上一篇
hdfs文件存储位置
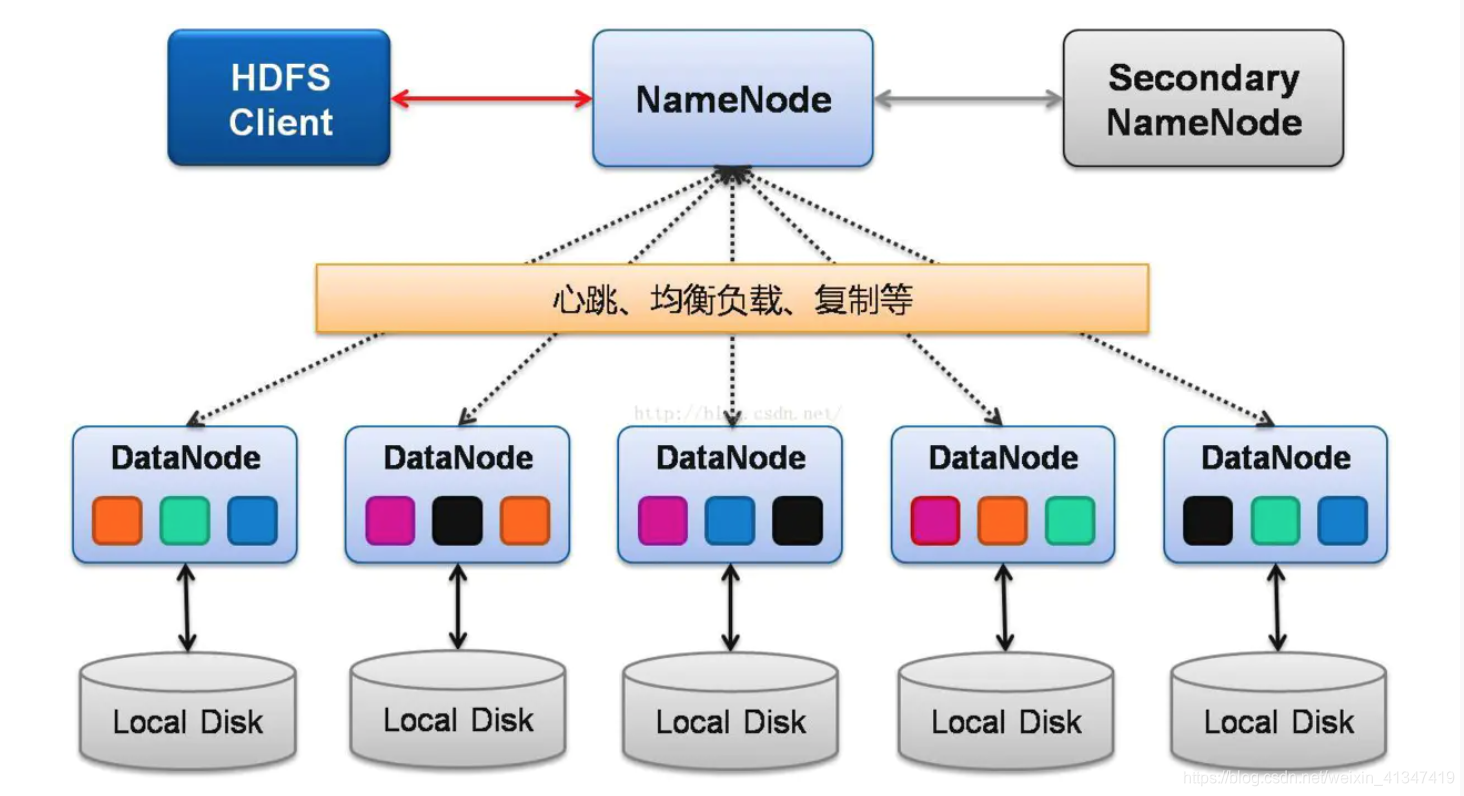
HDFS文件存储位置:数据以块形式存于DataNode,元数据由NameNode管理,存于FsImage和
HDFS(Hadoop Distributed File System)作为Hadoop生态系统的核心存储组件,其文件存储位置的设计直接影响数据的可靠性、访问效率和集群扩展性,以下从逻辑结构、物理存储路径、元数据管理、副本机制等角度详细解析HDFS文件存储位置的核心原理与实践细节。
HDFS存储架构与逻辑视图
HDFS采用主从架构,包含一个NameNode(元数据管理)和多个DataNode(实际数据存储),文件存储位置的逻辑结构如下:
| 层级 | 功能说明 |
|---|---|
| 文件系统命名空间 | NameNode维护全局命名空间,记录文件的元数据(路径、权限、块列表等) |
| 数据块(Block) | 文件被拆分为固定大小的数据块(默认128MB),每个块独立存储并复制 |
| 数据副本 | 每个数据块默认存储3个副本,分布在不同机架的DataNode上 |
逻辑存储路径示例:/user/hadoop/input/data.txt
该文件会被拆分为多个Block(如Block1、Block2),每个Block的ID由NameNode分配。
物理存储路径与DataNode本地文件系统
每个DataNode将接收到的Block存储在本地文件系统的指定目录中,路径由配置文件dfs.datanode.data.dir决定,典型存储路径结构如下:
/var/hdfs/data/dn1/current/BP-123456789-1677641191/current/finalized/subdir0/subdir1/blockId_123| 路径分段 | 含义 |
|---|---|
/var/hdfs/data/dn1 | DataNode本地存储根目录(由dfs.datanode.data.dir指定) |
BP-123456789-1677641191 | Block Pool ID,标识NameNode的存储池(集群启动时生成) |
current | 当前正在使用的Block Pool目录 |
finalized | 已完全写入的Block存储目录(不可修改) |
subdir0/subdir1 | 二级子目录,用于分散存储负载(按Block ID哈希分配) |
blockId_123 | 实际Block文件(无扩展名),存储原始数据 |
关键特性:

- 数据局部性:Block存储位置由DataNode网络拓扑决定,优先选择同机架或低延迟节点。
- 副本隔离:同一Block的多个副本不会存储在同一DataNode的相同物理目录中。
- 存储目录动态分配:通过
subdir子目录分散大文件的Block,避免单个目录过热。
通过命令行查看文件存储位置
HDFS提供多种工具查询文件物理存储位置:
hadoop fsck命令
hadoop fsck /user/hadoop/input/data.txt -files -blocks -locations
