上一篇
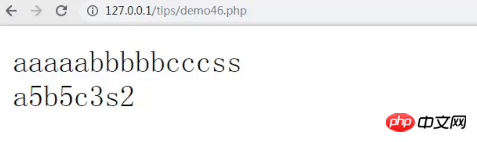
按键怎么做到文字识别
按键通过硬件电路触发扫描码,操作系统结合键盘布局将扫描码转换为对应字符,再经输入法处理
按键实现文字识别的原理与流程
核心原理
文字识别(OCR)的本质是将图像中的文字转换为可编辑的文本,按键作为触发装置,主要负责启动以下流程:
- 图像采集:通过摄像头或扫描仪获取文字图像
- 预处理:去噪、灰度化、二值化等图像优化
- 文字检测:定位文字区域(如CTPN算法)
- 字符识别:基于CNN/Transformer模型识别文字(如CRNN+Attention)
- 后处理:校正错别字、格式还原
硬件实现方案
| 组件 | 功能说明 | 典型型号 |
|---|---|---|
| 微控制器 | 协调各模块工作 | STM32F4 |
| 图像传感器 | 采集文字图像 | OV7670摄像头模块 |
| 存储芯片 | 缓存图像数据 | W25Q64FV |
| 按键电路 | 触发识别操作 | 机械按键/电容触控 |
| 通信模块 | 传输识别结果 | ESP8266 WiFi |
软件实现流程
# 伪代码示例(基于Python+Tesseract)
import pytesseract
from PIL import Image
import RPi.GPIO as GPIO
# 初始化GPIO
GPIO.setmode(GPIO.BCM)
GPIO.setup(17, GPIO.IN, pull_up_down=GPIO.PUD_UP)
def capture_image():
# 控制摄像头拍照
camera.capture('temp.jpg')
return Image.open('temp.jpg')
def ocr_process(image):
# 预处理图像
processed = image.convert('L').point(lambda x: x > 140 and 255)
# 执行OCR
text = pytesseract.image_to_string(processed, lang='chi_sim')
return text
def button_callback(channel):
image = capture_image()
text = ocr_process(image)
print("识别结果:", text)
# 设置按键中断
GPIO.add_event_detect(17, GPIO.FALLING, callback=button_callback)
while True:
time.sleep(1)关键优化技术
图像增强:

- 自适应直方图均衡(CLAHE)
- 透视变换矫正倾斜
- 形态学处理去除干扰线
模型优化:
- 使用轻量级模型(如MobileNet-CRNN)
- 量化压缩模型体积
- FP16半精度推理加速
按键交互设计:
- 长按触发连续扫描模式
- 双击切换多语言识别
- LED指示灯反馈工作状态
常见问题解决方案
| 问题现象 | 解决方案 |
|---|---|
| 低光照环境识别差 | 启用自动曝光补偿,增加红外补光模块 |
| 中文识别率低 | 使用专项训练的中文模型(如PaddleOCR中文库),添加自定义词典 |
| 处理速度慢 | 采用GPU加速(如NVIDIA Jetson),模型剪枝优化 |
| 按键误触发 | 增加去抖电路,软件端设置触发阈值 |
相关问题与解答
Q1:如何提升复杂背景下的文字识别准确率?
A1:可采用以下策略:
- 使用深度学习语义分割模型(如DeepLabv3)分离文字与背景
- 引入注意力机制增强特征提取能力
- 建立场景专用数据集进行迁移学习
- 结合空间几何特征进行后处理校正
Q2:按键式OCR设备如何实现多语言支持?
A2:实现方案包括:
- 集成多语言OCR引擎(如Tesseract支持100+语言)
- 设计语言切换物理按键
- 通过LED/屏幕显示当前识别语言
- 使用Unicode编码统一输出格式
- 加载