上一篇
分布式存储项目有几个
分布式存储主流项目包括IPFS、Filecoin、Swarm、Storj、BigchainDB等,当前活跃项目约5-10个,覆盖数据存储、检索及激励机制
分布式存储项目详解与对比分析
分布式存储作为现代数据管理的核心基础设施,广泛应用于云计算、大数据、人工智能等领域,以下是当前主流的分布式存储项目及其技术特点分析:
主流分布式存储项目概览
| 项目名称 | 核心特点 | 适用场景 | 技术架构 | 代表企业/社区 |
|---|---|---|---|---|
| Ceph | 统一存储(块、文件、对象)、高扩展性、CRUSH算法优化数据分布 | 云存储、虚拟化、大规模数据中心 | RADOS层+上层协议(RBD/CephFS/S3) | Red Hat、IBM、阿里云等 |
| GlusterFS | 纯用户态设计、无元数据服务器、高并发支持 | 中小型企业文件共享、媒体处理 | Brick(存储节点)+ Volume(逻辑卷)+ Mount Protocol(POSIX/CIFS) | Red Hat、Google Cloud |
| MinIO | S3协议兼容、轻量级、高性能对象存储 | 云原生应用、备份归档、AI训练数据 | 基于Go语言实现,支持单/多节点部署 | Kubernetes生态、DevOps团队 |
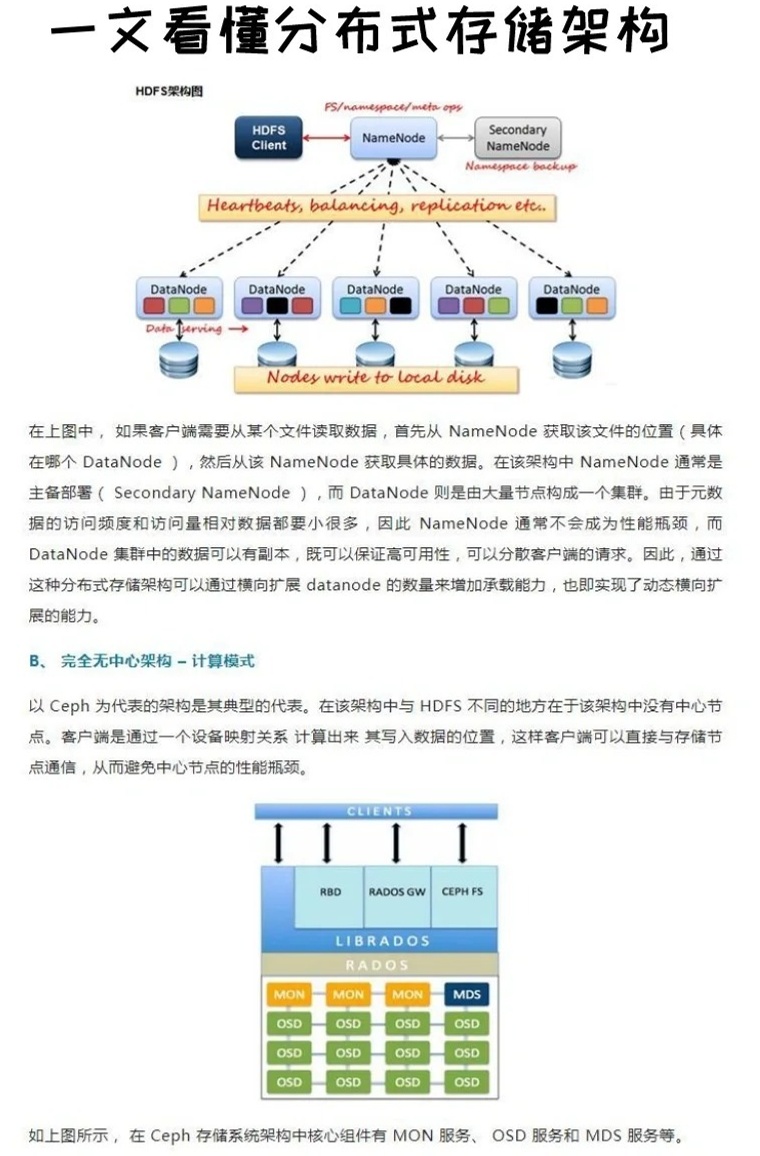
| HDFS | 块存储模型、主从架构、高容错性 | 大数据批处理(Hadoop生态) | NameNode(元数据)+ DataNode(数据块) | Apache Hadoop社区、酷盾安全 |
| BeeGFS | 并行文件系统、低延迟、高吞吐量 | 科学计算、基因测序、影视渲染 | Metadata Server + Storage Nodes + Client Library | 欧洲核子研究中心(CERN)、高校 |
| MooseFS | 高可用文件系统、支持增量复制、跨地域容灾 | 日志存储、冷数据归档 | Master(元数据)+ Chunk Servers(数据分片) | 网易严选、俄罗斯Yandex |
| SeaweedFS | 轻量级对象存储、支持纠删码、高写入性能 | 日志收集、实时数据分析 | Volume Server(数据分片)+ Master(元数据)+ Gateway(API入口) | 滴滴出行、GitHub |
| JuiceFS | 弹性文件系统、POSIX兼容、云原生设计 | 容器化应用、混合云存储 | Metadata Engine + Chunk Storage(支持对象存储/HDD/SSD) | Kubernetes社区、Rancher |
| Longhorn | 云原生分布式块存储、容器友好、动态扩展 | Kubernetes持久化存储、微服务 | Replicated 副本机制 + 调度器集成 | Kubernetes官方、Rancher |
关键技术对比分析
架构设计差异
- Ceph:通过CRUSH算法实现数据分布与负载均衡,支持三种存储接口(RBD、CephFS、S3),适合混合负载场景。
