上一篇
分布式存储分布式缓存
分布式存储通过多节点冗余存储数据,保障持久性与扩展性(如HDFS);分布式缓存将热点数据暂存于多节点,提升访问速度(如Redis),两者协同可优化
分布式存储与分布式缓存深度解析
分布式存储的核心概念与架构
分布式存储是将数据分散存储在多个物理节点上,通过协同工作提供高可用、高扩展的存储服务,其核心目标是解决单机存储的性能瓶颈和容量限制,同时保障数据的可靠性和持久性。
典型架构特征:
- 数据分片(Sharding):将数据拆分为多个片段,分布到不同节点
- 副本机制:每个数据片保存多个副本(如3副本),提升容错能力
- 元数据管理:通过中心化或分布式元数据服务记录数据位置
- 一致性协议:采用Paxos/Raft等算法保证多副本数据一致
主流类型对比表:
| 类型 | 代表系统 | 适用场景 | 性能特点 |
|————|————-|————————-|——————-|
| 块存储 | Ceph RBD | 虚拟机磁盘 | 低延迟,高IOPS |
| 文件存储 | GlusterFS | 共享文件系统 | 高吞吐量,支持大文件 |
| 对象存储 | MinIO | 海量非结构化数据 | 高扩展性,低成本 |
关键技术挑战:

- CAP定理权衡:在一致性、可用性、分区容忍中取舍
- 数据重建效率:节点故障时需快速恢复副本
- 负载均衡:动态调整数据分布避免热点
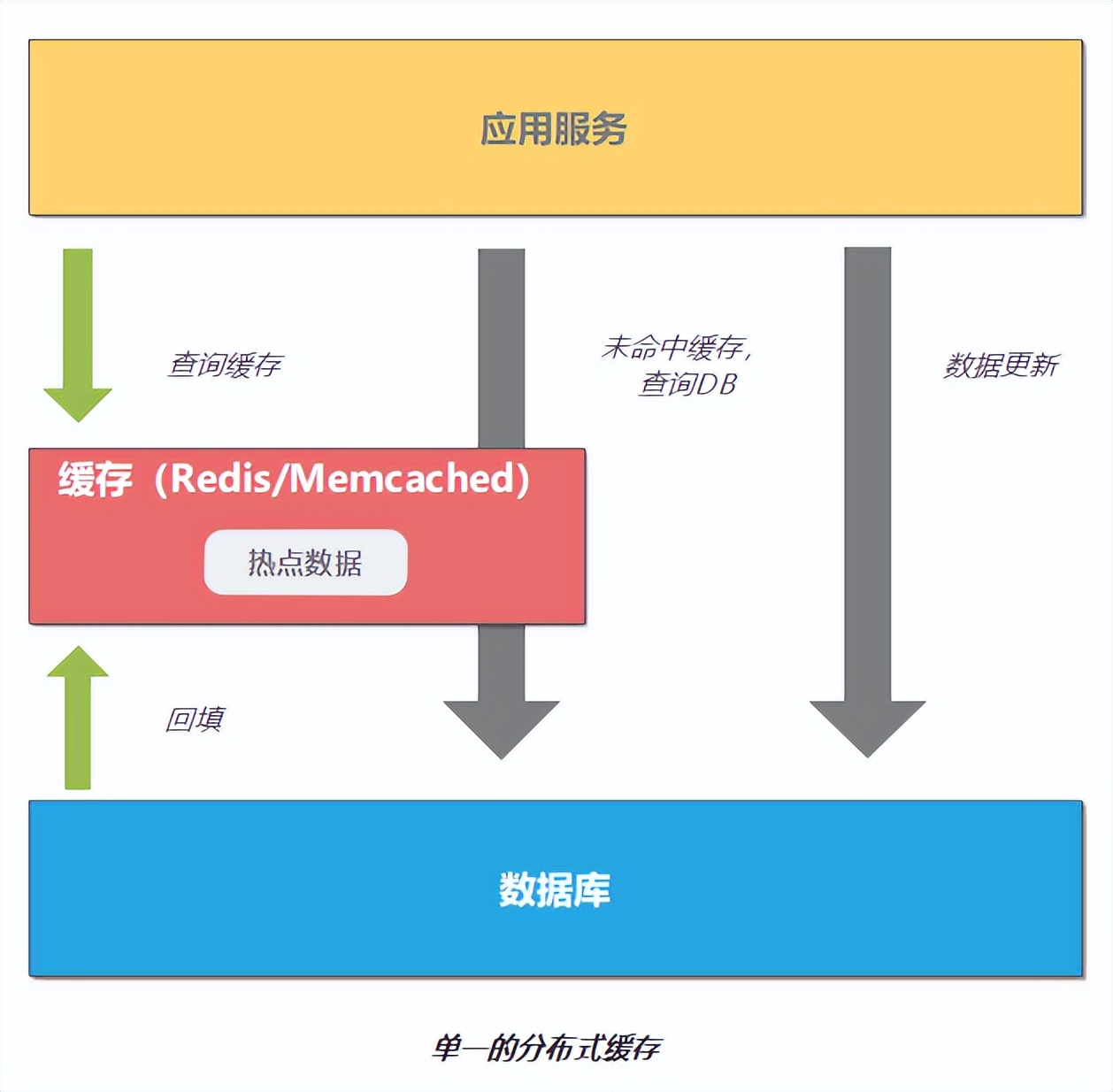
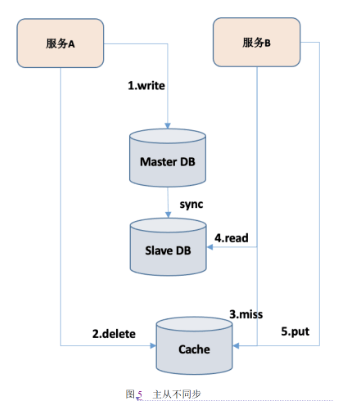
分布式缓存的实现原理
分布式缓存通过将热数据保存在内存集群中,加速数据访问速度,与存储的本质区别在于:缓存是易失性的高速层,存储是持久化的容量层。
核心组件:
- 缓存客户端:负责数据读写和缓存穿透防护
- 路由层:通过一致性哈希实现请求路由
- 缓存节点:内存数据库实例(如Redis Cluster)
- 持久化后端:可选配置用于数据持久化
典型缓存策略:
- LRU(最近最少使用)淘汰算法
- LFU(最不常用)频率优先策略
- TTL(时间戳)主动过期机制
性能优化手段:
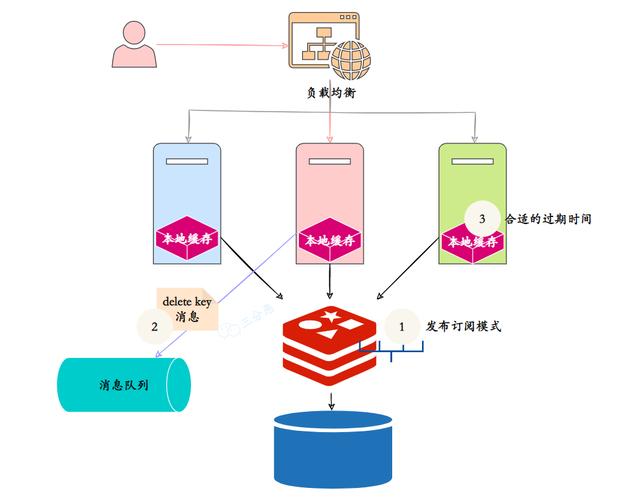
- 多级缓存架构(L1本地缓存+L2分布式缓存)
- 异步复制减少网络等待
- Pipeline批量处理请求
关键差异对比分析
| 维度 | 分布式存储 | 分布式缓存 |
