上一篇
分布式数据存储np
分布式数据存储通过数据分片、冗余备份及一致性协议实现高可用与扩展性,支持动态扩容
原理、架构与实践
核心概念与特性
分布式数据存储是一种通过多台服务器协同工作来存储和管理数据的架构,其核心目标是解决传统集中式存储在容量、性能和可靠性方面的瓶颈,与传统单机存储相比,分布式存储具备以下关键特性:
| 特性 | 传统存储 | 分布式存储 |
|---|---|---|
| 扩展性 | 垂直扩展(硬件升级) | 水平扩展(增加节点) |
| 容错性 | 单点故障导致服务中断 | 自动冗余,节点故障无感知 |
| 性能瓶颈 | 依赖单点硬件性能 | 负载分散,并行处理 |
| 数据一致性 | 强一致性(单一来源) | 最终一致性(需权衡) |
典型架构设计
主从复制架构
- 核心节点(Master)负责协调,从节点(Slave)同步数据
- 适用场景:读写分离、低延迟读需求
- 代表系统:MySQL Cluster、Redis Sentinel
对等式无中心架构
- 所有节点地位平等,通过算法协商数据分布
- 优势:无单点故障,扩展性强
- 代表系统:Cassandra、Riak
分层混合架构
- 热数据:内存缓存(如Redis)加速访问
- 冷数据:HDD/SSD持久化存储
- 典型应用:对象存储(MinIO)、大数据平台
核心技术解析
数据分片(Sharding)

- 哈希分片:按Key哈希值均匀分布(如MongoDB)
- 范围分片:按时间/ID区间划分(如Elasticsearch)
- 虚拟分片:二次映射优化负载均衡
数据复制机制
- 同步复制:强一致性但延迟高(如QPSF <10万)
- 异步复制:高吞吐量但存在数据丢失风险
- 多数派协议:Raft/Paxos算法实现准实时一致
一致性协议
CAP定理权衡矩阵:
场景 CP优先(金融交易) AP优先(社交媒体) BP优先(日志系统) 典型系统 ZooKeeper Cassandra Kafka 一致性等级 强一致性(2PC) 最终一致性(Quorum) 顺序一致性
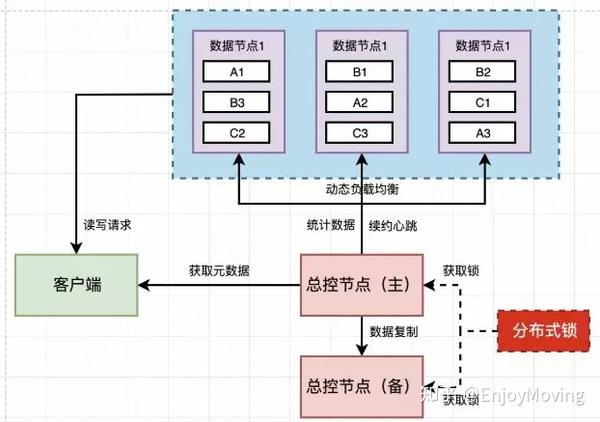
元数据管理
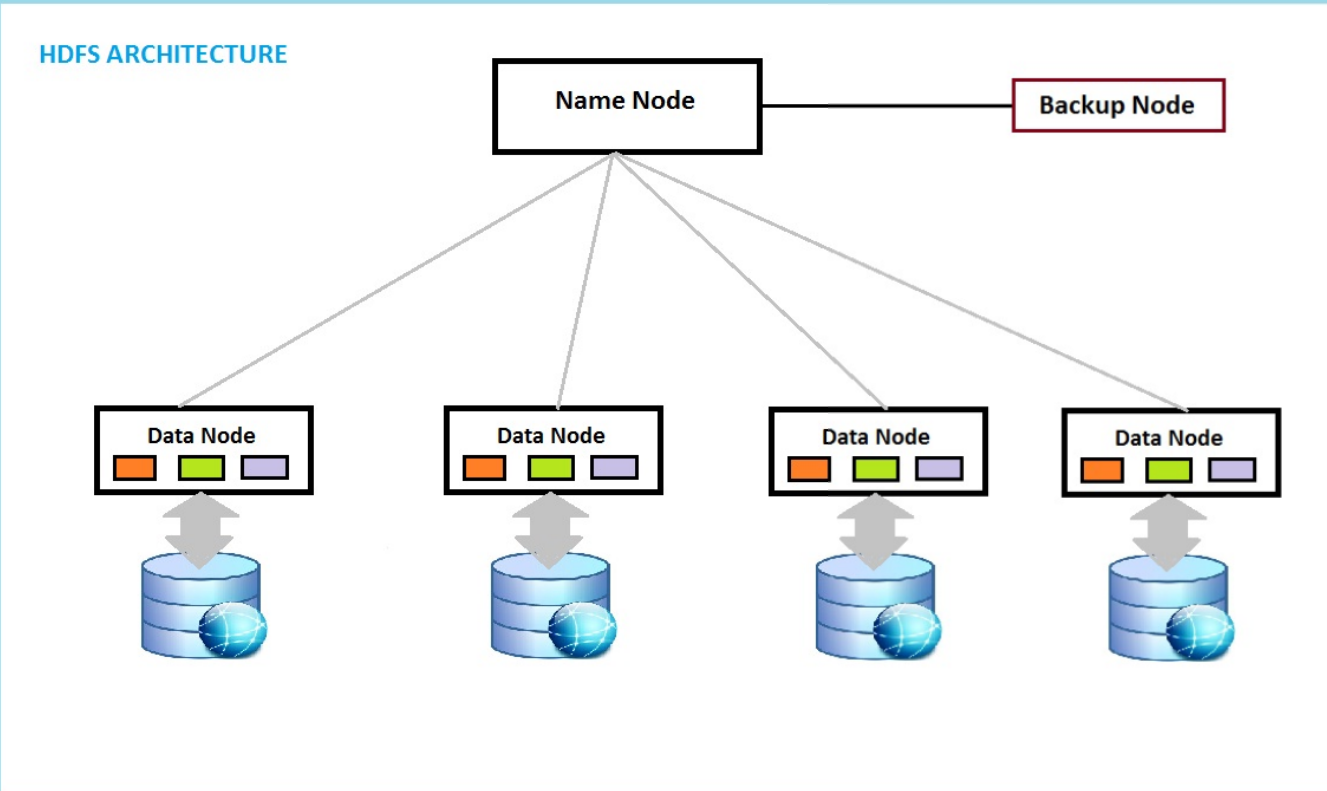
- 集中式目录(如Hadoop NameNode)
- 去中心化路由(如Chord算法)
- 混合模式:分片元数据+心跳检测
应用场景与选型建议
