上一篇
分布式存储项目cmd获lp
分布式存储项目CMD获LP投资,凭借高效、安全、可扩展技术优势,优化数据存储架构,降低运维成本,适用于云计算、大数据等场景,推动数字基建升级
分布式存储项目cmd获lp技术解析与实践探索
分布式存储技术背景与核心需求
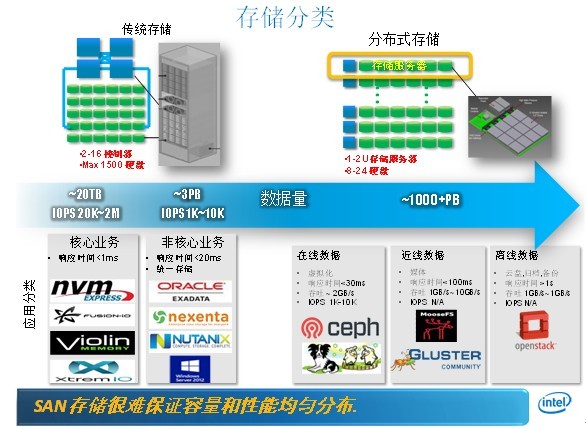
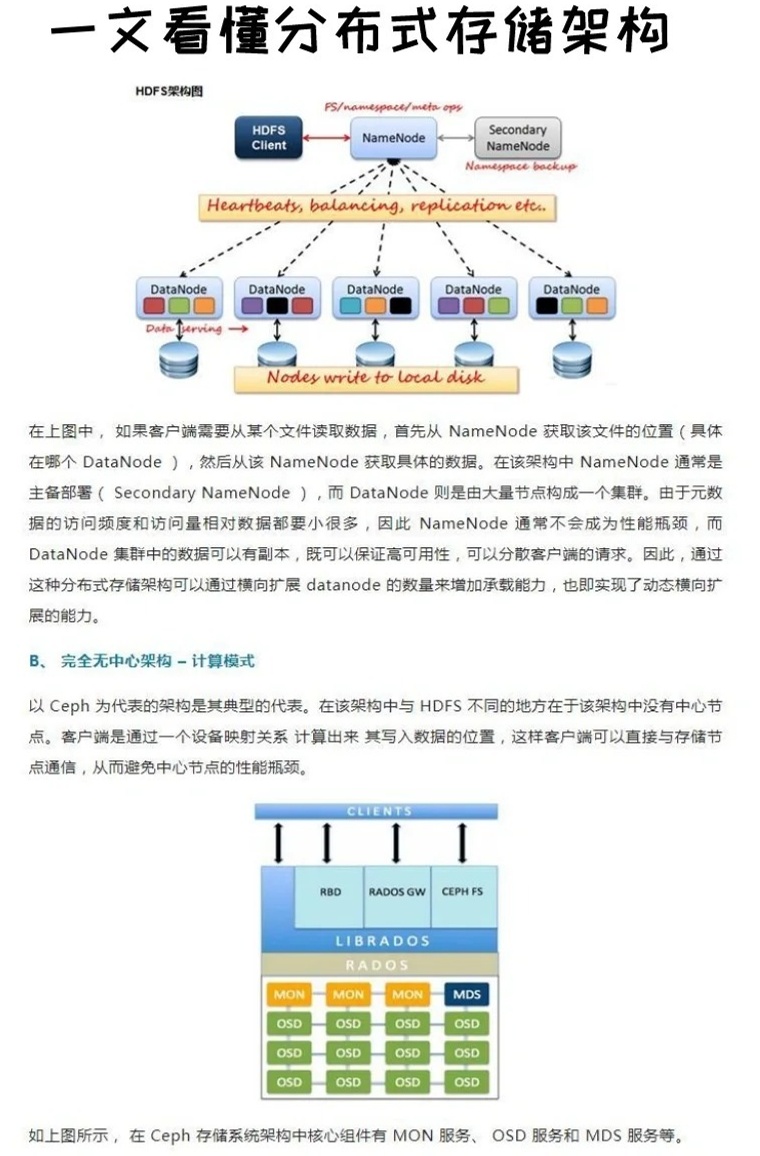
在数字化时代,数据量呈指数级增长,传统集中式存储面临容量瓶颈、单点故障、扩展成本高等问题,分布式存储通过将数据分散存储在多个节点上,结合冗余编码、一致性协议等技术,实现了高性能、高可用和弹性扩展,典型应用场景包括云存储服务(如AWS S3)、大数据分析(如Hadoop HDFS)、区块链存储等。
核心需求:
- 数据一致性:强一致性(如金融交易)或最终一致性(如日志存储)
- 容错能力:节点故障时自动恢复
- 扩展性:水平扩展无需停机
- 性能优化:低延迟与高吞吐量的平衡
- 成本控制:硬件资源利用率最大化
cmd与lp在分布式存储中的定位
在分布式存储项目中,”cmd”通常指命令行工具(Command Line Interface),用于管理集群、执行运维操作;”lp”可能指负载均衡(Load Balancing)模块或自定义协议(如存储策略),以下从技术架构角度解析两者的作用:
| 组件 | 功能定位 | 关键技术 |
|---|---|---|
| cmd | 集群管理(节点增减、配置更新) 数据操作(上传/下载/删除) 监控诊断 | RESTful API对接 参数化脚本 权限管理(RBAC模型) |
| lp | 数据分片与负载分配 网络流量调度 动态扩容策略 | 一致性哈希算法 心跳检测机制 自适应负载感知(如LVS+Keepalived) |
技术实现细节与代码示例
以基于Python的分布式存储系统为例,展示cmd与lp模块的实现逻辑:

cmd模块实现(使用Argparse库)
import argparse
import requests
def parse_args():
parser = argparse.ArgumentParser(description="Distributed Storage CLI")
subparsers = parser.add_subparsers(dest="command")
# 上传文件命令
upload_parser = subparsers.add_parser("upload", help="Upload file to storage")