|---|---|---|
| 数据持久性 | 强持久化(多副本同步写入) | 最终一致(异步复制为主) |
| 访问模式 | 读写混合,复杂事务操作 | 高并发读取,少量写操作 |
| 数据生命周期 | 长期保存(GB/TB级) | 短期留存(分钟/小时级) |
| 性能指标 | 侧重吞吐量和持久化延迟 | 极致降低读取延迟 |
| 成本模型 | 硬盘介质为主,容量成本高 | 内存介质为主,性能成本高 |
典型组合应用场景:
- 电商系统:商品详情用分布式缓存(Redis),订单数据用分布式存储(HBase)
- 视频平台:播放缓存用Memcached,视频文件存储用Ceph对象存储
- 金融系统:实时交易数据用Redis Cluster,历史账单用分布式MySQL
技术选型决策树
graph TD
A[业务需求] --> B{数据访问频率}
B -->|高(>=10k QPS)| C[选择分布式缓存]
B -->|中低频率| D[选择分布式存储]
C --> E[评估内存成本]
D --> F[评估持久化要求]
E -->|预算充足| G[Redis Cluster]
E -->|成本敏感| H[Memcached+持久化]
F -->|强一致性| I[Ceph/GlusterFS]
F -->|最终一致| J[MinIO/Cassandra]实践优化建议
- 缓存预热策略:在系统启动时预先加载热点数据
- 分级存储设计:热数据存缓存,温数据存SSD,冷数据存HDD
- 监控体系构建:
- 缓存命中率(理想>95%)
- 存储IO延迟(机械盘<5ms,SSD<0.5ms)
- 网络带宽利用率(保持<80%)
FAQs
Q1:分布式缓存和本地缓存应该如何配合使用?
A1:建议采用三级缓存架构:
- 一级缓存:应用程序本地缓存(Guava/Caffeine)
- 二级缓存:JVM外进程缓存(Redis/Memcached)
- 三级缓存:数据库查询缓存
当请求发生时,逐级查询缓存,命中则返回,未命中才访问下级存储,这种架构可减少跨进程通信开销,同时利用分布式缓存的扩展性。
Q2:如何判断应该使用分布式存储还是分布式缓存?
A2:可从三个维度评估:
- 数据持久性要求:必须长期保存选存储,允许临时丢失选缓存
- 访问频率特征:每秒万级访问选缓存,千级以下选存储
- 数据修改频率:高频更新(>10次/秒)适合存储,低频变更适合缓存
例如用户会话数据适合缓存,订单日志适合存储