储文件特征
| 文件类型 | 后缀 | 作用 |
|---|---|---|
| 数据文件 | .blk | 存储实际二进制数据(无文件系统格式,纯数据块) |
| 元数据文件 | .meta | 记录Block长度、校验和、时间戳等元信息 |
| 临时文件 | .tmp | 写入过程中的中间状态文件 |
| 校验文件 | .cksum | 存储CRC校验值(已弃用,新版HDFS使用.meta替代) |
数据寻址与访问机制
HDFS采用两级寻址机制实现高效访问:
- 元数据寻址:客户端首次访问文件时查询NameNode获取Block位置列表
- 数据直连:后续数据操作直接与对应DataNode建立连接,绕过NameNode
典型命令示例:
# 查看文件Block分布 hadoop fs -stat %o /user/hadoop/input/data.txt # 输出示例:128MB block(s), 3 replicas, [DN1,DN2,DN3] # 查看集群存储报告 hdfs dfsadmin -report # 显示各DataNode存储容量、已用空间、剩余空间等
存储特性对比分析
| 特性 | HDFS | 本地文件系统(如EXT4) |
|---|---|---|
| 存储单元 | 固定大小Block(128MB默认) | 可变大小簇(4KB-16TB) |
| 数据冗余 | 多副本机制(默认3副本) | RAID阵列或软件RAID |
| 元数据管理 | 集中式NameNode | 文件系统超级块(分散存储) |
| 扩展方式 | 横向扩展DataNode | 纵向扩展单卷容量 |
| 故障恢复 | 自动副本重建 | 依赖备份或RAID重建 |
特殊场景存储处理
- 大文件优化:超过2GB的文件会被切割为多个Block,但保持单一文件逻辑视图
- 小文件合并:启用Hadoop Archive(HAR)将小文件打包为Block级别存储
- 异构存储支持:通过HDFS-CACHE机制将热数据缓存到SSD,冷数据保留在机械硬盘
- 跨集群传输:使用DistCp工具实现Block级并行复制,保持存储效率
FAQs
Q1:删除HDFS文件后,对应的Block是否立即从DataNode清除?
A1:不会立即清除,NameNode标记Block为”待删除”状态,实际物理删除需等待:
- 所有客户端关闭对该文件的访问
- DataNode周期性扫描(默认3天)后执行物理删除
- 可通过
hdfs dfsadmin -safemode进入安全模式强制清理
Q2:如何查看特定文件的所有Block存储位置?
A2:使用以下命令组合:
# 获取文件Block信息 hadoop fs -stat %o /path/to/file # 示例输出:128MB block(s), 3 replicas, [DN1:50010,DN2:50010,DN3:50010] # 查看详细Block列表 hdfs dfsadmin -report -i /path/to/file # 显示每个Block的ID及所在