上一篇
分布式数据库与云数据库
分布式数据库侧重数据分片与节点协同,云数据库依托 云计算提供弹性服务,二者在架构与部署模式上
分布式数据库与云数据库深度解析
核心概念辨析
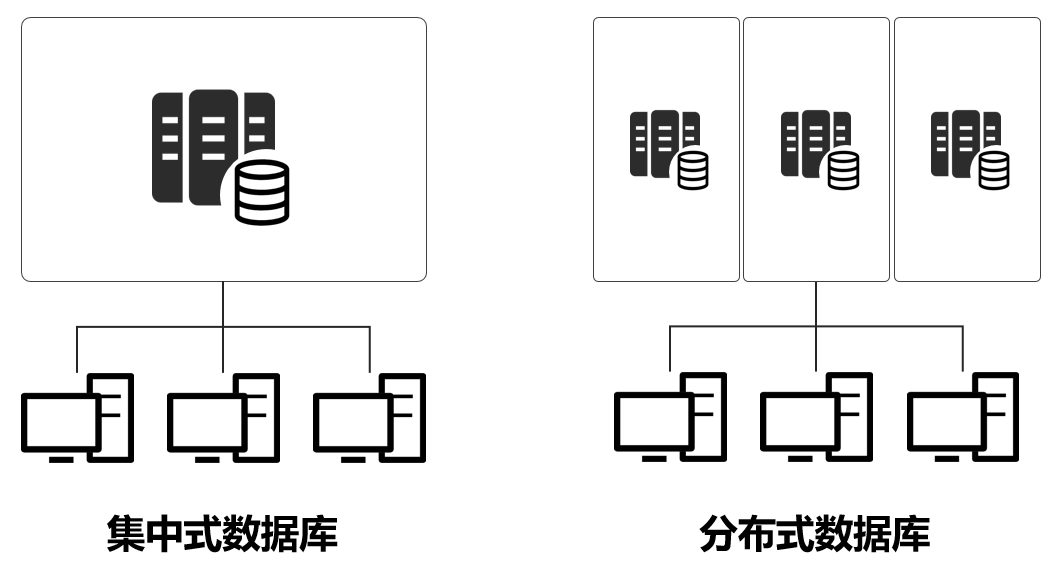
分布式数据库是一种通过数据分片(Sharding)、副本复制(Replication)等技术将数据分布存储在多个物理节点上的数据库系统,其核心目标是解决单机数据库的性能瓶颈、容量限制和单点故障问题,典型特征包括:
- 数据分布性:数据按规则拆分到不同节点
- 水平扩展能力:通过增加节点提升处理能力
- 容错机制:节点故障时自动切换
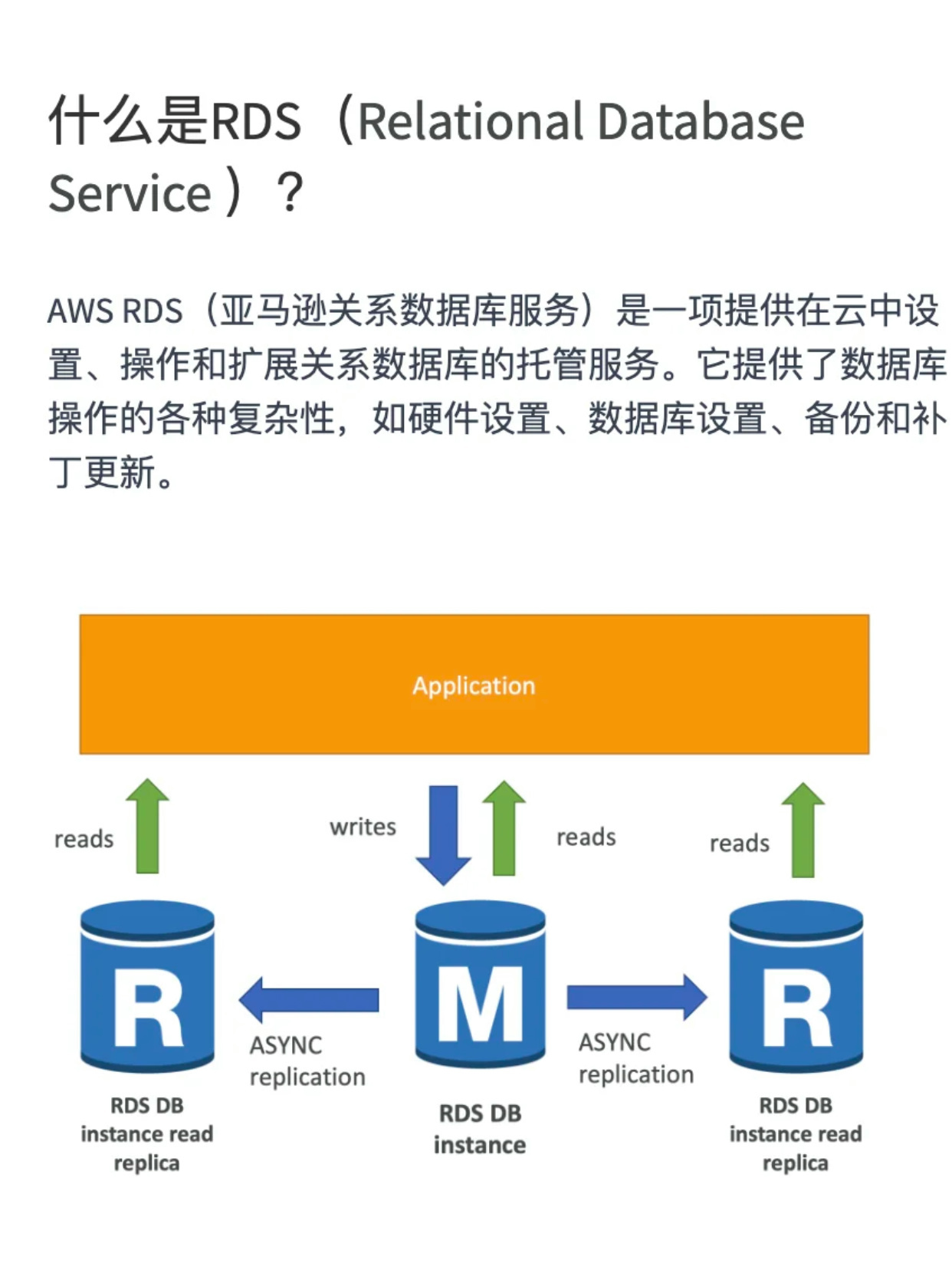
云数据库则是云计算时代的数据库服务形态,指部署在云端基础设施(IaaS层)或直接以服务形式(DBaaS)提供的数据库产品,其本质特征包括:
- 服务化交付:开箱即用,按需申请
- 弹性伸缩:计算/存储资源动态调整
- 计费模式革新:按量付费/包年包月
| 特性维度 | 分布式数据库 | 云数据库 |
|---|---|---|
| 部署模式 | 自主搭建集群 | 云端SaaS/PaaS服务 |