输出示例:
/user/hadoop/input/data.txt 1 block(s): OK
0. BP-123456789-1677641191_block_123_1025 3 replicas
/var/hdfs/data/dn1/current/BP-123456789-1677641191/current/finalized/subdir0/subdir1/block_123
/var/hdfs/data/dn2/current/BP-123456789-1677641191/current/finalized/subdir0/subdir2/block_123
/var/hdfs/data/dn3/current/BP-123456789-1677641191/current/finalized/subdir0/subdir3/block_123Web UI查看
通过NameNode的Web界面(默认端口50070),在Utilities->Browse the file system中点击文件,可查看Block分布及DataNode地址。
副本存储策略与故障恢复
HDFS通过副本机制保证数据可靠性,存储位置遵循以下规则:
| 策略 | 说明 |
|---|---|
| 机架感知 | 副本优先分布在不同机架,避免单机房故障导致数据不可用 |
| 节点负载均衡 | 新写入的Block优先存储在磁盘利用率较低的DataNode上 |
| 副本重建 | 当DataNode故障时,NameNode会自动在其他健康节点创建副本 |
故障恢复场景:
- 如果某个Block的副本数低于设定值(如3→2),NameNode会触发副本重建。
- 存储路径变更:当DataNode重新加入集群时,其存储目录需与NameNode的元数据保持一致。
常见问题与优化建议
问题1:如何更改DataNode的存储目录?
解答:
修改hdfs-site.xml中的dfs.datanode.data.dir参数,
<property> <name>dfs.datanode.data.dir</name> <value>/new/path/hdfs/data</value> </property>
重启DataNode后,新写入的Block将存储在新路径,但原有数据仍需手动迁移。
问题2:如何快速定位大文件的Block分布?
解答:
使用hadoop fsck命令结合-blocks参数,或通过NameNode Web UI的Datanodes页面查看各节点存储的Block数量。
归纳与最佳实践
HDFS文件存储位置的设计核心在于平衡数据可靠性与读写性能,实际部署中需注意:
- 合理规划Block大小:根据文件特性调整
dfs.blocksize(默认128MB)。 - 存储目录冗余:配置多目录存储(如
dfs.datanode.data.dir=/d1,/d2)以提升写入吞吐量。 - 监控存储均衡:通过
hdfs dfsadmin -report命令检查DataNode存储利用率,避免热点节点。
通过以上机制,HDFS实现了对海量数据的高效管理和可靠存储,成为