- HDFS:采用主从架构,依赖NameNode元数据管理,扩展性受限于单点瓶颈,适合批量数据处理。
- MinIO:完全兼容AWS S3协议,轻量化设计,适合云原生对象存储需求。
性能与扩展性

- BeeGFS:针对低延迟和高吞吐量优化,适用于科学计算中的并行文件访问。
- SeaweedFS:通过纠删码降低存储成本,写入性能优于传统对象存储。
- Longhorn:专为Kubernetes设计,动态扩展能力与容器生命周期深度集成。
容灾与高可用
- MooseFS:支持跨机房异步复制,适合异地灾备场景。
- Ceph:通过副本数配置和故障域隔离实现数据冗余,但复杂度较高。
- JuiceFS:依赖底层对象存储(如S3)实现数据持久化,元数据引擎可独立扩展。
生态与兼容性
- GlusterFS:原生支持POSIX和CIFS协议,易于集成传统应用。
- MinIO:与Kubernetes、Prometheus等云原生工具链无缝对接。
- HDFS:与Hadoop生态深度绑定,适合MapReduce作业。
选型建议
| 场景需求 | 推荐项目 | 理由 |
|---|---|---|
| 混合存储(块/文件/对象) | Ceph | 统一存储接口,支持多协议,生态成熟。 |
| 云原生对象存储 | MinIO | S3协议兼容,轻量级部署,适合容器化环境。 |
| 大数据批处理 | HDFS | 与Hadoop生态深度整合,适合离线数据分析。 |
| 高性能并行文件系统 | BeeGFS | 低延迟、高吞吐量,适用于科学计算和渲染场景。 |
| 冷热数据分层存储 | JuiceFS + MinIO/Ceph | JuiceFS提供弹性文件系统,后端可对接对象存储或块存储实现分层。 |
常见挑战与解决方案
元数据瓶颈
- 问题:HDFS、Ceph等依赖中心化元数据服务器,扩展性受限。
- 方案:采用分布式元数据架构(如Ceph的MON集群)或分片策略(如BeeGFS的Metadata Server集群)。
存储成本优化
- 问题:传统副本机制存储效率低(如3副本占用300%空间)。
- 方案:使用纠删码技术(如SeaweedFS、MinIO)将存储开销降至1.5倍,平衡成本与可靠性。
多云环境适配
- 问题:混合云场景下数据迁移困难。
- 方案:选择云原生项目(如JuiceFS、Longhorn),支持跨云存储后端无缝切换。
FAQs
Q1:如何根据业务需求选择分布式存储?
A1:需综合考虑以下因素:
- 数据类型:结构化数据(HDFS)、非结构化数据(MinIO)、混合负载(Ceph)。
- 性能要求:低延迟(BeeGFS)、高吞吐量(GlusterFS)、弹性扩展(JuiceFS)。
- 成本限制:纠删码(SeaweedFS)比副本机制更节省存储空间。
- 生态兼容性:云原生场景优先选择MinIO/Longhorn,大数据场景适配HDFS/Ceph。
Q2:分布式存储与集中式存储的核心区别是什么?
A2:
- 扩展性:分布式存储通过横向扩展(增加节点)提升容量和性能,集中式存储依赖硬件升级。
- 容灾能力:分布式存储通过数据冗余(副本/纠删码)实现高可用,集中式存储依赖单点备份。
- 成本:分布式存储初期部署复杂,但长期扩展成本低;集中式存储适合