上一篇
hive数据仓库资料
Hive是基于Hadoop的分布式数据仓库工具,支持SQL查询,擅长处理PB级数据,适用于数据分析与挖掘,助力企业
Hive数据仓库核心技术解析与实践指南
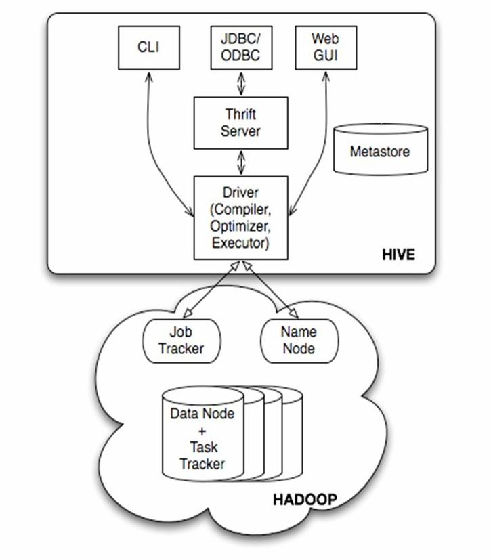
Hive基础架构与核心组件
Hive是基于Hadoop的数据仓库工具,通过类SQL语法实现对大规模数据的计算,其架构包含以下核心模块:
| 组件 | 功能描述 |
|---|---|
| MetaStore | 元数据管理系统,存储表结构、分区信息 |
| Driver | 负责编译SQL为MapReduce/Tez任务 |
| Execution Engine | 任务执行引擎(MR/Tez/Spark) |
| HiveServer2 | 提供JDBC/ODBC接口,支持多客户端并发访问 |
数据存储特性:
- 数据以HDFS为底层存储,支持Text/ORC/Parquet等多种文件格式
- 默认采用分层存储结构:
database.schema路径命名规范 - 支持分区(Partition)和桶(Bucket)两种数据组织方式
Hive数据建模规范
分区表设计
- 按时间/地域/业务维度建立分区(如
dt=20230815) - 动态分区参数配置:
set hive.exec.dynamic.partition=true - 最佳实践:分区字段不超过3个,避免过深目录结构
- 按时间/地域/业务维度建立分区(如
存储格式选择
| 格式类型 | 压缩率 | 查询性能 | 适用场景 |
|———-|——–|———-|———————–|
| Text | 低 | 慢 | 临时数据/简单ETL |
| ORC | 高 | 快 | 大数据分析(列式存储)|
| Parquet | 中 | 快 | 混合型分析场景 |SerDe序列化机制

- 内置SerDe支持常见格式(如CSV、JSON)
- 自定义SerDe实现复杂数据结构解析
- 推荐使用ORC+Snappy压缩组合,平衡性能与存储成本
HiveSQL高级特性
动态分区加载
INSERT OVERWRITE TABLE target_table PARTITION(dt) SELECT col1, col2, '20230815' AS dt FROM source_table;
窗口函数应用
SELECT user_id, sum(amount) OVER (PARTITION BY user_id ORDER BY tx_time ROWS BETWEEN INTERVAL 3 PRECEDING AND CURRENT ROW) AS moving_avg FROM transaction_log;
复杂类型处理
- 数组操作:
size(array_col)获取元素个数 - Map查询:
map_col['key']获取对应值 - JSON解析:
get_json_object(json_col, '$.address.city')
- 数组操作:
性能优化策略
执行计划调优
- 开启CBO优化:
set hive.cbo.enable=true - 强制bucket join:
set hive.strict.bucketing=true - 并行执行限制:
set mapreduce.job.reduces=10
- 开启CBO优化:
数据倾斜解决方案
| 场景类型 | 解决方案 |
|———-|———————————–|
| Mapper端倾斜 | 启用hive.groupby.skewindata=true自动优化 |
| Reducer端倾斜 | 设置hive.optimize.skewjoin=true启用倾斜连接优化 |
| 数据分布不均 | 预聚合+空key过滤 |索引加速查询
- 创建Bitmap索引:
CREATE INDEX idx_user_id ON table(user_id) AS 'COMPACT' - 索引适用场景:高频过滤条件且基数较低的字段
- 创建Bitmap索引:
企业级应用场景
日志分析平台
- 原始日志存储为ORC格式,按小时分区
- 典型查询:
SELECT LOCATION, count() FROM access_log WHERE dt='20230815' GROUP BY LOCATION
用户画像系统
- 构建多维立方体模型:用户基本信息+行为特征+消费属性
- 使用Union All合并多源数据,通过View抽象业务逻辑
实时数仓集成
- Kafka→Flume实时采集→Hive Iceberg表存储
- Mercury框架实现流批一体数据处理
Hive生态工具对比
| 特性维度 | Hive | Impala | Spark SQL |
|---|---|---|---|
| 最佳适用场景 | 离线批处理 | 实时交互查询 | 混合负载处理 |
| 事务支持 | ACID事务(>2.x) | 无 | 完善事务支持 |
| 扩展性 | 依赖YARN队列 | 独立Scheduler | 弹性资源池 |
| 开发成本 | SQL兼容良好 | 专用QL语言 | 标准SQL支持 |
FAQs常见问题解答
Q1:Hive与传统关系型数据库的核心区别是什么?
A:主要差异体现在三个方面:
- 存储层:Hive基于HDFS分布式存储,传统数据库使用本地磁盘
- 计算模型:Hive采用MapReduce批量处理,传统数据库使用索引扫描
- 事务特性:Hive默认最终一致性,传统数据库支持ACID事务
适用场景上,Hive适合PB级历史数据分析,而传统数据库侧重高并发在线业务。
Q2:如何诊断并解决Hive任务执行缓慢的问题?
A:可按照以下步骤排查:
- 查看执行计划:
EXPLAIN FORMATTED检查是否全表扫描 - 检查数据分布:
ANALYZE TABLE统计分区数据量是否均衡 - 调整并行度:通过
set mapreduce.job.reduces增加Reducer数量 - 开启矢量化:
set hive.vectorized.execution.enabled=true提升CPU利用率 - 使用列式存储:将TextFile转换为ORC