上一篇
分布式数据库试卷计算机分布在多个不同的站点上的计算机网络系统
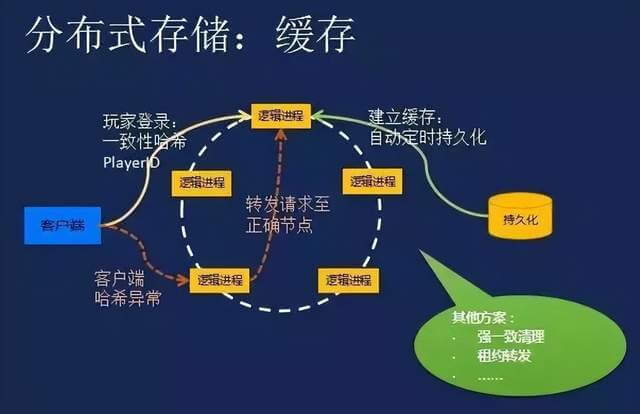
分布式数据库是将数据分布存储于多个站点的计算机网络系统,各站点协同处理,具备数据冗余、高可用
分布式数据库系统的核心特征与架构解析
分布式数据库系统(Distributed Database System, DDBMS)是一种将数据存储和管理功能分散到多个物理节点上的数据库系统,这些节点通常位于不同的地理区域,通过计算机网络连接形成统一的整体,与传统集中式数据库相比,分布式数据库在数据冗余、容错性、扩展性等方面具有显著优势,但其复杂性也更高,以下从系统特征、架构设计、关键技术及应用场景四个维度展开分析。
分布式数据库的核心特征
| 特征 | 描述 |
|---|---|
| 数据分布性 | 数据按分片规则存储在多个站点,每个站点可独立处理本地数据 |
| 场地透明性 | 用户无需感知数据物理位置,SQL查询可跨站点执行 |
| 冗余与容错 | 通过数据复制实现高可用性,单点故障不影响全局服务 |
| 自治性 | 各站点可独立管理本地数据库,支持异构硬件/软件环境 |
| 动态扩展性 | 支持在线增减节点,水平扩展能力显著 |
典型场景:跨国企业全球业务数据管理、大型电商平台订单分库、金融系统灾备架构等。
分布式数据库系统架构
客户端层
提供统一访问接口(如JDBC/ODBC),支持SQL语句解析与优化,隐藏底层分布式细节。分布式管理层
- 全局事务管理器:协调跨站点事务(如两阶段提交协议)
- 目录服务:维护全局数据字典,记录分片策略与节点状态
- 查询优化器:生成分布式执行计划(如基于代价的优化模型)
局部数据库管理层
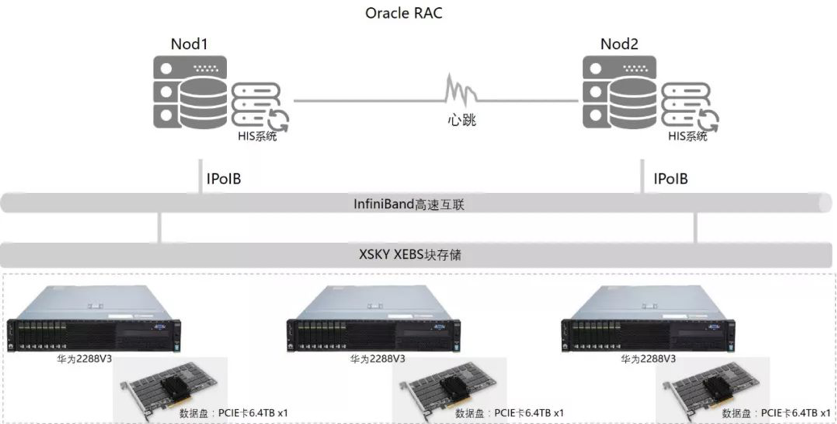
各站点独立运行DBMS(如MySQL/PostgreSQL),负责本地数据操作与缓存。
底层网络层
依赖RPC框架(如gRPC)、消息队列(如Kafka)实现节点间通信,需处理网络分区与延迟问题。
关键技术实现
数据分片(Sharding)
- 水平分片:按行划分数据,如哈希分片(
user_id % N)或范围分片(按时间区间) - 垂直分片:按列划分,将不同属性存储在不同节点(如订单表拆分为商品信息与支付信息)
- 混合分片:结合水平与垂直分片,适用于复杂业务场景