| 运维责任 | 完全自主管理 | 厂商承担基础运维 |
| 扩展方式 | 手动添加节点 | 自动/手动弹性扩展 |
| 成本结构 | 硬件采购+持续运维投入 | 按需订阅制 |
| 典型场景 | 超大规模数据处理 | 快速业务上线/中小规模应用 |
技术架构对比
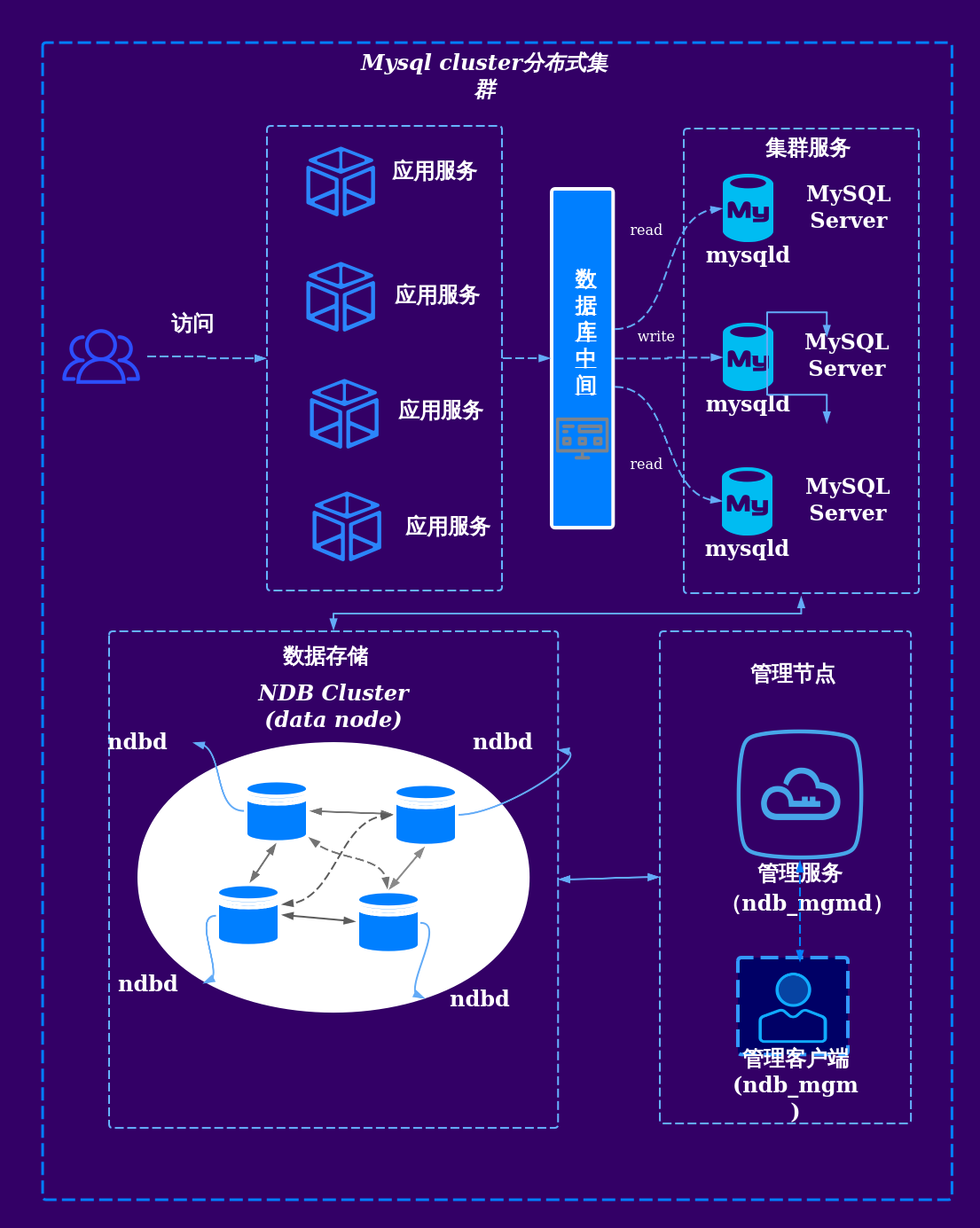
分布式数据库架构
- 数据分片策略:哈希分片(如Redis Cluster)、范围分片(如时间序列数据)、目录分片(如订单系统按商户分片)
- 一致性保障:
- Paxos/Raft协议实现强一致性
- 最终一致性模型(如DynamoDB)
- 事务处理:
- 两阶段提交(2PC)协议
- TCC(Try-Confirm-Cancel)模型
- 基于时间戳的多版本控制(MVCC)
云数据库架构

- 计算存储分离:独立扩展计算节点与存储节点
- Serverless架构:自动休眠空闲实例(如AWS Aurora Serverless)
- 多可用区部署:跨AZ冗余保障SLA(如阿里云RDS)
- 智能调优:基于AI的索引推荐(如Azure SQL Database)
关键技术差异
| 技术维度 | 分布式数据库 | 云数据库 |
|---|---|---|
