上一篇
hive数据仓库主键
Hive数据仓库无原生主键,需通过预处理(如UUID)或唯一约束模拟,利用分区、桶优化查询,高版本支持ACID事务,但主键约束
Hive数据仓库主键机制解析与实践方案
Hive作为大数据领域常用的数据仓库工具,其架构设计与传统关系型数据库存在本质差异,在数据唯一性保障机制方面,Hive并未直接提供类似MySQL、Oracle等数据库的主键约束功能,本文将深入分析Hive的数据存储特性,探讨主键概念的适用性,并提供多种数据唯一性保障方案。
Hive架构特性与主键限制
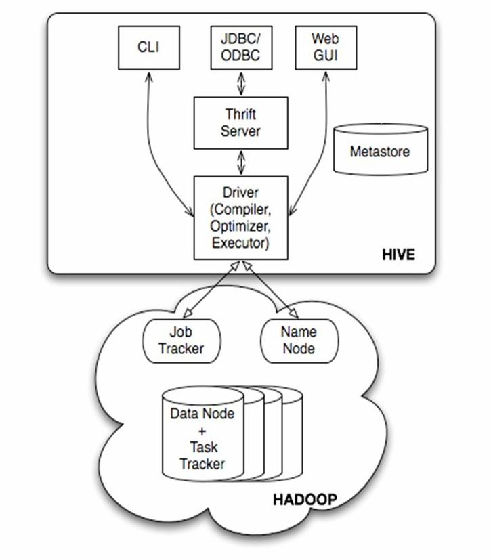
Hive基于Hadoop分布式文件系统(HDFS)构建,采用列式存储和分区管理机制,其核心特点决定了主键机制的缺失:
- 无事务支持:传统主键依赖ACID事务保证数据一致性
- 批量处理模式:数据写入采用批量导入方式
- 分布式存储:数据分块存储在不同节点
- Schema-on-read:数据写入时不强制校验
主键概念在Hive中的适用性分析
| 对比维度 | 传统数据库 | Hive数据仓库 |
|—————-|————————|—————————|
| 数据存储 | 行式存储,支持索引 | 列式存储,无原生索引 |
| 事务支持 | 完整ACID事务 | 默认无事务(3.0+支持有限) |
| 数据更新 | 原地更新 | 写时复制,增量写入 |
| 唯一性保障 | 主键/唯一索引约束 | 应用层控制 |
| 并发控制 | 锁机制 | 最终一致性 |
Hive数据唯一性保障方案
预处理阶段去重

- 在数据加载前通过Spark/MapReduce进行清洗
- 示例:使用distinct或group by消除重复记录
INSERT OVERWRITE TABLE target_table SELECT FROM source_table GROUP BY column1, column2;
复合键设计策略
- 组合多个字段形成逻辑主键
- 典型组合:业务ID+时间戳+版本号
- 示例表结构:
CREATE TABLE orders ( order_id BIGINT, order_time TIMESTAMP, version INT, ... -其他业务字段 ) PARTITIONED BY (dt STRING) CLUSTERED BY (order_id) INTO 10 BUCKETS;
分区+桶策略优化
- 通过分区隔离+哈希分桶实现物理分布
- 示例:按日期分区+用户ID哈希分桶
CREATE TABLE user_logs ( user_id BIGINT, log_time TIMESTAMP, ... -其他字段 ) PARTITIONED BY (date STRING) CLUSTERED BY (user_id) INTO 20 BUCKETS;
应用层校验机制
- 在数据写入前增加校验逻辑
- 常见实现方式:
- Spark DataFrame API进行去重
- 自定义UDF函数校验唯一性
- Kafka流处理时过滤重复消息
外部索引服务(高级方案)
- 集成Elasticsearch建立二级索引
- 使用HBase作为辅助存储引擎
- 示例架构:
Hive(事实表) ↔ HBase(维度索引) ↔ ES(全文检索)
企业级实践建议
数据建模原则
- 优先使用业务自然键(如订单号、身份证号)
- 组合键长度控制在15-32字节范围内
- 避免频繁变更的字段作为键值
性能优化策略
- 合理设置桶数量(通常为集群节点数×1.5倍)
- 分区字段选择高基数列(如日期、地区)
- 定期维护ORC文件(合并小文件)
数据治理措施
- 建立数据质量校验流程
- 实施数据版本控制机制
- 配置数据审计日志
典型应用场景对比
| 场景类型 | 推荐方案 | 注意事项 |
|—————-|—————————–|——————————-|
| 实时数据湖 | Kafka+Spark Streaming预处理 | 需配置水印机制防止重复 |
| 离线数仓 | Sqoop+MR去重导入 | 注意MapReduce任务内存配置 |
| 维度数据管理 | HBase+Phoenix二级索引 | 需平衡查询性能与存储成本 |
| 日志数据分析 | Elasticsearch+Logstash | 注意索引模板设计 |
FAQs:
Q1:Hive是否支持外键约束?
A1:Hive不直接支持外键约束,建议通过以下方式保证数据关联性:
- 在ETL流程中进行数据校验
- 使用Hive视图进行关联验证
- 借助第三方工具(如Apache Atlas)进行元数据管理
Q2:如何检测Hive表中的重复数据?
A2:可通过以下方法识别重复记录:
- 使用COUNT(DISTINCT)统计唯一值数量
SELECT COUNT(DISTINCT order_id) FROM orders;
- 自连接查询查找重复项
SELECT a. FROM target_table a JOIN target_table b ON a.primary_key = b.primary_key AND a.row_id < b.row_id;
- 利用窗口函数标记重复记录
SELECT , COUNT() OVER(PARTITION BY primary_key) as cnt FROM target_table HAVING cnt > 1;