upload_parser.add_argument("filepath", type=str, help="Local file path")
upload_parser.add_argument("--replicas", type=int, default=3, help="Replication factor")
# 查询节点状态命令
status_parser = subparsers.add_parser("status", help="Check cluster health")
return parser.parse_args()
def main():
args = parse_args()
if args.command == "upload":
# 调用API上传文件
response = requests.post("http://storage-api/upload", files={"file": open(args.filepath, "rb")})
print("Upload success:", response.json())
elif args.command == "status":
# 获取集群健康状态
response = requests.get("http://storage-api/health")
print(response.json())lp模块实现(一致性哈希算法)
import hashlib
from bisect import bisect_left
class ConsistentHash:
def __init__(self, nodes=None, replicas=3):
self.ring = []
self.node_map = {}
self.replicas = replicas
if nodes:
self.add_nodes(nodes)
def add_node(self, node):
for i in range(self.replicas):
key = self.hash_func(f"{node}#{i}")
self.ring.append(key)
self.node_map[key] = node
self.ring.sort()
def get_node(self, key):
hash_key = self.hash_func(key)
idx = bisect_left(self.ring, hash_key)
return self.node_map[self.ring[idx % len(self.ring)]]
@staticmethod
def hash_func(key):
return int(hashlib.md5(key.encode()).hexdigest(), 16)性能优化与容错机制
- 数据分片策略:
- 固定大小分片(如64MB/块) vs 动态分片
- 纠删码(Erasure Coding)替代副本存储,降低存储成本
- 表:不同分片策略对比
| 策略 | 存储效率 | 容错能力 | 修复成本 | 适用场景 |
|---|---|---|---|---|
| 3副本 | 33% | 高 | 低 | 对延迟敏感的业务 |
| RS纠删码 | 50% | 中 | 高 | 冷数据存档 |
| EC纠删码 | 60% | 高 | 中 | 大数据分析 |
- 容错机制:
- 心跳检测:节点失联超过阈值自动标记为失效
- 数据重建:失效节点数据从其他副本恢复
- 脑裂防护:Paxos/Raft协议确保元数据一致
实际部署案例分析
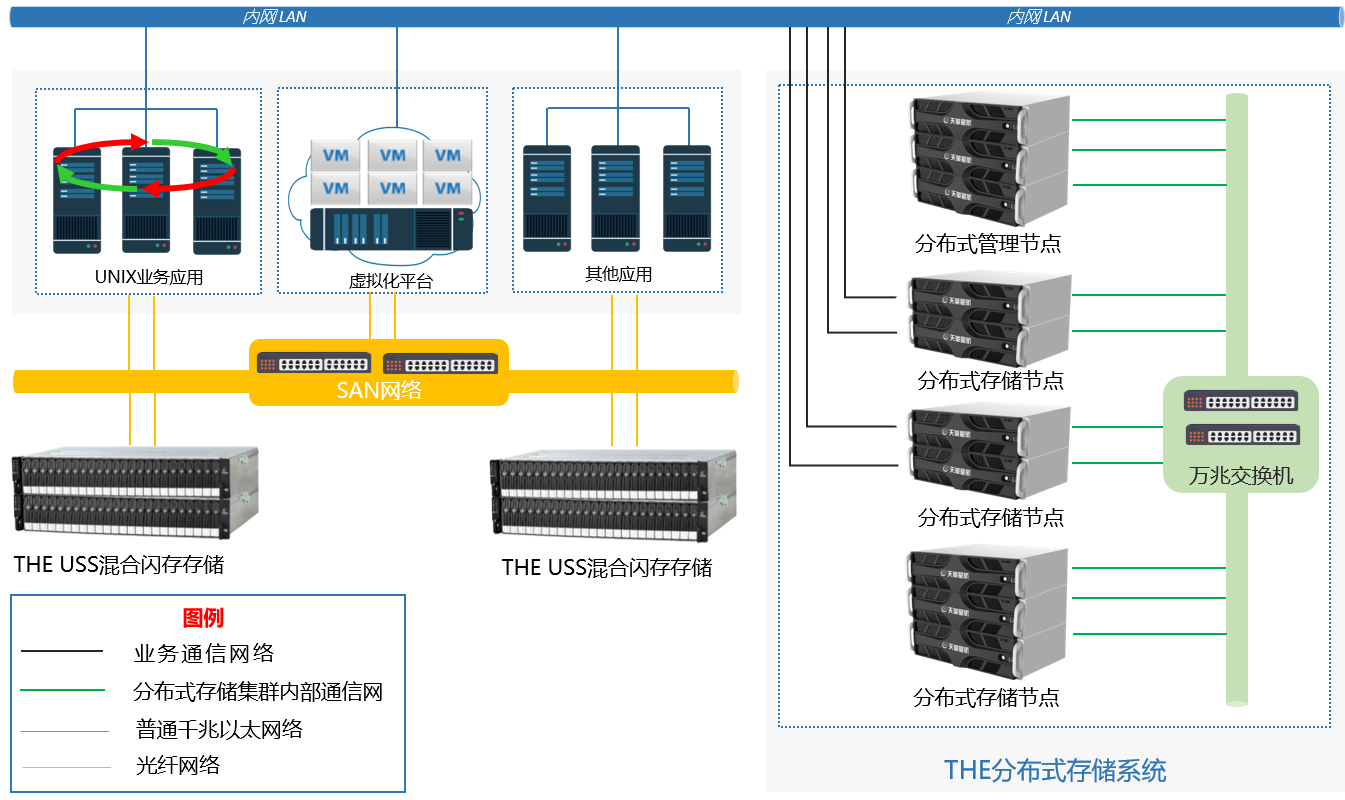
某电商平台采用自研分布式存储系统,支撑每日亿级图片存储需求:
- 架构:100个存储节点+5个元数据节点
- cmd工具:支持批量导入、权限配置、日志清理
- lp模块:基于LVS的请求分发+Consistent Hash数据路由
- 性能数据:
- 平均上传延迟:120ms(含3副本写入)
- 峰值吞吐量:80GB/s(千节点集群)
- 故障恢复时间:<30秒(单节点故障)
常见问题与解决方案
Q1:如何防止cmd操作误删数据?
- 三级确认机制:输入命令后需二次确认+验证码校验
- 操作审计日志:记录所有命令执行者与时间戳
- 回收站设计:删除操作转入隔离区,保留7天可恢复
Q2:lp模块在跨数据中心部署时如何优化?
- 数据中心优先级:根据延迟/带宽设置权重
- 数据预热:提前将高频访问数据缓存至目标节点
- 异步复制:采用Paxos协议保证跨区域一致性
FAQs:
问题1:分布式存储系统出现脑裂如何解决?
答:通过Raft协议选举主节点,结合仲裁机制(Quorum)判断多数派,自动隔离异常节点,建议部署奇数个元数据节点(如3/5/7个),避免投票僵局。
问题2:如何提升小文件存储效率?
答:1) 合并小文件为大Block(如1MB/块) 2) 使用内存缓存加速元数据访问 3) 采用对象存储扁平化目录结构(如Amazon S