| 数据冗余 | 自定义副本策略 | 自动三副本+跨可用区同步 |
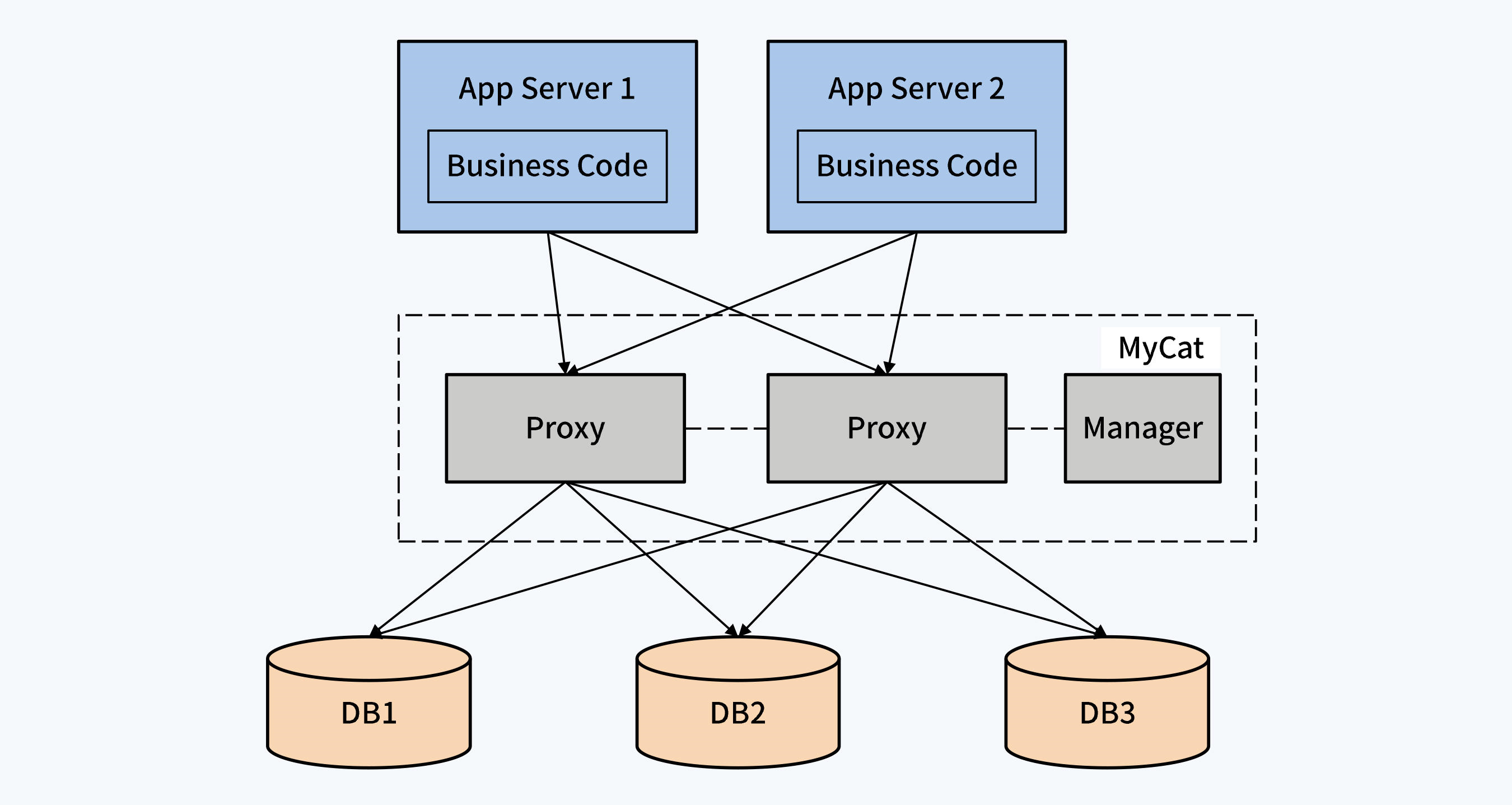
| 负载均衡 | 需配置中间件(如MyCAT) | 内置负载均衡(如PolarDB) |
| 安全机制 | 自建SSL/Kerberos | 集成云原生安全体系 |
| 监控体系 | Prometheus+Grafana自建 | 提供完整监控面板 |
| 备份恢复 | 定制备份脚本 | 一键PITR/跨区域备份 |
典型应用场景
分布式数据库适用场景
- 超大规模数据处理(如万亿级日志分析)
- 高并发写入场景(如双十一订单系统)
- 混合负载场景(OLTP+OLAP混合)
- 边缘计算场景(如CDN节点数据存储)
云数据库适用场景
- 初创企业快速业务验证
- 临时性业务需求(如大促活动)
- 多地域部署需求(全球业务)
- DevOps持续集成环境
- 传统数据库迁移上云
技术挑战对比
分布式数据库主要挑战:
- CAP定理权衡:在分区容忍性下保证CP或AP
- 全局事务管理:跨节点事务的延迟与成功率矛盾
- 数据倾斜处理:热点数据导致的节点负载不均
- 运维复杂度:数百节点集群的监控与调优
云数据库特殊挑战:
- 多租户隔离:资源争抢与数据泄露防护
- 弹性极限测试:秒级扩容对连接池的冲击
- 冷启动优化:新实例的快速初始化
- 跨云兼容性:避免厂商锁定的标准化接口
演进趋势分析
技术融合方向:
- 云原生分布式数据库(如TiDB Cloud)
- 存算分离架构普及化
- Serverless与流式计算结合
- AI驱动的自治数据库
市场发展预测:
- 2025年全球云数据库市场规模将达1200亿美元(Gartner数据)
- 混合云部署需求增长300%(IDC预测)
- 分布式事务处理性能年提升率超40%
FAQs
Q1:如何判断业务应该选择分布式数据库还是云数据库?
A:决策需考虑三个维度:
- 数据规模:日均TB级以上建议分布式,GB级以下可优先云数据库
- 团队能力:具备10人以上DBA团队可选自建分布式,中小团队建议云服务
- 合规要求:金融级监管场景需自主可控架构,普通业务可使用云数据库
Q2:云数据库是否完全替代传统分布式数据库?
A:两者是互补而非替代关系:
- 核心差异:云数据库侧重服务化体验,分布式数据库强调技术可控性
- 共存场景:大型企业常采用”云数据库+本地分布式数据库”混合架构
- 选型关键:根据业务发展阶段选择,初期用云数据库试错,成熟期