| 业务类型 | 关键需求 | 推荐方案 | 典型案例 |
|---|---|---|---|
| 高并发读写 | 低延迟、高吞吐 | Redis Cluster + Cassandra | 电商瞬秒系统 |
| 海量日志处理 | 顺序写入、持久化 | Kafka + HDFS | 工业互联网数据采集 |
| 实时数据分析 | 亚秒级响应 | ClickHouse + Apache Druid | 金融风控系统 |
挑战与优化策略
数据倾斜问题
- 现象:热点Key导致部分节点过载
- 解决方案:
- 虚拟节点(Ring Hash)
- 动态分片调整(如Monkey分片策略)
- 客户端侧请求路由优化
网络分区处理
- 脑裂问题:使用心跳超时+多数派仲裁
- 跨数据中心部署:优先本地读写,异步同步
存储成本控制
- 冷热数据分层:LRU淘汰策略+SSD缓存
- 压缩算法:LZ4(CPU友好) vs ZSTD(平衡型)
- 纠删码:Reed-Solomon编码降低冗余率至1.25x
性能指标对比
| 指标 | 单机MySQL | MongoDB Sharding | TiDB(NewSQL) | Ceph RGW |
|---|---|---|---|---|
| 最大存储容量 | TB级(受限硬件) | PB级(线性扩展) | EB级(分布式元数据) | ZB级(对象存储) |
| 写入吞吐量 | 1万QPS | 10万QPS | 50万QPS | 100万OPS |
| 强一致性延迟 | <10ms | 50-200ms | <30ms | N/A(最终一致) |
| 扩展复杂度 | 高(停机迁移) | 中(自动分片) | 低(在线扩容) | 高(CRUSH地图配置) |
FAQs
Q1:如何选择CP还是AP系统?
A:核心取决于业务容忍度:
- 选CP:金融交易、订单系统等强依赖数据准确性的场景,可接受短暂服务降级
- 选AP:社交feed、日志收集等允许数据短暂不一致的场景,需保证持续可用性
- 折中方案:采用Base理论,通过版本向量(Vector Clocks)实现冲突检测
Q2:分布式存储是否需要TCC事务?
A:多数场景采用最终一致性即可满足需求,但以下情况需强化事务支持:
- 跨分片更新:使用2PC或TCC补偿机制(如Seata框架)
- 金融级审计:引入全局事务ID(如Google Spanner的TrueTime)
- 混合负载:NewSQL系统(如CockroachDB)通过MV