示例:电商订单库按用户ID哈希分片至4个节点,每个节点存储全量订单的25%。
- 水平分片:按行划分数据,如哈希分片(
事务管理
- 两阶段提交(2PC):协调者发送预备/提交指令,解决分布式原子性问题
- 三阶段提交(3PC):增加预提交阶段,减少阻塞概率
- BASE理论:通过牺牲强一致性(如最终一致性)提升性能
数据复制技术
- 主从复制:单一写节点(主库),多读节点(从库),适合读多写少场景
- 多主复制:允许多个节点并发写入,需解决冲突(如版本向量算法)
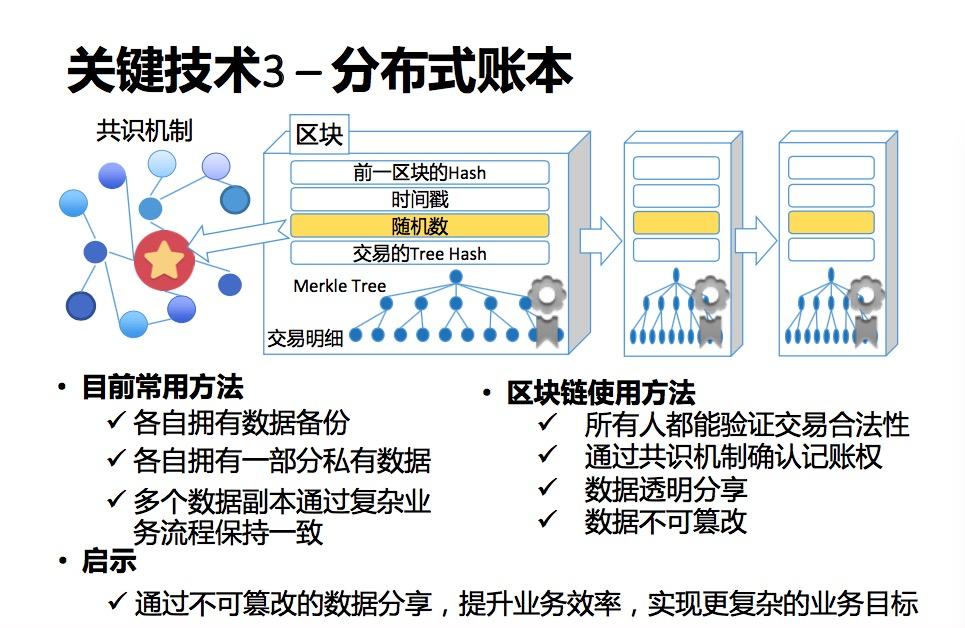
- Paxos/Raft协议:用于共识决策,保证复制一致性
一致性协议
- CAP定理权衡:在网络分区时需选择一致性(C)或可用性(A)
- 强一致性:通过分布式锁或事务协议实现(如Google Spanner的TrueTime)
- 弱一致性:采用事件溯源或CRDT(冲突自由复制数据类型)降低延迟
查询优化
- 代价模型:评估不同执行计划的I/O、网络开销
- 数据本地性优先:尽可能在单个节点完成计算(如MapReduce思想)
- 半连接优化:先过滤后传输数据,减少网络带宽消耗
典型应用场景与挑战
| 场景 | 技术需求 |
|---|---|
| 跨国银行交易系统 | 低延迟强一致性、多活节点、监管合规数据隔离 |
| 社交媒体实时推荐 | 高吞吐量读写、最终一致性、分片键设计(如用户ID) |
| 物联网设备数据管理 | 边缘计算与中心协同、数据压缩传输、海量小文件处理 |
| 在线教育平台 | 弹性扩缩容、读写分离、冷热数据分层存储 |
主要挑战:
- 网络延迟与分区:跨地域部署时需设计超时重试机制
- 数据倾斜:热点分片可能导致部分节点过载
- 故障恢复:需自动化故障检测与数据重建流程
- 安全与隐私:跨站点数据传输加密与访问控制策略
FAQs
Q1:如何选择合适的数据分片策略?
A1:需根据业务访问模式决定:
- 哈希分片:适合均匀分布的数据(如用户ID)
- 范围分片:适合时间序列或地理位置相关数据
- 目录分片:按业务维度(如部门/地区)独立存储
建议组合多种策略,并通过模拟测试验证分片效果。
Q2:分布式事务与单机事务的核心区别是什么?
A2:
- 锁粒度:分布式事务需跨节点锁定资源,易引发死锁
- 协调成本:需额外通信开销(如2PC的预备/提交阶段)
- 失败恢复:单机回滚可本地完成,分布式需补偿机制
- 性能优化:常采用异步提交